
OCR技術簡介
光學字元識別(Optical Character Recognition, OCR)是指對文字資料的影象檔案進行分析識別處理,獲取文字及版面資訊的過程。亦即將影象中的文字進行識別,並以文字的形式返回。
OCR的應用場景
根據識別場景,可大致將OCR分為識別特定場景的專用OCR和識別多種場景的通用OCR。比如現今方興未艾的證件識別和車牌識別就是專用OCR的典型例項。通用OCR可以用於更復雜的場景,也具有更大的應用潛力。但由於通用圖片的場景不固定,文字佈局多樣,因此難度更高。根據所識別圖片的內容,可將場景分為清晰且具有固定模式的簡單場景和更為複雜的自然場景。自然場景文字識別的難度極高,原因包括:圖片背景極為豐富,經常面臨低亮度、低對比度、光照不均、透視變形和殘缺遮擋等問題,而且文字的佈局可能存在扭曲、褶皺、換向等問題,其中的文字也可能字型多樣、字號字重顏色不一的問題。因此自然場景中的文字識別技術,也經常被單列為場景文字識別技術(Scene Text Recognition, STR),相關內容可回顧往期SigAI的文章。
OCR的技術路線
典型的OCR的技術路線如下圖所示

其中影響識別準確率的技術瓶頸是文字檢測和文字識別,而這兩部分也是OCR技術的重中之重。
在傳統OCR技術中,影象預處理通常是針對影象的成像問題進行修正。常見的預處理過程包括:幾何變換(透視、扭曲、旋轉等)、畸變校正、去除模糊、影象增強和光線校正等
文字檢測即檢測文字的所在位置和範圍及其佈局。通常也包括版面分析和文字行檢測等。文字檢測主要解決的問題是哪裡有文字,文字的範圍有多大。
文字識別是在文字檢測的基礎上,對文字內容進行識別,將影象中的文字資訊轉化為文字資訊。文字識別主要解決的問題是每個文字是什麼。識別出的文字通常需要再次核對以保證其正確性。文字校正也被認為屬於這一環節。而其中當識別的內容是由詞庫中的詞彙組成時,我們稱作有詞典識別(Lexicon-based),反之稱作無詞典識別(Lexicon-free)
影象預處理
傳統OCR基於數字影象處理和傳統機器學習等方法對影象進行處理和特徵提取。常用的二值化處理有利於增強簡單場景的文字資訊,但對於複雜背景二值化的收效甚微。
傳統方法上採用HoG對影象進行特徵提取,然而HoG對於影象模糊、扭曲等問題魯棒性很差,對於複雜場景泛化能力不佳。由於深度學習的飛速發展,現在普遍使用基於CNN的神經網路作為特徵提取手段。得益於CNN強大的學習能力,配合大量的資料可以增強特徵提取的魯棒性,面臨模糊、扭曲、畸變、複雜背景和光線不清等影象問題均可以表現良好的魯棒性。[1]

文字檢測
對於文字檢測任務,很自然地可以想到套用影象檢測的方法來框選出影象中的文字區域。常見的一些物體檢測方法如下:
Faster R-CNNFaster R-CNN採用輔助生成樣本的RPN(Region Proposal Networks)網路,將演算法結構分為兩個部分,先由RPN 網路判斷候選框是否為目標,再經分類定位的多工損失判斷目標型別,整個網路流程都能共享卷積神經網路提取的的特徵資訊,節約計算成本,且解決Fast R-CNN 演算法生成正負樣本候選框速度慢的問題,同時避免候選框提取過多導致演算法準確率下降。對於受限場景的文字檢測,Faster R-CNN的表現較為出色。可以通過多次檢測確定不同粒度的文字區域。[2]

FCN相較於Faster R-CNN 演算法只能計算ROI pooling 層之前的卷積網路特徵引數,R-FCN 演算法提出一種位置敏感分佈的卷積網路代替ROI pooling 層之後的全連線網路,解決了Faster R-CNN 由於ROI Pooling 層後面的結構需要對每一個樣本區域跑一次而耗時比較大的問題,使得特徵共享在整個網路內得以實現,解決物體分類要求有平移不變性和物體檢測要求有平移變化的矛盾,但是沒有考慮到候選區域的全域性資訊和語義資訊。[3]所以當面對自然場景的通用OCR,適於多尺度檢測的FCN較之Faster R-CNN有著更好的表現。當採用FCN時,輸出的掩膜可以作為前景文字的二值影象進行輸出。

但是與其他日常場景的物體檢測所不同的是,文字影象的分佈更接近於均勻分佈而非正態分佈,即文字總體的均值影象並不能體現文字這一抽象概念的特徵。除此之外,文字的長寬比與物體的長寬比不同,導致候選錨定框不適用;文字的方向仍然不能確定,對非垂直的文字方向表現佳;自然場景中常出現一些結構與文字非常接近,導致假陽性率升高。因此需要對現有模型進行調整。
一種常見的做法是調整候選錨定框,例如
RRPN(Rotation Region Proposal Networks)在faster R-CNN的基礎上,將垂直的候選錨定框進行旋轉滿足非垂直文字的檢測,這樣一來就可以滿足非垂直文字的檢測需求。[4]

TextBoxes是基於SSD改進的一個演算法。調整了錨定框的長寬比,以適應文字的高長寬比。輸出層也利用了利用非標準的卷積核。更適應文字細長的寬高比這一特點。[5]

DMPNet(Deep Matching Prior Network)採用非矩形四邊形的候選錨定框進行檢測。通過Monte-Carlo方法計算標註區域與矩形候選框和旋轉候選框的重合度後重新計算頂點座標,得到非矩形四邊形的頂點座標。[6]

另一種改進的方法是通過自底向頂的方法,檢測細粒度文字後將其連線成更粗粒度的文字
CTPN(Connectionist Text Proposal Network)是目前應用最廣的文字檢測模型之一。其基本假設是單個字元相較於異質化程度更高的文字行更容易被檢測,因此先對單個字元進行類似R-CNN的檢測。之後又在檢測網路中加入了雙向LSTM,使檢測結果形成序列提供了文字的上下文特徵,便可以將多個字元進行合併得到文字行。[7]

SegLink則是在SSD的啟發下得出的。採用臨近連線的方法對上下文進行連線。並且通過將連線引數的學習整合進了神經網路的學習過程,使得模型更容易訓練。[8]
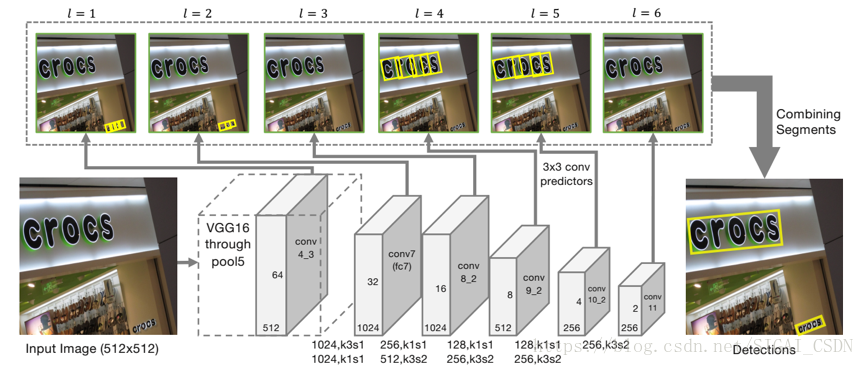
標題
有一些研究引入了注意力機制,如下圖模型採用Dense Attention模型來對影象的權重進行評估。這樣有利於將前景影象和背景影象分離,對於文字內容較之背景影象有著更高的注意力,使檢測結果更準確。[9]
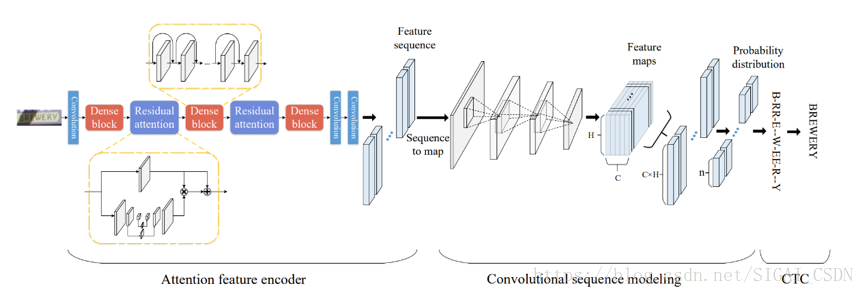
文字識別
文字識別在傳統技術中採用模板匹配的方式進行分類。但是對於文字行,只能通過識別出每一個字元來確定最終文字行從內容。因此可以對文字行進行字元切分,以得到單個文字。這種方式中,過分割-動態規劃是最常見的切分方法。由於單個字元可能會由於切分位置的原因產生多個識別結果,例如“如”字在切分不當時會被切分成“女_口”,因此需要對候選字元進行過分割,使其足夠破碎,之後通過動態規劃合併分割碎片,得到最優組合,這一過程需要人工設計損失函式。還有另一種方法是通過滑動視窗對每一個可能的字元進行匹配,這種方法的準確率依賴於滑動視窗的滑動窗尺寸,如果滑動窗尺寸過大會造成資訊丟失,而太小則會使計算力需求大幅增加。
以上的傳統方法通過識別每個單字元以實現全文的識別,這一過程導致了上下文資訊的丟失,對於單個字元有較高的識別正確率,其條目識別正確率也難以保證。以身份證識別為例,識別18位的身份號的場景下,即使單字元識別正確率高達99%,其條目正確率只能到0.9918=83%,如果切分也存在1%的損失(即正確率99%),條目正確率則只有(0.99*0.99)18=70%。
因此引入上下文的資訊,成為了提升條目準確率的關鍵。從深度學習的角度出發,要引入上下文這樣的序列資訊,RNN和LSTM等依賴於時序關係的神經網路是最理想的選擇。

常見的一種做法是利用CRNN模型。以CNN特徵作為輸入,雙向LSTM進行序列處理使得文字識別的效率大幅提升,也提升了模型的泛化能力。先由分類方法得到特徵圖,之後通過CTC對結果進行翻譯得到輸出結果。[10]

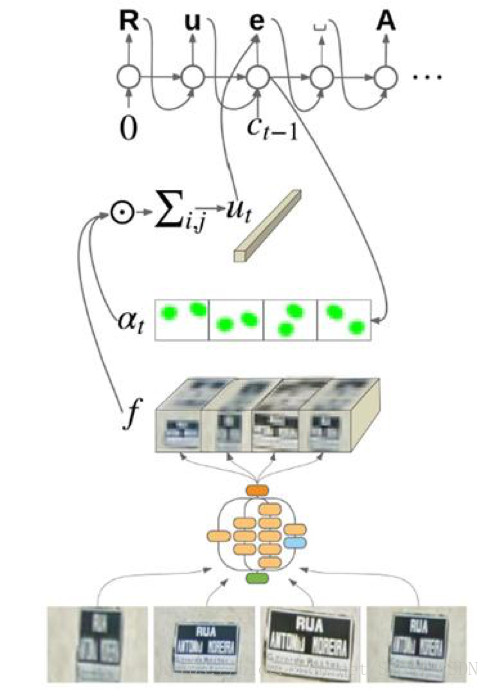
另一種方法是引入注意力機制。以CNN特徵作為輸入,通過注意力模型對RNN的狀態和上一狀態的注意力權重計算出新一狀態的注意力權重。之後將CNN特徵和權重輸入RNN,通過編碼和解碼得到結果。[11]
端到端的OCR
與檢測-識別的多階段OCR不同,深度學習使端到端的OCR成為可能,將文字的檢測和識別統一到同一個工作流中。目前比較受到矚目的一種端到端框架叫做FOTS(Fast Oriented Text Spotting)。FOTS的檢測任務和識別任務共享卷積特徵圖。一方面利用卷積特徵進行檢測,另一方面引入了RoIRotate,一種用於提取定向文字區域的算符。得到文字候選特徵後,將其輸入到RNN編碼器和CTC解碼器中進行識別。同時,由於所有算符都是可微的,因此端到端的網路訓練成為可能。由於簡化了工作流,網路可以在極低運算開銷下進行驗證,達到實時速度。[12]

總結
儘管基於深度學習的OCR表現相較於傳統方法更為出色,但是深度學習技術仍需要在OCR領域進行特化,而其中的關鍵正式傳統OCR方法的精髓。因此我們仍需要從傳統方法中汲取經驗,使其與深度學習有機結合進一步提升OCR的效能表現。另一方面,作為深度學習的推動力,資料起到了至關重要的作用,因此收集廣泛而優質的資料也是現階段OCR效能的重要舉措之一。
參考文獻
[1] Lécun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998,86(11):2278-2324.
[5] Liao M, Shi B, Bai X, et al. TextBoxes: A Fast Text Detector with a Single Deep Neural Network[J]. 2016.
[6] Liu Y, Jin L. Deep Matching Prior Network: Toward Tighter Multi-oriented Text Detection[C]//: IEEE Conference on Computer Vision and Pattern Recognition, 2017.
[7] Tian Z, Huang W, He T, et al. Detecting Text in Natural Image with Connectionist Text Proposal Network[C]//: European Conference on Computer Vision, 2016.
[9] Gao Y, Chen Y, Wang J, et al. Reading Scene Text with Attention Convolutional Sequence Modeling[J]. 2017.
[11] Wojna Z, Gorban A N, Lee D S, et al. Attention-Based Extraction of Structured Information from Street View Imagery[J]. 2017:844-850.
[12] Liu X, Liang D, Yan S, et al. FOTS: Fast Oriented Text Spotting with a Unified Network[J]. 2018.