
常見排序演算法及JAVA實現
排序演算法的分類
先看維基百科中的一張關於排序演算法的表

我們主要了解常見的一些排序演算法。像Bogo排序,臭皮匠排序這類完全不實用的排序可以置之不理。
我們這裡要說的排序演算法都是內排序,也就是隻在記憶體中進行,涉及到對磁碟等外部儲存裝置中的資料進行排序稱之為外排序,關於外排序的內容可以檢視維基百科。
簡單選擇排序(SelectSort)
選擇排序思想很簡單,對所有元素進行遍歷,選出最小(或最大)的元素與第一個元素進行交換,然後逐次縮小遍歷的範圍。
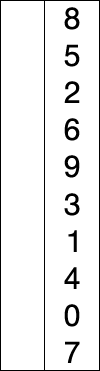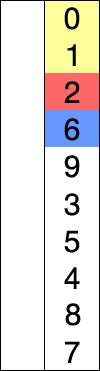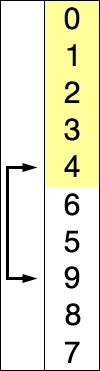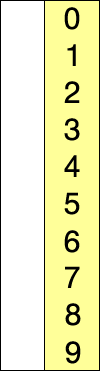
關於八大排序演算法的動態圖,這裡有一個網站我覺得特別好。
Java實現
import org.junit.Test;
public 執行結果
排序前:[3, 6, 2, 5, 9, 0, 1, 7, 4, 8]
排序後:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]進階版選擇排序—-堆排序(HeapSort)
堆排序就是對上面的選擇排序進行了優化。從上面的簡單選擇排序實現中,我們可以看出,內部的迴圈負責比較選出最小值,然後進行一次交換。也就是說迴圈n次最後只選了個最小值和最前面的進行交換,前面的迴圈比較得出來的結果就這樣拋棄了。舉個很簡單的例子“8, 9, 4, 6”這個無序的陣列,第一次迴圈中已經得到8 < 9和8 > 6這個結論,第二次迴圈又將9和6進行比較,很明顯第一次迴圈已經可以得出了9>6這個結論了,9和6比較完全是浪費的,但是簡單選擇就是這麼傻逼無腦,那有沒有一種方法讓前面迴圈進行比較得到的結果能儲存起來。這就涉及到一個概念了—–二叉堆。
二叉堆聽起來很牛逼的樣子,其實說白了就是一個完全二叉樹。完全二叉樹是什麼?就是去掉滿二叉樹後面若干個葉子結點,看下圖:
樹有很多特性,我們可以利用其層次性,讓較小的元素下沉,較大的元素往上排。
二叉堆就是滿足對於任意的子樹都有父節點大於其子孫結點,於是最大的元素就到樹頂的根節點了,這種堆就叫做大頂堆;相反小元素往上排,那就叫小頂堆了。因為二叉堆是完全二叉樹,而且我們已經知道二叉堆最大的元素個數就是我們要排序的元素個數,我們的二叉堆可以就地取材直接用陣列實現,所以堆排序不需要重新分配記憶體,空間複雜度為O(1),記得大一看“堆排序”這個名字老以為要多分配一份記憶體。
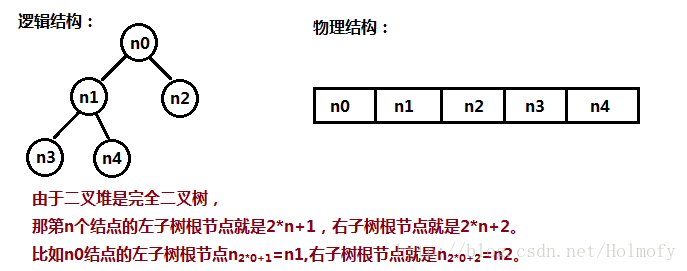
看上圖的時候需要注意,這裡的索引是從0開始的,和我們常用的從1開始編號得到的結論可能不同:
- 索引值為n的左結點索引值為2*n+1,右結點索引值為2*n+2;
- 索引值為n的父節點索引值為(n-1)/2,這裡的“/”是整型變數相除得到的結果也是整型變數(學計算機的都懂^_^)。
- 結點數為size的完全二叉樹非葉子結點數目為size/2,所以最後的那個非葉子結點的索引應該為size/2-1(因為從0開始,所以要減一)
- 結點數為size的完全二叉樹葉子結點數目為size/2或size/2+1,這個結論在具體實現的時候用不到
下面這張Gif圖完美地呈現了堆排序的過程:用大頂堆選出最大的,然後與最後項交換。

看圖容易實現難吶,難點主要在兩個地方:
1. 怎麼將無序的陣列構造成二叉堆。
2. 將堆頂最大值與最後項交換後,如何再次調整二叉堆。
JAVA實現
import org.junit.Test;
public class HeapSort implements SortAlgorithm {
public <TYPE extends Comparable<? super TYPE>> void sort(TYPE[] items) {
// 構造二叉堆
// 從最末端也就是最下面的非葉子結點開始進行調整
// 從而使得最大值上移到二叉堆頂端
for (int i = items.length / 2 - 1; i >= 0; i--) {
adjust(items, i, items.length);
}
for (int i = items.length - 1; i > 0; i--) {
// 將最大值與最後項進行交換
TYPE temp = items[0];
items[0] = items[i];
items[i] = temp;
// 取出最大值之後,重新調整二叉堆
// 二叉堆也隨著變數i慢慢縮小
adjust(items, 0, i);
}
}
private <TYPE extends Comparable<? super TYPE>> void adjust(TYPE[] items, int index, int heapSize) {
int leftChild = 2 * index + 1;
int rightChild = 2 * index + 2;
// 在三個結點中選出最大的結點
int indexOfMax = index;
if (leftChild < heapSize) {// 左子樹存在性檢驗
if (items[leftChild].compareTo(items[indexOfMax]) > 0) {
indexOfMax = leftChild;
}
}
if (rightChild < heapSize) {// 右子樹存在性檢驗
if (items[rightChild].compareTo(items[indexOfMax]) > 0) {
indexOfMax = rightChild;
}
}
if (indexOfMax != index) {
// 將較大值上移
TYPE temp = items[index];
items[index] = items[indexOfMax];
items[indexOfMax] = temp;
// 千萬別漏了這個等號,我除錯了半天才發現這個錯誤
if (indexOfMax <= heapSize / 2 - 1) {
// 如果被調整後的結點也是非葉子結點
// 需要對該子樹進行調整
adjust(items, indexOfMax, heapSize);
}
}
}
// 測試程式碼
private final Integer[] testItems = { 3, 6, 2, 5, 9, 0, 1, 7, 4, 8 };
@Test
public void testHeapSort() {
System.out.print("排序前:");
System.out.println(Arrays.toString(testItems));
sort(testItems);
System.out.print("\n排序後:");
System.out.println(Arrays.toString(testItems));
}
}有一個“平滑排序”演算法和堆排序有點類似,“平滑排序”使用的是另一種二叉樹—-Leonardo樹。關於“平滑排序”的各種說明,這裡有篇文章可供參考。
簡單插入排序(InsertSort)
插入排序原理也很簡單,和整理撲克牌有點像。

在未排序的部分選擇一個元素,插入到已排序的部分,插入時會將比這個值大的所有元素往後擠。下面有動態圖,看的很清楚。
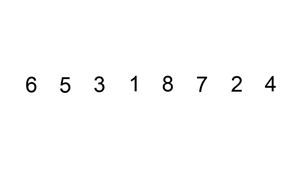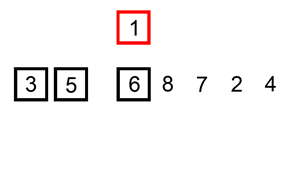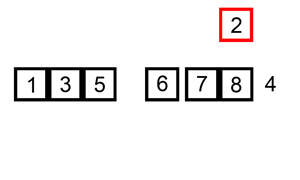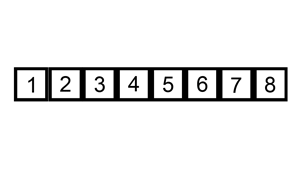
JAVA實現
import org.junit.Test;
public class InsertSort implements SortAlgorithm {
public <TYPE extends Comparable<? super TYPE>> void sort(TYPE[] items) {
for (int i = 1; i < items.length; i++) {
TYPE current = items[i];
int j = i - 1;
do {
if (current.compareTo(items[j]) < 0) {
items[j + 1] = items[j];// 後移
} else {
break;
}
j--;
} while (j >= 0);
items[j + 1] = current; // 插入
}
}
// 測試程式碼
private final Integer[] testItems = { 3, 6, 2, 5, 9, 0, 1, 7, 4, 8 };
@Test
public void testInsertSort() {
System.out.print("排序前:");
System.out.println(Arrays.toString(testItems));
sort(testItems);
System.out.print("\n排序後:");
System.out.println(Arrays.toString(testItems));
}
}進階版插入排序—-希爾排序(ShellSort)
希爾排序也稱縮小增量排序,是直接插入排序演算法的一種更高效的改進版本。希爾排序這名字可能不好理解,因為這是設計者的名字,但是提到“縮小增量排序”這個名字,可能你就已經理解一小半了。
既然說插入排序不是最高效的,那我們來想想怎麼能將其進行優化吧。從上面的程式碼可以看出內層的迴圈是負責為current找到插入的位置,這是在有序的陣列中查詢位置,我第一個想到的就是二分查詢(可能是對二分查詢太敏感),但是細想之後,你會發現即使你找到那個插入點,但是你還是得將插入點後面的元素往後移動騰出個空位,這始終避免不了上面實現程式碼的內層迴圈操作。
維基百科中是這樣概括插入排序的:
- 插入排序在對幾乎已經排好序的資料操作時,效率高,即可以達到線性排序的效率
- 但插入排序一般來說是低效的,因為插入排序每次只能將資料移動一位
於是呢,“希爾”大神發明了一種演算法,讓插入排序移動的步伐變大,元素可以一次性朝最終目標前進一大步,從而避免了大量的資料移動。希爾排序圖片不好找,下面的圖片湊合著看吧:
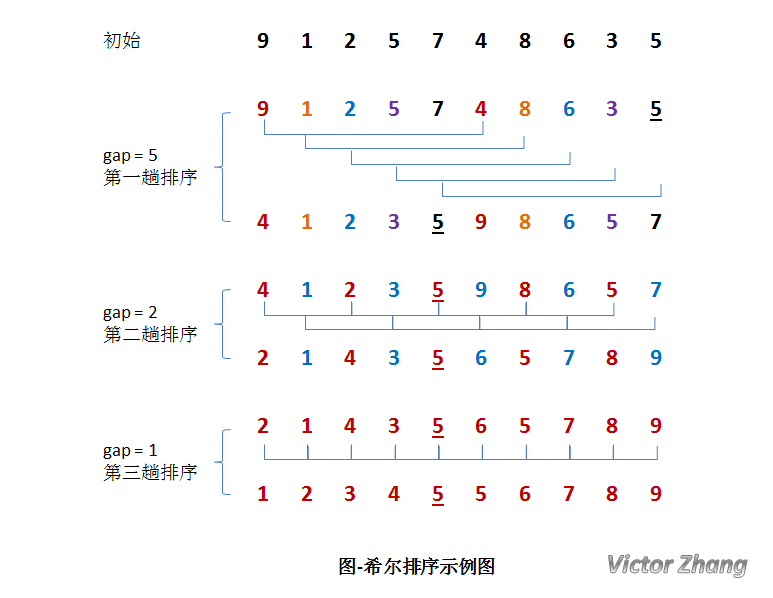
步長的選擇是希爾排序的重要部分。只要最終步長為1任何步長序列都可以工作。演算法最開始以一定的步長進行排序。然後會繼續以一定步長進行排序,最終演算法以步長為1進行排序。當步長為1時,演算法變為插入排序,這就保證了資料一定會被排序。
Donald Shell最初建議步長選擇為 n/2 ,並且對步長取半直到步長達到1。雖然這樣取可以比 O(n*n) 類的演算法(插入排序)更好,但這樣仍然有減少平均時間和最差時間的餘地。可能希爾排序最重要的地方在於當用較小步長排序後,以前用的較大步長仍然是有序的。比如,如果一個數列以步長5進行了排序然後再以步長3進行排序,那麼該數列不僅是以步長3有序,而且是以步長5有序。如果不是這樣,那麼演算法在迭代過程中會打亂以前的順序,那就不會以如此短的時間完成排序了。—-摘自維基百科
從維基百科的解釋可以看出步長序列的選擇是希爾排序的關鍵,一般來說我們選擇的初始步長都為n/2,然後依次取半,直至為1,而且最終步長為1後才能終止,否則序列中某些元素仍是亂序。下面的JAVA實現中的步長就是依據以此。
維基百科中也提到了一些特殊步長序列,這些步長序列經過精心設計,而且使用這些精心設計的步長序列,排序速度會得到提升,詳細可參考維基百科
JAVA實現
import org.junit.Test;
public class ShellSort implements SortAlgorithm {
public <TYPE extends Comparable<? super TYPE>> void sort(TYPE[] items) {
for (int step = items.length / 2; step > 0; step /= 2) {
// 內層其實就是一個步長為step的插入排序
for (int i = step; i < items.length; i++) {
TYPE current = items[i];
int j = i - step;
do {
if (current.compareTo(items[j]) < 0) {
items[j + step] = items[j];// 後移
} else {
break;
}
j -= step;
} while (j >= 0);
items[j + step] = current;// 插入
}
}
}
// 測試程式碼
private final Integer[] testItems = { 3, 6, 2, 5, 9, 0, 1, 7, 4, 8 };
@Test
public void testShellSort() {
System.out.print("排序前:");
System.out.println(Arrays.toString(testItems));
sort(testItems);
System.out.print("\n排序後:");
System.out.println(Arrays.toString(testItems));
}
}氣泡排序(BubbleSort)
冒泡可能是這八大排序中最簡單的。“冒泡”兩字很形象—-大的元素慢慢的浮上去。氣泡排序只對相鄰的兩個元素進行交換。不多說,看圖好理解。
JAVA實現
import org.junit.Test;
public class BubbleSort implements SortAlgorithm {
public <TYPE extends Comparable<? super TYPE>> void sort(TYPE[] items) {
for (int i = 0; i < items.length; i++) {
for (int j = 0; j < items.length - i - 1; j++) {
if (items[j].compareTo(items[j + 1]) > 0) {
TYPE temp = items[j];
items[j] = items[j + 1];
items[j + 1] = temp;
}
}
}
}
// 測試程式碼
private final Integer[] testItems = { 3, 6, 2, 5, 9, 0, 1, 7, 4, 8 };
@Test
public void testBubbleSort() {
System.out.print("排序前:");
System.out.println(Arrays.toString(testItems));
sort(testItems);
System.out.print("\n排序後:");
System.out.println(Arrays.toString(testItems));
}
}氣泡排序的簡單優化
氣泡排序可能是所有排序中最簡單最容易理解的一種,但是也是效率最低的一種:無論原始陣列是否接近有序,它都需要迴圈n(n-1)次,雖然並不是每次迴圈都進行交換,但仍然影響效率。舉個例子,1、2、5、4、6、7,這個序列中基本接近有序,只需進行一次交換即可完成排序,但未優化的氣泡排序則必須迴圈6*7次才完成排序,所以我們可以進行以下優化:
public void sort(int[] items) {
for (int i = 0; i < items.length; i++) {
boolean noswap = true;
for (int j = 0; j < items.length - i - 1; j++) {
if (items[j] > items[j + 1]) {
noswap = false;
int temp = items[j];
items[j] = items[j + 1];
items[j + 1] = temp;
}
}
if (noswap) break;//快速終止
}
}氣泡排序變形版—-雞尾酒排序(CocktailSort)
上面的氣泡排序每次迴圈都是從前到後進行相鄰的比較。而雞尾酒是前後來回地進行交換,有點像調雞尾酒來回攪動,也有人把它叫做“雙向氣泡排序”。雞尾酒排序只是在氣泡排序的基礎上做了些輕微改動,在效率上氣泡排序和雞尾酒排序相差不了多少。
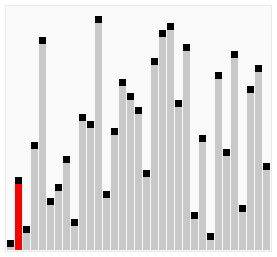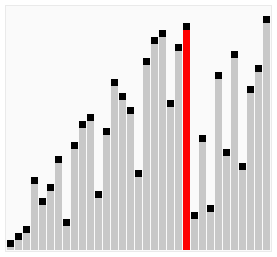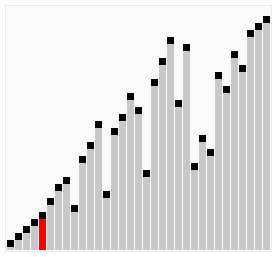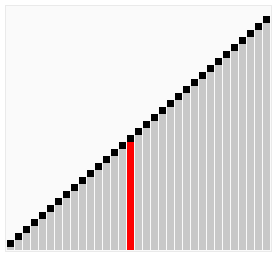
JAVA實現
import org.junit.Test;
public class CocktailSort implements SortAlgorithm {
public <TYPE extends Comparable<? super TYPE>> void sort(TYPE[] items) {
int left = 0, right = items.length - 1;
while (left < right) {
for (int i = left; i < right; i++) {
if (items[i].compareTo(items[i + 1]) > 0) {
TYPE temp = items[i];
items[i] = items[i + 1];
items[i + 1] = temp;
}
}
right--;
for (int i = right; i > left; i--) {
if (items[i - 1].compareTo(items[i]) > 0) {
TYPE temp = items[i];
items[i] = items[i - 1];
items[i - 1] = temp;
}
}
left++;
}
}
// 測試程式碼
private final Integer[] testItems = { 3, 6, 2, 5, 9, 0, 1, 7, 4, 8 };
@Test
public void testCocktailSort() {
System.out.print("排序前:");
System.out.println(Arrays.toString(testItems));
sort(testItems);
System.out.print("\n排序後:");
System.out.println(Arrays.toString(testItems));
}
}快速排序(QuickSort)
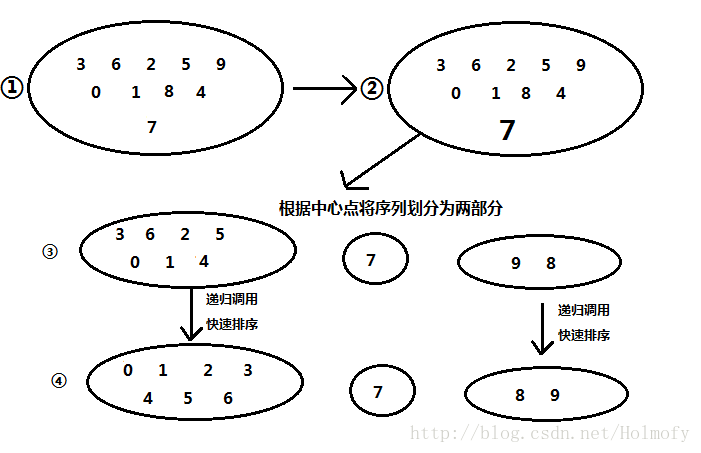
快速排序使用的是分治思想,把原有問題分成兩個子問題進行遞迴解決,步驟如下:
1. 如果待排序的陣列項數為0或1,直接返回。(遞迴出口)
2. 在待排序的陣列中任選一個元素,作為中心點(pivot)
3. 將小於中心點的元素,大於中心點的元素劃分為開來。也就是將小於中心點的元素放在中心點前面,大於中心點的元素放在中心點後面。
4. 對前面小於中心點的元素進行快速排序,對大於中心點的元素進行快速排序
5. 返回前部分的快速排序結果,接上中心點,再跟上後部分的快速排序結果。
畫了個圖,有點醜,湊合湊合看吧
選擇pivot中心點是個很關鍵的問題,常見的做法是:直接使用序列的第一個元素或最後一個元素作為中心點,但是這要解決一個問題:怎麼把小於中心點的元素放到中心元素左邊,大於中心點的元素放到中心點的右邊。
先看一下這張圖,這是我在想實現方法的時候碰到的一種錯誤解決方法,貼在這引以為鑑((^__^) )
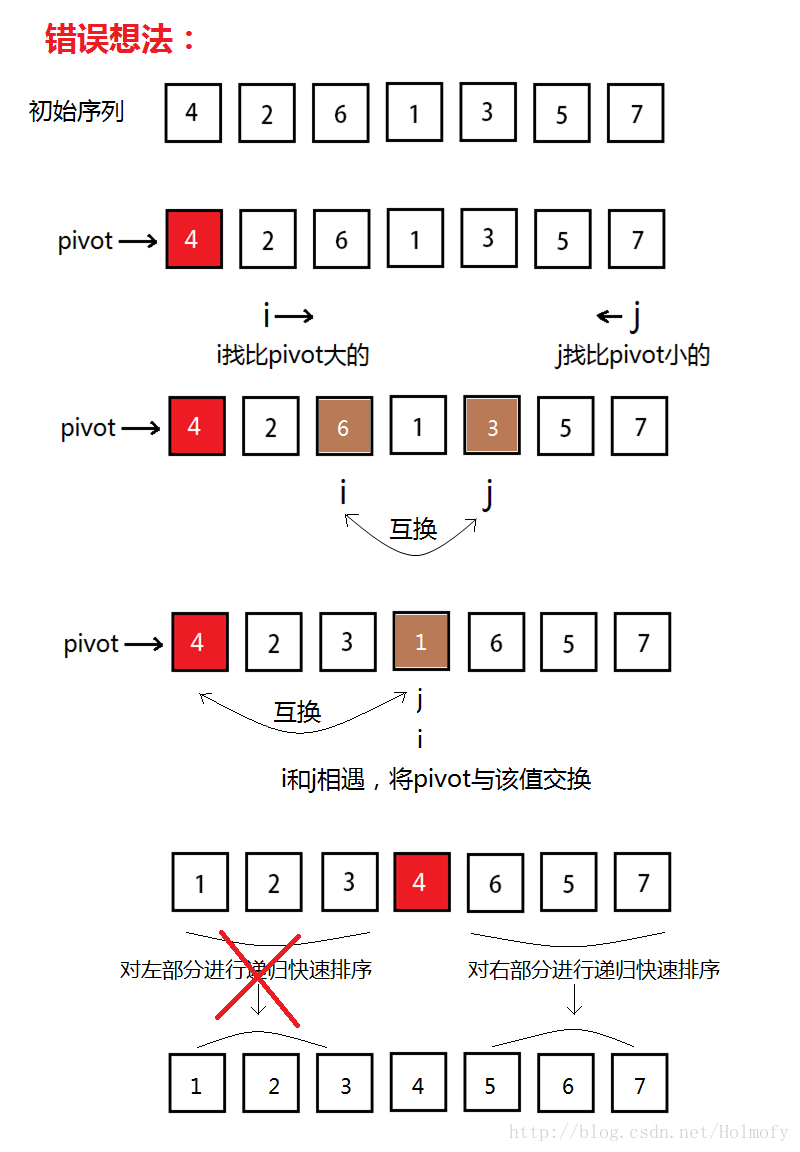
後來細想一遍應該這樣:
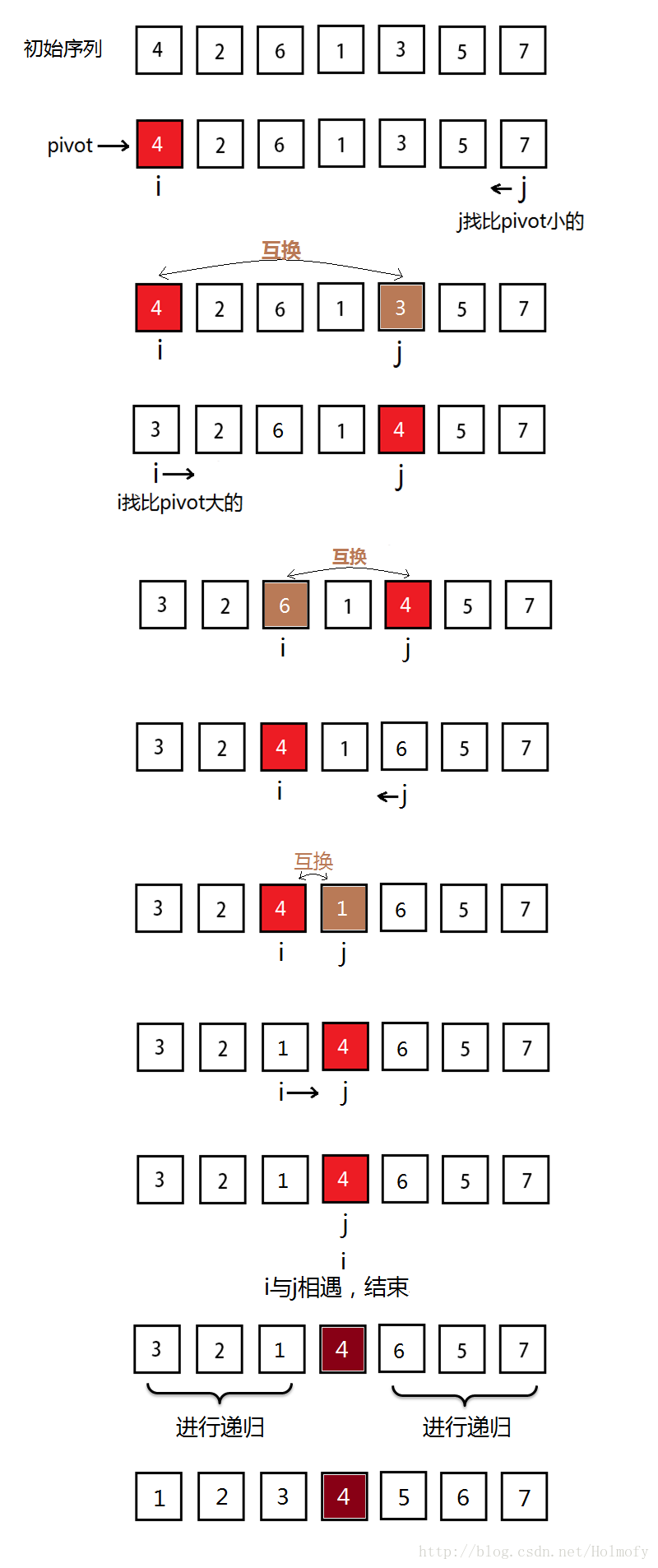
真正寫程式碼的時候才發現,幹嘛要進行互換呢,互換要三條賦值語句,一句賦值多幹淨,覆蓋了它也沒啥事。
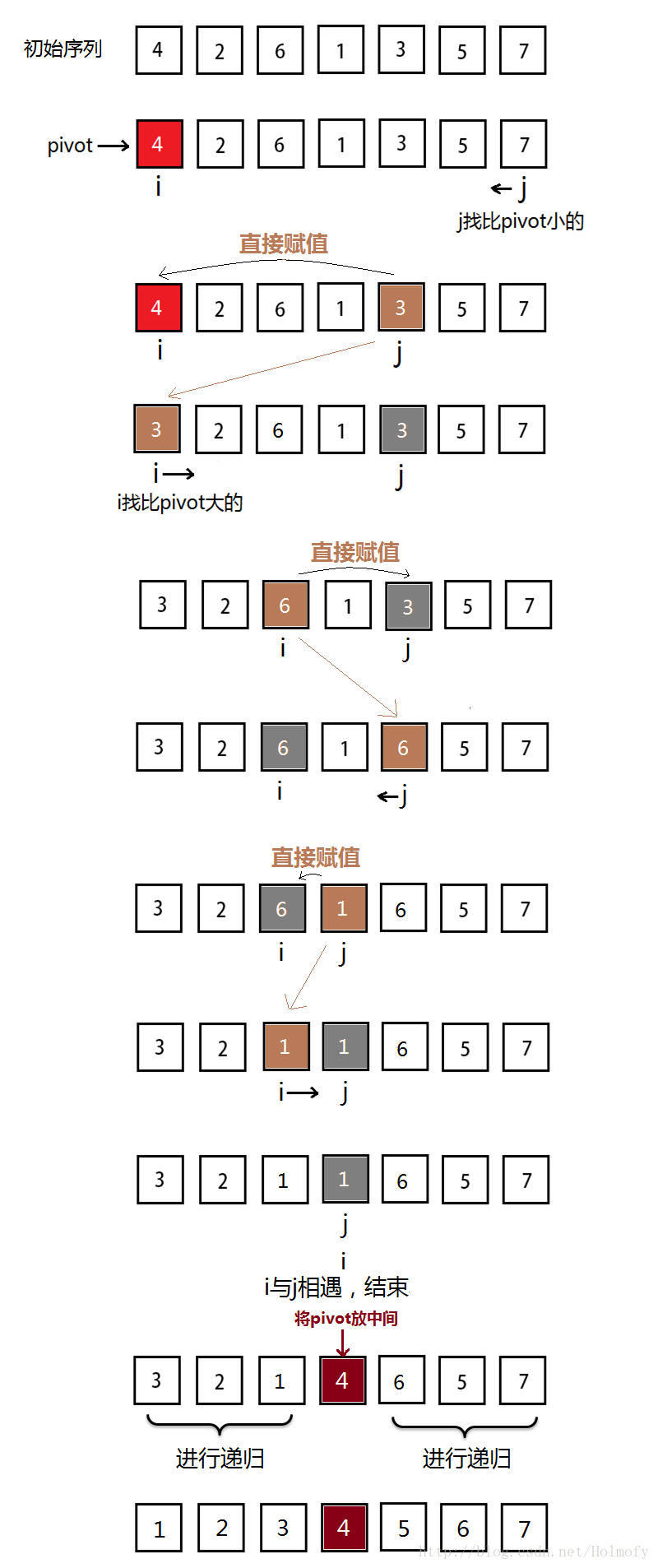
JAVA實現
import org.junit.Test;
public class QuickSort implements SortAlgorithm {
public <TYPE extends Comparable<? super TYPE>> void sort(TYPE[] items) {
quickSort(items, 0, items.length - 1);
}
private <TYPE extends Comparable<? super TYPE>> void quickSort(TYPE[] items, int start, int end) {
if (start < end) {
TYPE pivot = items[start];
int i = start;
int j = end;
while (i < j) {
// 找到一個小於中心點
while (i < j) {
if (items[j].compareTo(pivot) < 0) {
items[i] = items[j];
break;
}
j--;
}
// 找到一個大於中心點
while (i < j) {
if (items[i].compareTo(pivot) > 0) {
items[j] = items[i];
break;
}
i++;
}
}
items[i] = pivot;
quickSort(items, start, i - 1);
quickSort(items, i + 1, end);
}
}
// 測試程式碼
private final Integer[] testItems = { 3, 6, 2, 5, 9, 0, 1, 7, 4, 8 };
@Test
public void testQuickSort() {
System.out.print("排序前:");
for (int i = 0; i < testItems.length; i++) {
testItems[i] = (int) (Math.random() * 100);
}
System.out.println(Arrays.toString(testItems));
sort(testItems);
System.out.print("\n排序後:");
System.out.println(Arrays.toString(testItems));
}
}歸併排序(MergeSort)
歸併排序使用的也是分治思想,不同的是它是直接將序列分為兩個子序列進行遞迴排序。
歸併排序主要分為一下幾個步驟:
1. 如果待排序的序列項數為0或1,直接返回。(遞迴出口)
2. 對等分的兩個部分分別進行遞迴排序。
3. 將排好序的兩部分合併為一個有序陣列。
具體過程看下面的動態圖
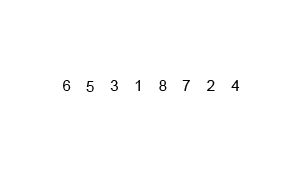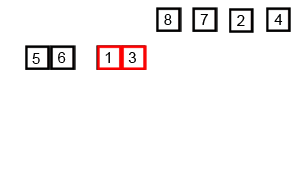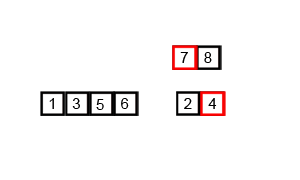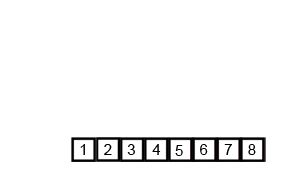
- 歸併排序是外排序的基礎
- 有序陣列進行歸併排序能線上性時間內完成
JAVA實現
import org.junit.Test;
public class MergeSort implements SortAlgorithm {
public <TYPE extends Comparable<? super TYPE>> void sort(TYPE[] items) {
@SuppressWarnings("unchecked")
// 後面遞迴呼叫都使用這個臨時緩衝區。
TYPE[] tmpArray = (TYPE[]) new Comparable[items.length];
mergeSort(items, tmpArray, 0, items.length - 1);
}
private <TYPE extends Comparable<? super TYPE>> void mergeSort(TYPE[] items, TYPE[] tmpArray, int startIndex,
int endIndex) {
if (startIndex < endIndex) {
int centerIndex = (startIndex + endIndex) >> 1;
mergeSort(items, tmpArray, startIndex, centerIndex);
mergeSort(items, tmpArray, centerIndex + 1, endIndex);
merge(items, tmpArray, startIndex, centerIndex, endIndex);
}
}
private <TYPE extends Comparable<? super TYPE>> void merge( // 合併左右序列
TYPE[] items, // 原始陣列
TYPE[] tmpArray, // 臨時陣列,用來合併
int leftPos, // 左序列起始位置
int leftEnd, // 左序列結束位置
int rightEnd // 右序列結束位置
) {
int rightPos = leftEnd + 1; // 右序列的起始位置
int tmpPos = leftPos; // 合併時的臨時索引
int eleCount = rightEnd - leftPos + 1; // 左右序列元素的總數
while (leftPos <= leftEnd && rightPos <= rightEnd) {
if (items[leftPos].compareTo(items[rightPos]) < 0) {
// 左序列的值較小,將左序列元素放入臨時陣列
tmpArray[tmpPos++] = items[leftPos++];
} else {
// 右序列的值較小,將右序列元素放入臨時陣列
tmpArray[tmpPos++] = items[rightPos++];
}
}
// 左序列剩餘元素放入臨時陣列
while (leftPos <= leftEnd) {
tmpArray[tmpPos++] = items[leftPos++];
}
// 右序列剩餘元素放入臨時陣列
while (rightPos <= rightEnd) {
tmpArray[tmpPos++] = items[rightPos++];
}
// 將合併後的資料拷貝回原始陣列
int startIndex = rightEnd - eleCount + 1;
System.arraycopy(tmpArray, startIndex, items, startIndex, eleCount);
}
// 測試程式碼
private final Integer[] testItems = { 3, 6, 2, 5, 9, 0, 1, 7, 4, 8 };
@Test
public void testMergeSort() {
System.out.print("排序前:");
System.out.println(Arrays.toString(testItems));
sort(testItems);
System.out.print("\n排序後:");
System.out.println(Arrays.toString(testItems));
}
}接下來要講的所有排序演算法和上面的排序演算法思想完全不同,沒有交換、選擇,插入等操作,都是使用統計計數來實現的。
注意:由於網上的很多資料與書籍都沒有將計數排序,基數排序,鴿巢排序,桶排序劃分清楚,大多數演算法都只是虛擬碼(圖書館裡找了很多書籍,也在網上查了很多資料,很難找到一個準確的說法,或者是長篇大論,未明所云,或者大篇幅的虛擬碼解釋,無法上機驗證),所以下面的排序演算法名稱和演算法的真正實現原理可能不吻合,如果您對以下演算法有不同的看法,還望指點一二,筆者不勝感激。
計數排序(CountingSort)
因為後面的基數排序是從計數排序優化得到的,所以我們先講講計數排序。計數排序其實是通過統計小於某個值的個數從而確定一個值的存放位置,這樣說可能還不好理解,看看下面的圖吧。
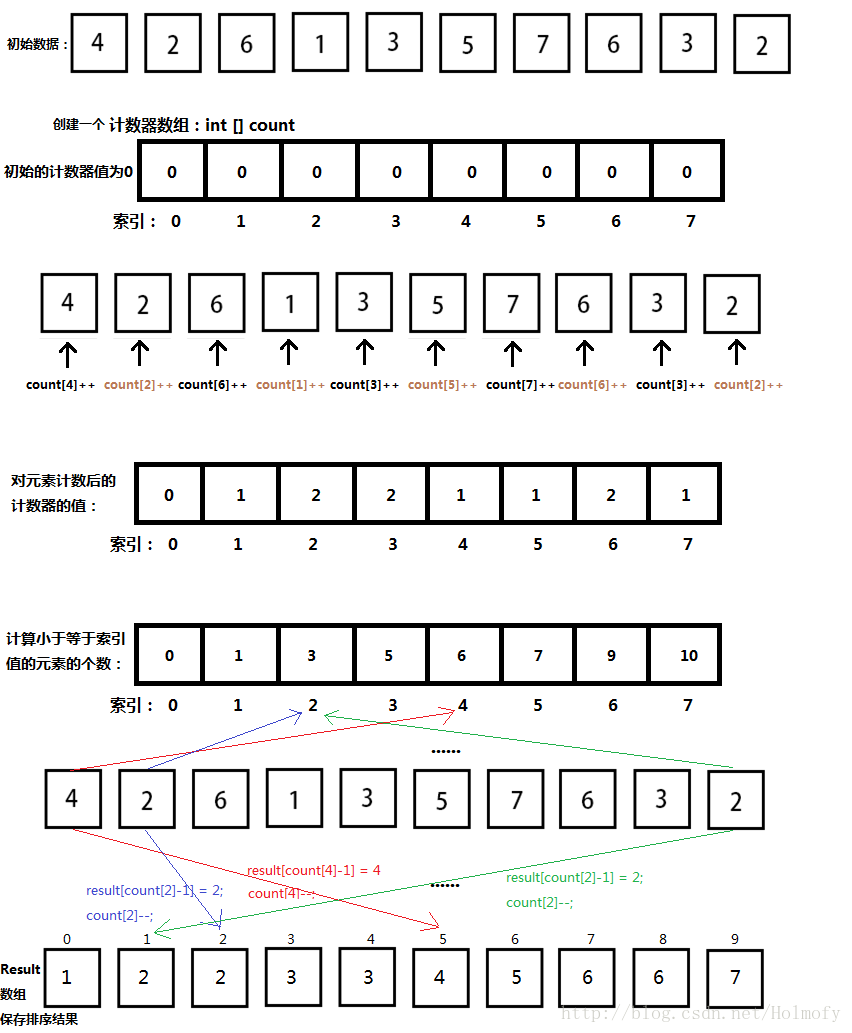
上面的圖可能畫的有點亂,如果還不理解可以看看下面的實現程式碼。
優化前的程式碼
import java.util.Arrays;
import org.junit.Test;
/**
* 簡單計數排序
*
* @author Holmofy
*
*/
public class CountingSort {
public int[] countingSort(int[] items, int max) {
int[] result = new int[items.length];
// 前提是陣列中的資料滿足 item[n]>=0 && item[n]<=k
int k = max + 1;// 索引從0開始
countingSort(items, result, k);
return result;
}
private void countingSort(int[] items, int[] result, int k) {
int[] counter = new int[k];
// 計數
for (int j = 0; j < items.length; j++) {
int a = items[j];
counter[a] += 1;
}
// 求計數和
for (int i = 1; i < k; i++) {
counter[i] = counter[i] + counter[i - 1];
}
// 整理出新序列
// 注意這裡需要從後開始讀取
for (int j = items.length - 1; j >= 0; j--) {
int a = items[j];
result[--counter[a]] = a;
}
}
// 測試程式碼
private final int[] testItems = new int[] { 16, 2, 10, 14, 7, 9, 3, 2, 8, 1 };
@Test
public void testCountSort() {
System.out.println("排序前:" + Arrays.toString(testItems));
System.out.println("排序後:" + Arrays.toString(countingSort(testItems, 16)));
}
}執行結果
排序前:[16, 2, 10, 14, 7, 9, 3, 2, 8, 1]
排序後:[1, 2, 2, 3, 7, 8, 9, 10, 14, 16]原始碼面前了無祕密。
計數排序的優化
事實上,上面實現的計數排序有很大的限制,對於一個未知序列我們無法得知序列中的最大值是多少,從而無法分配合理大小的計數器陣列,而且如果序列的最小值小於0,我們通過索引取計數器時將會發生錯誤。所以我們可以遍歷一遍序列獲取序列最大值和最小值,從而確定計數器陣列大小。看一看優化後的程式碼。
優化後的程式碼
import org.junit.Test;
import java.util.Arrays;
public class CountSort {
public int[] countSort(int[] items) {
int[] result = new int[items.length];
// 遍歷一遍來獲取序列的最大值和最小值
int max = items[0], min = items[0];
for (int i : items) {
if (i > max) {
max = i;
}
if (i < min) {
min = i;
}
}
// 這裡k的大小是要排序的陣列中,元素大小的極值差+1
int k = max - min + 1;
int counter[] = new int[k];
// 計數
for (int i = 0; i < items.length; i++) {
counter[items[i] - min]++;// 優化過的地方,減小了陣列c的大小
}
// 求計數和
for (int i = 1; i < counter.length; i++) {
counter[i] = counter[i] + counter[i - 1];
}
// 整理出新序列
for (int i = items.length - 1; i >= 0; i--) {
int item = items[i];
result[--counter[item - min]] = item;// 按存取的方式取出c的元素
}
return result;
}
// 測試程式碼
private final int[] testItems = new int[] { -1, -3, 16, 2, 10, 14, 7, 9, 3, 2, 8, 1, -4 };
@Test
public void testCountSort() {
System.out.println("排序前:" + Arrays.toString(testItems));
System.out.println("排序後:" + Arrays.toString(countSort(testItems)));
}
}執行結果:
排序前:[-1, -3, 16, 2, 10, 14, 7, 9, 3, 2, 8, 1, -4]
排序後:[-4, -3, -1, 1, 2, 2, 3, 7, 8, 9, 10, 14, 16]上面的計數排序和前面講到的交換,插入的排序相比,還有很多缺點:
- 因為對序列中的資料計數依賴陣列索引,所以計數排序只能用來對整型資料進行排序。
- 空間複雜度較高,儲存結果的Result陣列,以及計數器陣列都需要分配記憶體,而且如果需要排序的資料比較稀疏,計數器陣列會佔用很大的記憶體空間。
計數排序的另一種優化方式—-基數排序(RadixSort)
上面雖然對計數排序進行了優化,但是如果對於資料稀疏的序列進行計數排序,那計數器陣列中將有很多空間會浪費掉。舉個例子,比如說我們有一個序列3,100,10086,404,6,57,2048,對於這樣小的一個序列,如果用計數排序我們最少需要分配10086-3=10083個記憶體長度的計數器,⊙﹏⊙這得浪費多少記憶體吶,因此基數排序應運而生。
基數排序首先需要選擇一個基數(Radix)。什麼是基數呢,其實就是我們常說的進制中的基數,二進位制的基數是2,8進位制的基數是8,十進位制的基數是10…,通常我們選擇的基數是10,看起來比較直觀,除錯也方便。有了基數後我們怎麼用它來優化計數排序呢,核心步驟和計數排序相同,只是根據位數的多少進行了多輪計數。具體看下圖。
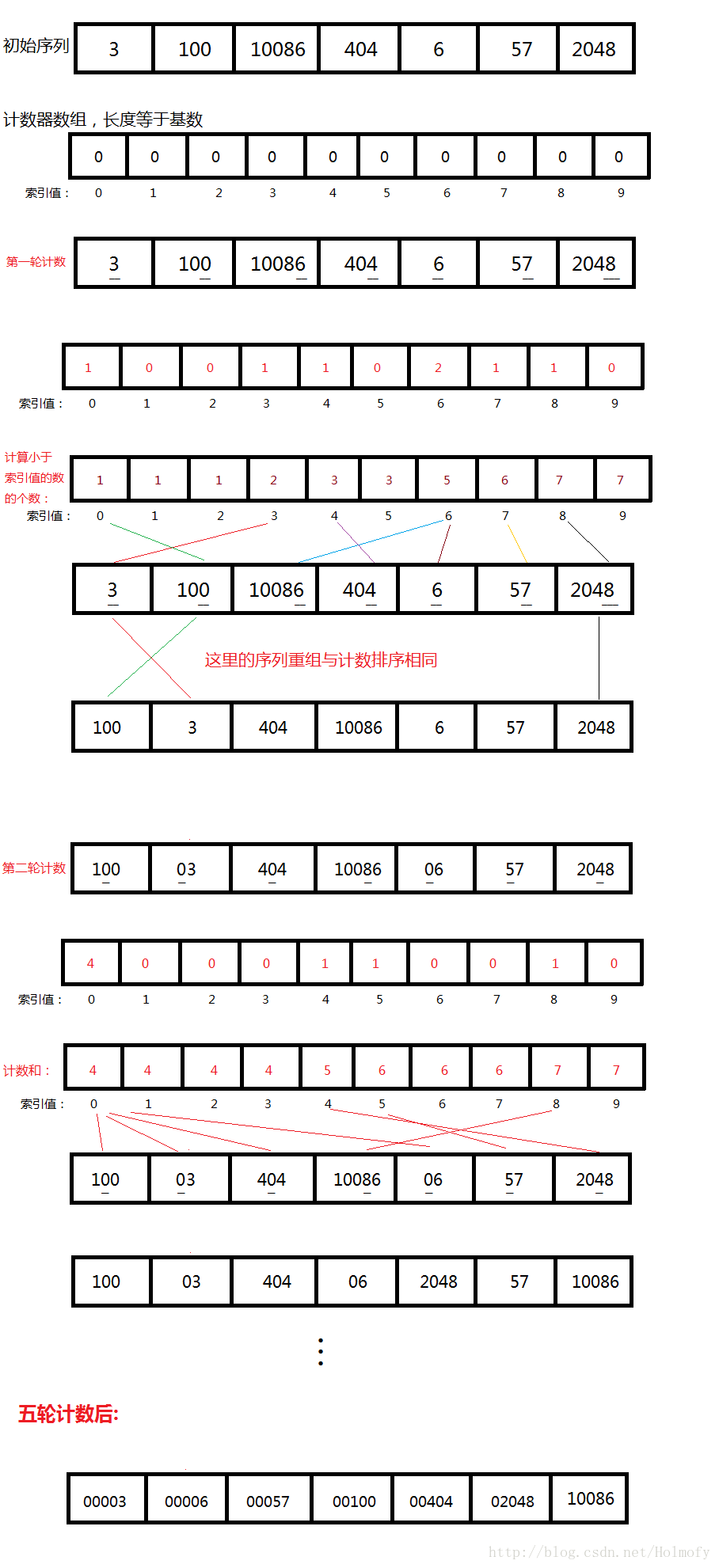
import java.util.Arrays;
import org.junit.Test;
/**
* 基數排序
*
* @author Holmofy
*
*/
public class RadixSort {
public void radixSort(int[] items) {
radixSort(items, 10);
}
public void radixSort(int[] items, int radix) {
int maxLength = 0;
for (int i = 0; i < items.length; i++) {
int itemLength = length(items[i], radix);
if (maxLength < itemLength) {
maxLength = itemLength;
}
}
int[] counter = new int[radix];
int[] result = new int[items.length];
for (int i = 0, r = 1; i < maxLength; i++, r *= radix) {
Arrays.fill(counter, 0);
// 內部就是一個計數排序
// 計數
for (int j = 0; j < items.length; j++) {
counter[(items[j] / r) % radix]++;
}
// 計數和
for (int j = 1; j < radix; j++) {
counter[j] += counter[j - 1];
}
// 整理出新序列
for (int j = items.length - 1; j >= 0; j--) {
int item = items[j];
result[--counter[(item / r) % radix]] = item;
}
System.arraycopy(result, 0, items, 0, items.length);
}
}
private int length(int num, int radix) {
int l = 1;
for (; num >= radix; num /= radix, l++);// 這裡有個分號
return l;
}
// 測試程式碼
private final int[] testItems = new int[] { 17, 256, 100, 404, 7, 9, 333, 2048, 10086, 100 };
@Test
public void testRadixSort() {
System.out.println("排序前:" + Arrays.toString(testItems));
radixSort(testItems);
System.out.println("排序後:" + Arrays.toString(testItems));
}
}執行結果:
排序前:[17, 256, 100, 404, 7, 9, 333, 2048, 10086, 100]
排序後:[7, 9, 17, 100, 100, 256, 333, 404, 2048, 10086]到了這裡基數排序還有一個缺陷:對於序列中的負數無能為力了,因為這裡的演算法和未優化的計數排序類似,如果你有更好的方案對基數排序進行優化,可以和大家分享一下。
鴿巢排序(PigeonholeSort)
講桶排序之前,先來說說鴿巢排序,其實鴿巢排序和前面的計數排序原理類似,這裡說的鴿巢其實就是計數器,不同的是後面的資料重排過程,鴿巢排序相對於計數排序來說更好理解,我就直接畫張圖貼在這了。
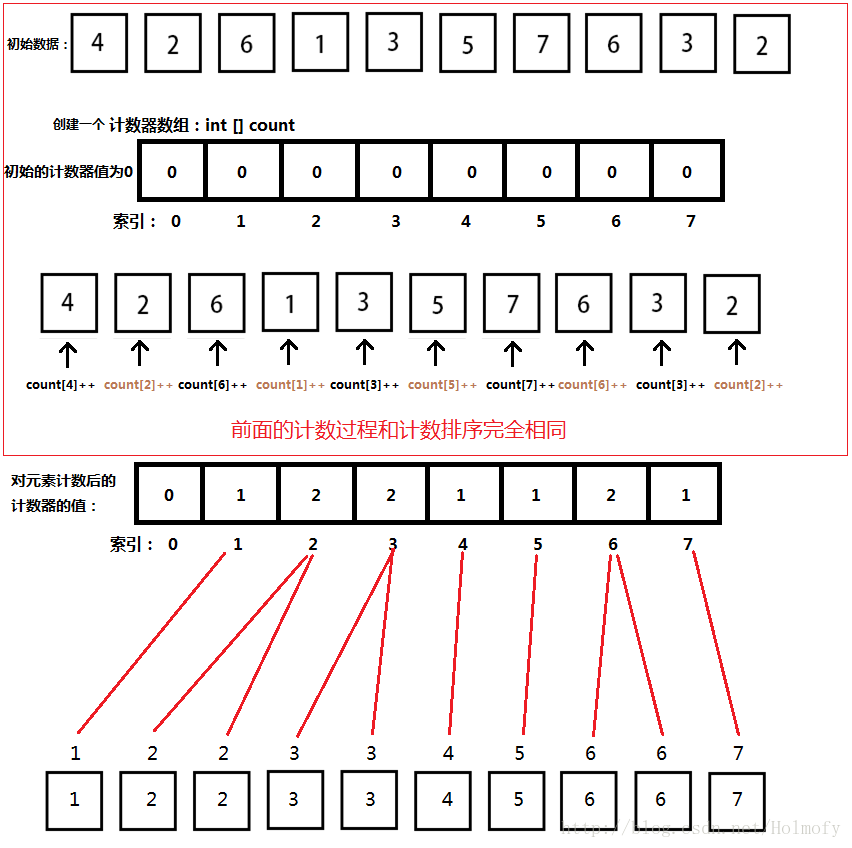
可以看出鴿巢排序是直接將遍歷計數器中的記錄,並對應的索引填入到陣列中。
JAVA實現
import java.util.Arrays;
import org.junit.Test;
public class PigeonholeSort {
public void pigeonholeSort(int[] items, int<