
[轉]資料庫正規化簡介
正規化的級別
設計關係資料庫時,遵從不同的規範要求,設計出合理的關係型資料庫,這些不同的規範要求被稱為不同的正規化,各種正規化呈遞次規範,越高的正規化資料庫冗餘越小。
目前關係資料庫有六種正規化:第一正規化(1NF)、第二正規化(2NF)、第三正規化(3NF)、巴斯-科德正規化(BCNF)、第四正規化(4NF)和第五正規化(5NF,又稱完美正規化)。
正規化越高,冗餘最低,一般到三正規化,再往上,表越多,可能導致查詢效率下降。所以有時為了提高執行效率,可以讓資料冗餘(反三正規化,一般某個資料經常被訪問時,比如資料表裡存放了語文數學英語成績,但是如果在某個時間經常要得到它的總分,每次都要進行計算會降低效能,可以加上總分這個冗餘欄位)。
後面的正規化是在滿足前面正規化的基礎上,比如滿足第二正規化的一定滿足第一正規化。
第一正規化(1NF):確保每一列的原子性
如果每一列都是不可再分的最小資料單元,則滿足第一正規化。
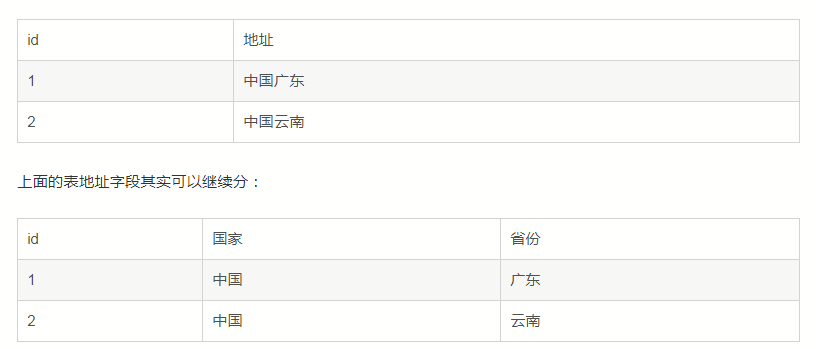
但是具體地址到底要不要拆分 還要看具體情形,比如看看將來會不會按國家或者省市進行分類彙總或者排序,如果需要,最好就拆,如果不需要而僅僅起字串的作用,可以不拆,操作起來更方便。
第二正規化:非鍵欄位必須依賴於鍵欄位
如果一個關係滿足1NF,並且除了主鍵以外的其它列,都依賴與該主鍵,則滿足二正規化(2NF),第二正規化要求每個表只描述一件事。
例如:
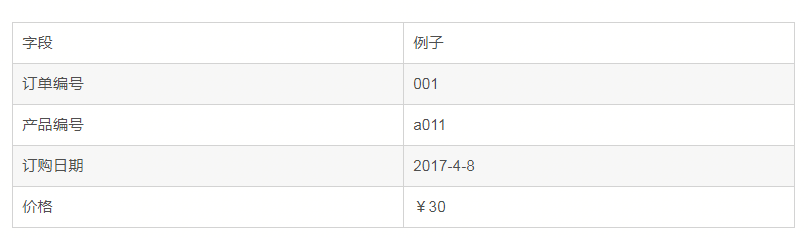
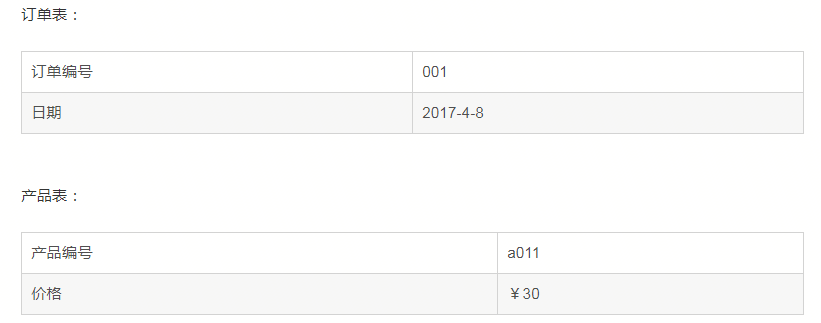
而實際上,產品編號與訂單編號並沒有明確的關係,訂購日期與訂單編號有關係,因為一旦訂單編號確定下來了,訂購日期也確定了,價格與訂單編號也沒有直接關係,而與產品有關,所以上面的表實際上可以拆分:
第三正規化:在1NF基礎上,除了主鍵以外的其它列都不傳遞依賴於主鍵列,或者說: 任何非主屬性不依賴於其它非主屬性
(在2NF基礎上消除傳遞依賴)
例如:
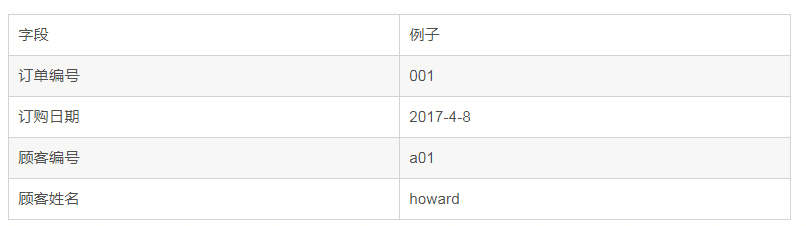
上面的滿足第一和第二正規化,但是不滿足第三正規化,原因如下:
通過顧客編號可以確定顧客姓名,通過顧客姓名可以確定顧客編號,即在這個訂單表裡,這兩個欄位存在傳遞依賴,只需要一個就夠了。
又如:
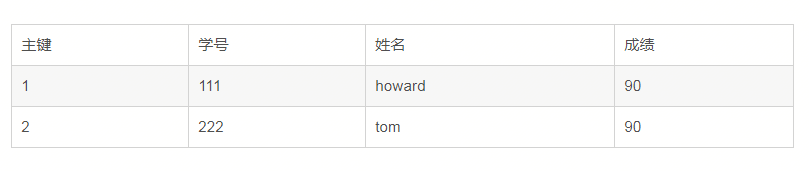
上面的表,學號和姓名存在傳遞依賴,因為(學號,姓名)->成績,學號->成績,姓名->成績。所以學號和姓名有一個冗餘了,只需要保留一個。
參考文章:https://blog.csdn.net/zymx14/article/details/69789326