
Zookeeper 基礎、工作流、ZAP協議
ZooKeeper 基礎
在深入瞭解ZooKeeper的運作之前,讓我們來看看ZooKeeper的基本概念。我們將在本章中討論以下主題:
1、Architecture(架構)
2、Hierarchical namespace(層次名稱空間)
3、Session(會話)
4、Watch(監視)
ZooKeeper的架構
看看下面的圖表。它描述了ZooKeeper的“客戶端-伺服器架構”。
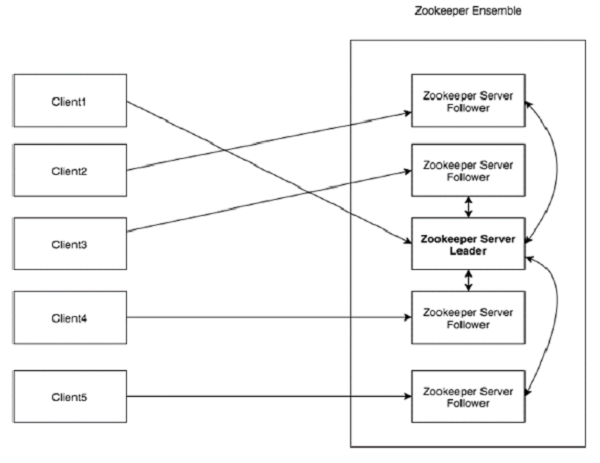
作為ZooKeeper架構的一部分的每個元件在下表中進行了說明。
| 部分 | 描述 |
|---|---|
| Client(客戶端) | 客戶端,分散式應用叢集中的一個節點,從伺服器訪問資訊。對於特定的時間間隔,每個客戶端向伺服器傳送訊息以使伺服器知道客戶端是活躍的。 類似地,當客戶端連線時,伺服器傳送確認碼。如果連線的伺服器沒有響應,客戶端會自動將訊息重定向到另一個伺服器。 |
| Server(伺服器) | 伺服器,我們的ZooKeeper總體中的一個節點,為客戶端提供所有的服務。向客戶端傳送確認碼以告知伺服器是活躍的。 |
| Ensemble | ZooKeeper伺服器組。形成ensemble所需的最小節點數為3。 |
| Leader | 伺服器節點,如果任何連線的節點失敗,則執行自動恢復。Leader在服務啟動時被選舉。 |
| Follower | 跟隨leader指令的伺服器節點。 |
層次名稱空間
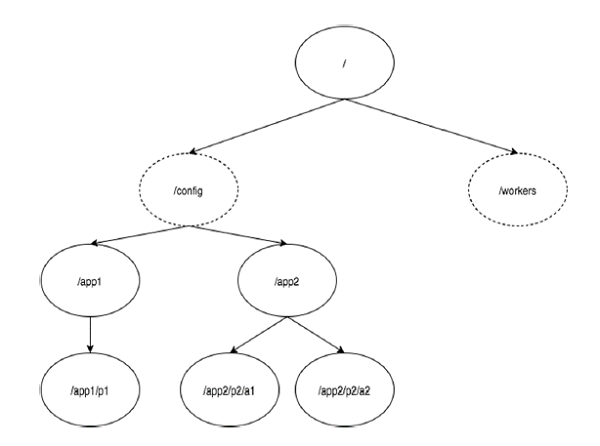
下圖描述了用於記憶體表示的ZooKeeper檔案系統的樹結構。ZooKeeper節點稱為 znode 。每個znode由一個名稱標識,並用路徑(/)序列分隔。
-
在圖中,首先有一個由“/”分隔的znode。在根目錄下,你有兩個邏輯名稱空間 config 和 workers 。
-
config 名稱空間用於集中式配置管理,workers 名稱空間用於命名。
-
在 config 名稱空間下,每個znode最多可儲存1MB的資料。這與UNIX檔案系統相類似,但是在ZooKeeper中,父znode也可以儲存資料。這種結構的主要目的是儲存同步資料並描述znode的元資料。此結構稱為 ZooKeeper資料模型
。
ZooKeeper資料模型中的每個znode都維護著一個 stat 結構。一個stat僅提供一個znode的元資料。它由版本號,操作控制列表(ACL),時間戳和資料長度組成。
-
版本號 - 每個znode都有版本號,這意味著每當與znode相關聯的資料發生變化時,其對應的版本號也會增加。當多個zookeeper客戶端嘗試在同一znode上執行操作時,版本號的使用就很重要。
-
操作控制列表(ACL) - ACL基本上是訪問znode的認證機制。它管理所有znode讀取和寫入操作。
-
時間戳 - 時間戳表示建立和修改znode所經過的時間。它通常以毫秒為單位。ZooKeeper從“事務ID"(zxid)標識znode的每個更改。Zxid 是唯一的,並且為每個事務保留時間,以便你可以輕鬆地確定從一個請求到另一個請求所經過的時間。
-
資料長度 - 儲存在znode中的資料總量是資料長度。你最多可以儲存1MB的資料。
Znode的型別
Znode被分為持久(persistent)節點,順序(sequential)節點和臨時(ephemeral)節點。
-
持久節點 - 即使在建立該特定znode的客戶端斷開連線後,持久節點仍然存在。預設情況下,除非另有說明,否則所有znode都是持久的。
-
臨時節點 - 客戶端活躍時,臨時節點就是有效的。當客戶端與ZooKeeper集合斷開連線時,臨時節點會自動刪除。因此,只有臨時節點不允許有子節點。如果臨時節點被刪除,則下一個合適的節點將填充其位置。臨時節點在leader選舉中起著重要作用。
-
順序節點 - 順序節點可以是持久的或臨時的。當一個新的znode被建立為一個順序節點時,ZooKeeper通過將10位的序列號附加到原始名稱來設定znode的路徑。例如,如果將具有路徑 /myapp 的znode建立為順序節點,則ZooKeeper會將路徑更改為 /myapp0000000001 ,並將下一個序列號設定為0000000002。如果兩個順序節點是同時建立的,那麼ZooKeeper不會對每個znode使用相同的數字。順序節點在鎖定和同步中起重要作用。
Session(會話)
會話對於ZooKeeper的操作非常重要。會話中的請求按FIFO順序執行。一旦客戶端連線到伺服器,將建立會話並向客戶端分配會話ID 。
客戶端以特定的時間間隔傳送心跳以保持會話有效。如果ZooKeeper集合在超過伺服器開啟時指定的期間(會話超時)都沒有從客戶端接收到心跳,則它會判定客戶端宕機。
會話超時通常以毫秒為單位。當會話由於任何原因結束時,在該會話期間建立的臨時節點也會被刪除。
Watch(監視)
監視是一種簡單的機制,用於向客戶端通知ZooKeeper集合中的更改。客戶端可以在讀取特定znode時設定watch。watch會向註冊的客戶端傳送有關znode任何更改的通知。
其中包含znode相關資料修改,或者znode的子項中的更改。
watches只觸發一次。如果客戶端想再次接收通知,則必須通過另一個讀取操作來完成。當連線會話過期時,客戶端將與伺服器斷開連線,相關的watches也將被刪除。
Zookeeper 工作流
一旦ZooKeeper集合啟動,它將等待客戶端連線。客戶端將連線到ZooKeeper集合中的一個節點。它可以是leader或Follower節點。一旦客戶端被連線,節點將向特定客戶端分配會話ID並向該客戶端傳送確認。如果客戶端沒有收到確認,它將嘗試連線ZooKeeper集合中的另一個節點。 一旦連線到節點,客戶端將以有規律的間隔向節點發送心跳,以確保連線不會丟失。
讀取和寫入
-
如果客戶端想要讀取特定的znode,它將會向具有znode路徑的節點發送讀取請求,並且節點通過從其自己的資料庫獲取來返回所請求的znode。為此,在ZooKeeper集合中讀取速度很快。
-
如果客戶端想要將資料儲存在ZooKeeper集合中,則會將znode路徑和資料傳送到伺服器。連線的伺服器將該請求轉發給leader,然後leader將向所有的Follower重新發出寫入請求。如果大部分節點成功響應,而寫入請求成功,傳送成功程式碼到客戶端。 否則,寫入請求失敗。絕大多數節點被稱為 Quorum 。
集合節點個數
讓我們分析在ZooKeeper集合中擁有不同數量的節點的效果。
-
單個節點,則當該節點故障時,ZooKeeper集合將故障。它將產生“單點故障",不建議在生產環境中使用。
-
兩個節點,一個節點故障。不能稱作大多數可用,因為兩個中的一個不是多數。
-
三個節點,一個節點故障。大多數可用。因此,ZooKeeper集合在實際生產環境中必須至少有三個節點。
-
四個節點,兩個節點故障。它將故障。對比與三個節點,多出的節點不起作用。因此,最好新增奇數的節點,例如3,5,7。
寫入比讀取代價大,因為所有節點都需要寫入相同的資料。因此對於讀寫平衡的環境,擁有較少數量(例如3,5,7)的節點比擁有大量的節點要好。
工作流及元件
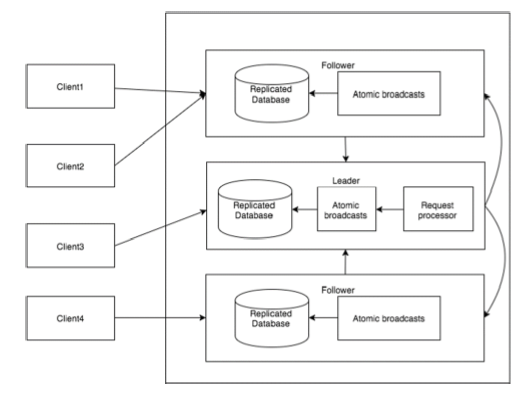
| 元件 | 描述 |
|---|---|
| 寫入(write) | 寫入過程由leader節點處理。leader將寫入請求轉發到所有znode,並等待znode的回覆。如果一半的znode回覆,則寫入過程完成。 |
| 讀取(read) | 讀取由特定連線的znode在內部執行,不需要與叢集進行互動。 |
| 複製資料庫(replicated database) | 用於在zookeeper中儲存資料。每個znode都有自己的資料庫,由於ZooKeeper的一致性,每個znode擁有相同的資料。 |
| Leader | leader是負責處理寫入請求的znode。 |
| Follower | Follower從客戶端接收寫入請求,並將它們轉發到 leader znode。 |
| 請求處理器(request processor) | 只在leader節點中存在,用於管理來自Follower節點的寫入請求。 |
| 原子廣播(atomic broadcasts) |
ZAB協議
zookeeper atomic broadcast 稱為 ZAB協議。
三種狀態
協議中存在著三種狀態,每個節點都屬於以下三種中的一種:
- Looking:系統剛啟動時或Leader崩潰後正處於選舉狀態
- Following:Follower節點所處的狀態,Follower與Leader處於資料同步階段
- Leading:Leader所處狀態,當前叢集中有一個Leader為主程序
在ZooKeeper的整個生命週期中每個節點都會在Looking、Following、Leading狀態間不斷轉換:
- ZooKeeper啟動時所有節點初始狀態為Looking,這時叢集會嘗試選舉出一個Leader節點,選舉出的Leader節點切換為Leading狀態
- 當節點發現叢集中已經選舉出Leader,則該節點會切換到Following狀態,然後和Leader節點保持同步
- 當Follower節點與Leader失去聯絡時Follower節點則會切換到Looking狀態,開始新一輪選舉
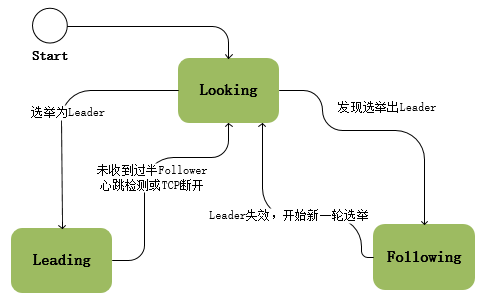
選舉出Leader節點後ZAB進入原子廣播階段,這時Leader為和自己同步的每個節點Follower建立一個操作序列
- 一個時期一個Follower只能和一個Leader保持同步,Leader節點與Follower節點使用心跳檢測來感知對方的存在
- 當Leader節點在超時時間內收到來自Follower的心跳檢測,那Follower節點會一直與該節點保持連線
- 若超時時間內Leader沒有接收到來自過半Follower節點的心跳檢測或TCP連線斷開,那Leader會結束當前週期的領導,切換到Looking狀態,所有Follower節點也會放棄該Leader節點切換到Looking狀態,然後開始新一輪選舉
四個階段
ZAB協議定義了選舉(election)、發現(discovery)、同步(sync)、廣播(Broadcast)四個階段;ZAB選舉(election)時當Follower存在ZXID(事務ID)時判斷所有Follower節點的事務日誌,只有lastZXID的節點才有資格成為Leader,這種情況下選舉出來的Leader總有最新的事務日誌,基於這個原因ZoKeeper實現時把發現(discovery)與同步(sync)合併為恢復(recovery)階段
- Election:在Looking狀態中選舉出Leader節點,Leader的lastZXID總是最新的
- Discovery:Follower節點向準Leader推送FOLLOWERINFO,該資訊中包含了上一週期的epoch,接受準Leader的NEWLEADER指令,檢查newEpoch有效性,準Leader要確保Follower的epoch與ZXID小於或等於自身的
- sync:將Follower與Leader的資料進行同步,由Leader發起同步指令,最總保持叢集資料的一致性
- Broadcast:Leader廣播Proposal與Commit,Follower接受Proposal與Commit
- Recovery:在Election階段選舉出Leader後本階段主要工作就是進行資料的同步,使Leader具有highestZXID,叢集保持資料的一致性
(1)選舉 Election
election階段必須確保選出的Leader具有highestZXID,否則在Recovery階段沒法保證資料的一致性,Recovery階段Leader要求Follower向自己同步資料沒有Follower要求Leader保持資料同步,所有選舉出來的Leader要具有最新的ZXID。
在選舉的過程中會對每個Follower節點的ZXID進行對比只有highestZXID的Follower才可能當選Leader。
選舉流程:
- 每個Follower都向其他節點發送選自身為Leader的Vote投票請求,等待回覆
- Follower接受到的Vote如果比自身的大(ZXID更新)時則投票,並更新自身的Vote,否則拒絕投票
- 每個Follower中維護著一個投票記錄表,當某個節點收到過半的投票時,結束投票並把該Follower選為Leader,投票結束。
ZAB協議中使用ZXID作為事務編號,ZXID為64位數字,低32位為一個遞增的計數器,每一個客戶端的一個事務請求時Leader產生新的事務後該計數器都會加1,高32位為Leader週期epoch編號,當新選舉出一個Leader節點時Leader會取出本地日誌中最大事務Proposal的ZXID解析出對應的epoch把該值加1作為新的epoch,將低32位從0開始生成新的ZXID;ZAB使用epoch來區分不同的Leader週期。
(2)恢復 Recovery
在election階段選舉出來的Leader已經具有最新的ZXID,所有本階段的主要工作是根據Leader的事務日誌對Follower節點資料進行更新。
Leader:Leader生成新的ZXID與epoch,接收Follower傳送過來的FOllOWERINFO(含有當前節點的LastZXID)然後往Follower傳送NEWLEADER;Leader根據Follower傳送過來的LastZXID根據資料更新策略向Follower傳送更新指令。
同步策略:
- SNAP:如果Follower資料太老,Leader將傳送快照SNAP指令給Follower同步資料
- DIFF:Leader傳送從Follolwer.lastZXID到Leader.lastZXID議案的DIFF指令給Follower同步資料
- TRUNC:當Follower.lastZXID比Leader.lastZXID大時,Leader傳送從Leader.lastZXID到Follower.lastZXID的TRUNC指令讓Follower丟棄該段資料;
Follower:往Leader傳送FOLLOERINFO指令,Leader拒絕就轉到Election階段;接收Leader的NEWLEADER指令,如果該指令中epoch比當前Follower的epoch小那麼Follower轉到Election階段;Follower還有主要工作是接收SNAP/DIFF/TRUNC指令同步資料與ZXID,同步成功後回覆ACKNETLEADER,然後進入下一階段;Follower將所有事務都同步完成後Leader會把該節點新增到可用Follower列表中。
SNAP與DIFF用於保證叢集中Follower節點已經Committed的資料的一致性,TRUNC用於拋棄已經被處理但是沒有Committed的資料。
(3)廣播 Broadcast
客戶端提交事務請求時Leader節點為每一個請求生成一個事務Proposal,將其傳送給叢集中所有的Follower節點,收到過半Follower的反饋後開始對事務進行提交,ZAB協議使用了原子廣播協議;在ZAB協議中只需要得到過半的Follower節點反饋Ack就可以對事務進行提交,這也導致了Leader幾點崩潰後可能會出現資料不一致的情況,ZAB使用了崩潰恢復來處理數字不一致問題;訊息廣播使用了TCP協議進行通訊所有保證了接受和傳送事務的順序性。廣播訊息時Leader節點為每個事務Proposal分配一個全域性遞增的ZXID(事務ID),每個事務Proposal都按照ZXID順序來處理;
Leader節點為每一個Follower節點分配一個佇列按事務ZXID順序放入到佇列中,且根據佇列的規則FIFO來進行事務的傳送。Follower節點收到事務Proposal後會將該事務以事務日誌方式寫入到本地磁碟中,成功後反饋Ack訊息給Leader節點,Leader在接收到過半Follower節點的Ack反饋後就會進行事務的提交,以此同時向所有的Follower節點廣播Commit訊息,Follower節點收到Commit後開始對事務進行提交。
參考資料:
https://www.w3cschool.cn/zookeeper/zookeeper_fundamentals.html
http://www.solinx.co/archives/435
http://web.stanford.edu/class/cs347/reading/zab.pdf
http://www.tcs.hut.fi/Studies/T-79.5001/reports/2012-deSouzaMedeiros.pdf