
Elasticsearch 優化
Elasticsearch是一個基於Lucene的搜尋伺服器,其搜尋的核心原理是倒排索引,今天談下在日常專案中使用它遇到的一些問題及優化解決辦法。
一. 搜尋的深度分頁問題
在日常專案中,經常會有分頁搜尋並支援跳頁的需求,類似百度、Google搜尋那樣,使用ES進行這類需求的搜尋時一般採用from/size的方式,from指明開始的位置,size指定獲取的條數,通過這種方式獲取資料稱為深度分頁。
通過這種分頁方式當我取 from為11000,size為10時,發現無法獲取:
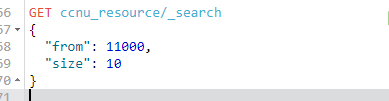

ES報錯說超過了max_result_window
初步解決方案:
我修改了索引的設定,將max_result_window設定為了10000000:
PUT ccnu_resource/_settings
{
"index": {
"max_result_window": 10000000
}
}
這樣做雖然解決了問題,並且目前在效能上也沒有太大問題。一次當我用Google搜尋時時,突發奇想,想試試Google的最大分頁數:
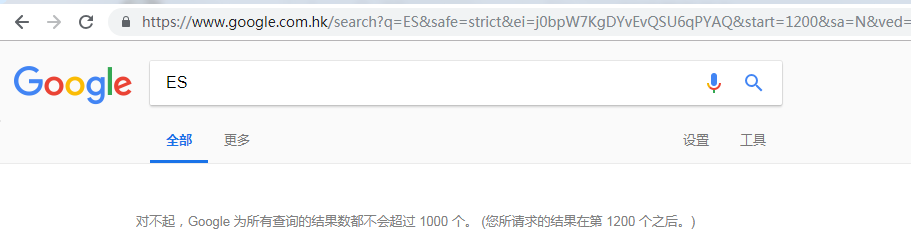
我發現Google提示:Google為所有查詢的結果數都不會超過1000,然後我迅速嘗試了百度和微軟的BING:


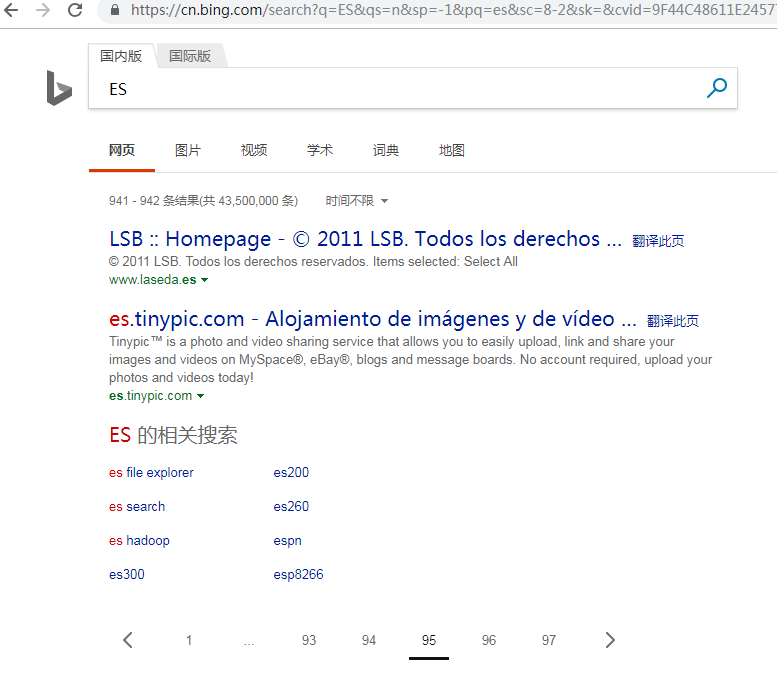
百度只顯示76頁,當修改url時,76頁以外的也不會顯示,這時候會跳到第一頁,微軟BING只會顯示97頁,當你繼續下一頁時它會回退當前頁的前一頁,這時候我重新查閱了ES分頁遍歷相關資料,這種from/to的方式採用的是深度分頁機制,並且目前所有分散式搜尋引擎都存在深度分頁的問題。
ES深度分頁:
由於資料是分散儲存在各個分片上的,所以ES會從每個分片上取出當前查詢的全部資料,比如from:9990,size:10,ES會在每個分片上取10000個document,然後聚合每個分片的結果再排序選取前10000個document;所以當from的值越來越大,頁數越來越多時,ES處理的document就越多,同時佔用的記憶體也越來越大,所以當資料量很大、請求數很多時,搜尋的效率會大大降低;所以ES預設max_result_window為10000。
所以如果要使用from/size的方式分頁遍歷,最好使用ES預設的max_result_window,可以根據自己的業務需求適當增加或減少max_result_window的值,但是建議以跳頁的方式分頁最好控制頁數在1000以內,max_result_window的值最好不要修改。
二. Mapping設定與Query查詢優化問題
在ES中建立Mappings時,預設_source是enable=true,會儲存整個document的值,當執行search操作的時,會返回整個document的資訊。如果只想返回document的部分fields,但_source會返回原始所有的內容,當某些不需要返回的field很大時,ES查詢的效能會降低,這時候可以考慮使用store結合_source的enable=false來建立mapping。
PUT article_index
{
"mappings": {
"es_article_doc":{
"_source":{
"enabled":false
},
"properties":{
"title":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword"
}
},
"store":true
},
"abstract":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword"
}
},
"store":true
},
"content":{
"type":"text",
"store":true
}
}
}
}
}
可以設定_source的enable:false,來單獨儲存fields,這樣查詢指定field時不會載入整個_source,通過stored_fields返回指定的fields,並且可以對指定field做高亮顯示的需求:
GET article_index/_search
{
"stored_fields": [
"title"
],
"query": {
"match": {
"content": "async"
}
},
"highlight": {
"fields": {
"content": {}
}
}
}
使用store在特定需求下會一定程度上提高ES的效率,但是store對於複雜的資料型別如nested型別不支援:
# nested型別
PUT article_index_nested
{
"mappings": {
"es_article_nes_doc": {
"properties": {
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"comment": {
"type": "nested",
"properties": {
"username": {
"type": "keyword"
},
"content": {
"type": "text"
}
}
}
}
}
}
}
新增資料:
PUT article_index_nested/es_article_nes_doc/1
{
"title": "Harvard_fly 淺談 ES優化",
"comments": [
{
"username": "alice",
"date": "2018-11-13",
"content": "aaa"
},
{
"username": "bob",
"date": "2018-11-12",
"content": "bbb"
}
]
}
這種nested型別的store就不支援了,只能通過_source返回資料,如果需要返回指定field可以在search中通過_source指定field:
GET article_index_nested/_search
{
"_source": ["title","comments"],
"query": {
"bool": {
"must": [
{
"match": {
"comments.username": "alice"
}
},
{
"match": {
"comments.content": "aaa"
}
}
]
}
}
}
三. ES讀寫優化問題
ES讀效能的優化主要是查詢的優化,在查詢中儘量使用filter,如果遇到查詢慢可以使用explain進行慢查詢,進而優化資料模型和query;對於ES的寫優化,最好採用bulk批量插入,下面以python的api作為例子說明:
def bulk_insert_data(cls, qid_data_list):
"""
批量插入試題到ES庫
:param qid_data_list: qid ES結構列表
:return:
"""
if not isinstance(qid_data_list, (list, )):
raise ValueError('qid_data_list資料結構為列表')
es = connections.get_connection()
index_name = cls._doc_type.index
doc_type_name = cls.snake_case(cls.__name__)
def gen_qid_data():
for dt in qid_data_list:
yield {
'_index': index_name,
'_type': doc_type_name,
'_id': dt['qid'],
'_source': dt
}
bulk(es, gen_qid_data())
使用bulk批量插入資料到ES,在Python中bulk位於elasticsearch.helpers下,但是使用bulk並不是一次插入的資料量越大越好,當一次插入的資料量過大時,ES的寫效能反而會降低,具體跟ES硬體配置有關,我測試的一次插入3000道試題詳情資料會比一次2000道速度慢,3000道試題詳情大約30M左右。
如果追求寫入速度,還可以在寫入前將replicas副本設定為0,寫入完成後再將其設定為正常副本數,因為ES在寫入資料時會將資料寫一份到副本中,副本數越多寫入的速度會越慢,但一般不建議將replicas副本設定為0,因為如果在寫入資料的過程中ES宕機了可能會造成資料丟失。
四. ES配置優化問題
在ES的叢集配置中,master是ES選舉出來的,在一個由node1、node2、node3組成的叢集中初始狀態node1為主節點,node1由於網路問題與子節點失去聯絡,這時候ES重新選舉了node2為主節點,當node1網路恢復時,node1會維護自己的叢集node1為主節點,這時候叢集中就存在node1和node2兩個主節點了,並且維護不同的cluster state,這樣就會造成無法選出正確的master,這個問題就是腦裂問題。
腦裂問題的解決辦法(quorum機制):
quorum計算公式:quorum = 可選舉節點數/2 + 1
只有當可選舉節點數大於等於quorum時才可進行master選舉,在3個可選舉節點中,quorum=3/2+1=2 在node1失去網路響應後 node2和node3可選舉節點為2 可以選舉,當node1恢復後,node1只有一個節點,可選舉數為1,小於quorum,因此避免了腦裂問題;即設定discovery.zen.minimum_master_nodes:quorum,可避免腦裂問題