
為什麼目標檢測中要將全連線層轉化為卷積層?
參考文章:
VGG網路中測試時為什麼全連結層改成卷積層
為什麼使用卷積層替代CNN末尾的全連線層
首先看一下卷積層的特點:
區域性連線:提取資料區域性特徵,比如卷積核的感受野
權值共享:一個卷積核只需提取一個特徵,降低了網路訓練的難度
究竟使用卷積層代替全連線層會帶來什麼好處呢?
答:全連線層的權重是不變的,所以輸入的圖片大小不能變。而卷積層可以讓卷積網路在一張更大的輸入圖片上滑動,得到每個區域的輸出,這樣就突破了輸入尺寸的限制,就獲得了目標的位置資訊。可以高效地對測試影象做滑動窗式的預測.
可以高效的檢測多個目標和給出位置資訊。
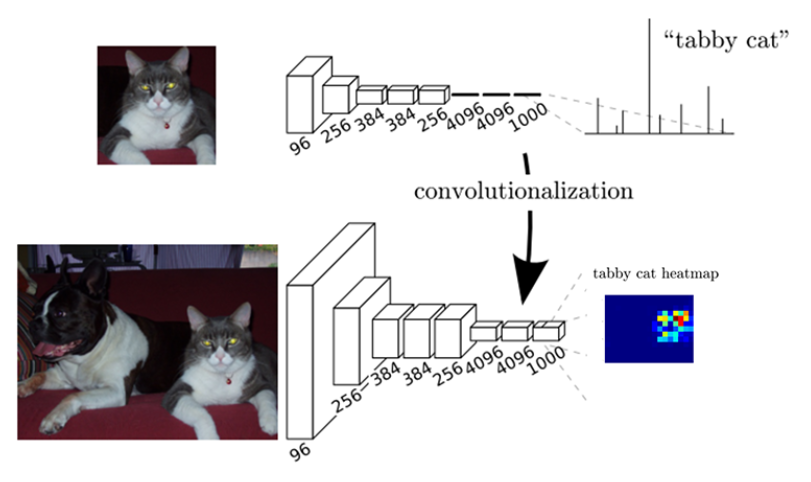
這一特性不僅可用於語義分割,在物體分類、目標檢測中都可以使用
相關推薦
為什麼目標檢測中要將全連線層轉化為卷積層?
參考文章: VGG網路中測試時為什麼全連結層改成卷積層 為什麼使用卷積層替代CNN末尾的全連線層 首先看一下卷積層的特點: 區域性連線:提取資料區域性特徵,比如卷積核的感受野 權值共享:一個卷積核只需提取一個特徵,降低了網路訓練的難度 究竟使用卷積層代替全連線層會帶來什麼好處呢?
為什麼要將全連線層轉化為卷積層
轉自:https://www.cnblogs.com/liuzhan709/p/9356960.html 理解為什麼要將全連線層轉化為卷積層 1.全連線層可以視作一種特殊的卷積 考慮下面兩種情況: 特徵圖和全連線層相連,AlexNet經過五次池化後得到7*7*512的特徵圖,下
卷積層上的滑動視窗(將全連線層轉化為卷積層)
全連線層轉化為卷積層 一、FC網路 在有全連線層的網路中,第一個FC是將上一層5*5*16的多維資料拉成一行,轉化為1*1*400,在通過一個變換矩陣,變成第二個FC,然後經過softmax輸出預測
卷積神經網路全連線層轉換為卷積層獲得heatmap
理論部分 轉自 http://blog.csdn.net/u010668083/article/details/46650877 實驗部分 全連線層換卷積層的出處大約是yahoo的一篇論文“Multi-view Face Detection Usi
如何保存Tensorflow中的Tensor參數,保存訓練中的中間參數,存儲卷積層的數據
put pool 數據 random ack 滑動 orm over 尺寸 在自己構建的卷積神經時,我想把卷積層的數據提取出來,但是這些數據是Tensor類型的 網上幾乎找不到怎麽存儲的例子,然後被我發下了一下解決辦法 https://stackoverflow.com/
Batch Normalization--全連線神經網路和卷積神經網路實戰
Batch Normalization原理 網上部落格一大堆,說的也很明白,這裡就簡單的說一下我的個人理解: 對每一個特徵值進行 0均值化,利於神經網路擬合時,對於自身的引數b,無需修改很多次,
Java 中要將 String 類型轉化為 int 類型
ava index 需要 amp con 轉換 catch div 出現 在 Java 中要將 String 類型轉化為 int 類型時,需要使用 Integer 類中的 parseInt() 方法或者 valueOf() 方法進行轉換. 例1: 1 2 3 4 5
目標檢測中對端對端(End to end)的理解
End to end:指的是輸入原始資料,輸出的是最後結果,應用在特徵學習融入演算法,無需單獨處理。 end-to-end(端對端)的方法,一端輸入我的原始資料,一端輸出我想得到的結果。只關心輸入和輸出,中間的步驟全部都不管。 端到端指的是輸入是原始資料,輸出是最後的結果,原來輸入端不是
CNN卷積層到全連線層的輸入格式變換錯誤 tf.reshape()和slim.flatten()
TypeError: Failed to convert object of type < type ‘list’>to Tensor. Contents: [None, 9216]. Consider casting elements to a supported type.
【深度學習筆記】關於卷積層、池化層、全連線層簡單的比較
卷積層 池化層 全連線層 功能 提取特徵 壓縮特徵圖,提取主要特徵 將學到的“分散式特徵表示”對映到樣本標記空間 操作 可看這個的動態圖,可惜是二維的。對於三維資料比如RGB影象(3通道),卷積核的深度必須
目標檢測中tensorflow常用API以及備選框篩選程式碼分析
目標檢測演算法中,因為產生的備選框特別多,需要刪減。而刪減的方法是NMS(非極大抑制演算法)。網上很多演算法是自己編寫功能程式碼。但是這不是tensorflow中自帶的功能,所以在使用tensorflow恢復模型的時候,sess並不能hold住他們。因此別人需要
目標檢測中的AP和mAP
作者:Wentao 連結:https://www.zhihu.com/question/53405779/answer/419532990 來源:知乎 著作權歸作者所有。商業轉載請聯絡作者獲得授權,非商業轉載請註明出處。 mAP定義及相關概念 mAP: mean Aver
目標檢測中常見程式程式碼片段總結
在學習目標檢測的過程中,除了看大神的原作之外,還要學習大神的原始碼,通過原作和原始碼才能更好的學習大神的思想。作為一個新手,在閱讀原始碼的過程是一個倍感煎熬的過程,如果大神的程式碼註釋比較少的話,有的時候為了理解某一個程式碼片段,可能需要花上幾天的時間來理解,這是一個很費時的
【python】小目標檢測中對一幅高解析度圖分塊且改變目標bounding box的座標
很多時候,在小目標檢測中,對於一副高解析度影象,我們很難直接輸入一整幅大圖來進行目標檢測,特別是對於one-stage的方法,如SSD的輸入尺寸是300和512, YOLO的輸入尺寸是416,而高解析度影象通常有幾千×幾千畫素。所以我在此分享將一副高解析度影象分塊同時寫入對應目標的bound
目標檢測中的Anchor Box演算法
引入 無論是基於滑動視窗,還是基於網格YOLO的目標檢測演算法,都有可能存在同一個問題:有可能一個BOX中有多個目標,如下圖所示: 這樣的圖中,行人和車同時存在,並且他們的中心位置都位於同一個網格中。這種情況下,傳統檢測方法的輸出,就無法勝任了。怎麼解決這個問
目標檢測中IOU和NMS的python實現
IOU:兩個框的交併比 import numpy as np def compute_iou(box1, box2, wh=False): """ compute the iou of two boxes. Args: box1, box2: [xmin,
深度學習在目標檢測中的應用及其tensorflowAPI實踐(二)
這系列文章的內容目錄如下: 目標檢測的任務 深度學習在目標檢測中的應用 RCNN fast RCNN faster RCNN RFCN yolo yolo V2 SSD tensorflow目標檢測API的使用 在第一篇裡說完了RCNN和fast RC
CNN(卷積層convolutional layer,激勵層activating layer,池化層pooling,全連線層fully connected)
CNN產生的原因:當使用全連線的神經網路時,因為相鄰兩層之間的神經元都是有邊相連的,當輸入層的特徵緯度非常高時(譬如圖片),全連線網路需要被訓練的引數就會非常多(引數太多,訓練緩慢),CNN可以通過訓練少量的引數從而進行特徵提取。上圖每一個邊就代表一個需要訓練的引數,可以直觀
為什麼使用卷積層替代CNN末尾的全連線層
CNN網路的經典結構是: 輸入層—>(卷積層+—>池化層?)+—>全連線層+ (其中+表示至少匹配1次,?表示匹配0次或1次) 全卷積神經網路Fully Convolutional Network (FCN) 全卷積神經網路即把CNN
目標檢測中的正負樣本
在做目標檢測任務時對其中的正負樣本不太清楚,看了很多資料,發現這篇部落格解釋的比較清晰,下面圖片也出自上述部落格。 以人臉識別為例,如果你的任務是識別教室中的人臉,那麼負樣本的選取應該是教室中的窗戶、椅子、牆、人的身體、衣服顏色等等,而不是天空、月