
Spring Cloud Data flow
Spring Cloud Data Flow 介紹
1.Data flow 是一個用於開發和執行大範圍資料處理其模式包括ETL,批量運算和持續運算的統一程式設計模型和託管服務。
2.對於在現代執行環境中可組合的微服務程式來說,spring cloud data flow是一個原生雲可編配的服務。
使用spring cloud data flow,開發者可以為像資料抽取,實時分析,和資料匯入/匯出這種常見用例建立和編配資料通道 (data pipelines)。
3.Spring cloud data flow 是基於原生雲對 spring XD的重新設計,該專案目標是簡化大資料應用的開發。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
特點
1.使用DSL,REST-APIs,Dashboard,和 drag-and
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
架構
Spring cloud data flow 簡化了應用程式的開發和部署 將精力集中到資料處理的用例上
主要的架構概念在 應用程式、data flow 伺服器和目標執行環境上
應用程式有兩個特點:
1.週期長的流處理,程式通過訊息中介軟體消費和產生連續不斷的資料
2.短週期的任務處理,程式處理有限的資料集合然後中斷
- 1
- 2
- 3
取決於執行環境,應用程式可以有兩種打包方式
1.spring boot 打成jar包可以託管在一個maven倉庫,檔案,http或者是其他spring資源實現
2.Docker
- 1
- 2
- 3
執行環境支援:
Cloud Foundry
Apache YARN
Kubernetes
Apache Mesos
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Local Server for development
部署商提供了服務介面可以允許你拓展到其他平臺(Docker Swarm)。
Data flow server 負責部署應用程式到執行環境。Data flow server為執行環境提供一個可執行的jar包。
- 1
- 2
- 3
- 4
Server主要職能
1.stream DSL(領域特定語言)用來描述多個應用資料流的流轉邏輯
2.部署清單 用來描述應用程式在執行環境的對映(初始化例項數量,記憶體配置,資料分割槽)
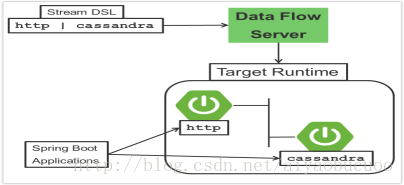
多個應用之間的互動是通過訊息來實現的
支援的訊息中介軟體:
1.Apache Kafka
2.RabbitMQ
微服務的架構風格
- Data flow server部署應用程式到目標執行環境遵從一致的微服務架構風格。
- 舉例來說,流應用代表了高級別的應用程式 它由多個分別執行在自己程序的小微服務程式組成。每個微獨 立於其他微服務進行擴充套件或者縮減,每個服務有自己的版本控制生命週期
- Streaming 和 task都是基於微服務將spring boot作為基礎類庫。它讓所有的微服務都支援像健康檢查,安全,可配置日誌,監控和管理以及打包可執行JAR包
對比其他架構平臺:
- Spring Cloud Data Flow的架構風格不同於其他流處理和批處理平臺。例如Apache Spark,Apache Flink,和Google Cloud Dataflow 應用程式執行在特定的計算引擎叢集裡。
- 相比Spring Cloud Data Flow,這些計算引擎原生的給平臺提供一個豐富的環境去執行復 雜的資料運算,但是在別的執行環境引入複雜性,往往是不需要的。這不意味著你用 Spring Cloud Data Flow 就不能做實時資料計算。
- 類似的,Apache Storm,Hortonworks DataFlow 和Spring Cloud Data Flow的前身,Spring XD,都指定了程式執行叢集,每個產品的獨特性,決定了你的程式碼要在平臺上執行並進行健康檢查確保長週期應用在執行失敗的時候可以重新啟動。通常,我們為了能正確的嵌入到叢集執行框架需要實現框架指定介面。
流處理應用
- 然而Spring boot 為建立DevOps(開發運維)友好的微服務提供了基礎,在spring生態系統中其他類庫幫助我們建立基於微服務的流處理程式。其中特別重要的是Spring Cloud Stream。
Spring Cloud Stream 程式設計模型本質是為我們提供簡單的方式去描述一個基於訊息中介軟體的通訊的多輸入輸出應用程式。這些輸入輸出對映到kafka的topics 或者是 rabbitMq 的 exchange 和 queue上。通常程式配置會作為類庫一部分提供一個source用來生成資料,一個process 用來消費和生產資料,一個sink來消費資料。
1.指令式程式設計模型
Spring Cloud Stream 是最緊密的整合了 Spring Integration 的命令事件模型。
這意味著你寫程式碼去處理一個單一的事件回撥@EnableBinding(Sink.class) public class LoggingSink { @StreamListener(Sink.INPUT) public void log(String message) { System.out.println(message); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在例子中字串訊息來自輸入頻道,傳送到log方法,@EnableBinding 註解是 用來將外部訊息中介軟體跟輸入頻道結合起來。
2.功能程式設計模型
Spring Cloud Stream 可以支援其他的程式設計風格。使用反應式api傳入傳出的資料被處理為持續的資料流,它還定義瞭如何去處理獨立的訊息。你也可以使用運算子去描述從入站到出戰資料流的功能性轉變。在未來的版本將會支援Apache Kafka的KStream API的程式設計模型。
流
- a)拓撲結構
Stream DSL 描述了系統中資料流轉送的線性序列。例如,在stream定義中 http | transfomer | cassandra ,每一個管道符表示連結左右的應用程式.命名的頻道可以用來路由或者分發資料到多個訊息定義。 - b) 併發性
程式會消費事件,Spring Cloud Stream暴露一個併發性設定去控制用來派發傳入訊息的執行緒池的大小 - C) 分割槽
在資料處理中存在一個通用的模式,將程式間傳送的資料進行分割槽。分割槽在狀態式處理中是很重要的一個概念,無論是效能還是一致性的原因,都要保證所有相關資料在一塊處理。
Spring Cloud Data Flow可以通過配置Spring Cloud Stream的輸出輸入的繫結來支援分割槽。Spring Cloud Stream 提供了一個通用的方式,用於將不同型別的中介軟體以統一的方式進行分割槽處理的用例。因此無論代理是否進行分割槽,都可以實現分割槽。
在Spring Cloud Data Flow中使用簡單的分割槽策略,你只需要在部署stream的時候在stream中設定每個程式的例項數量和 partitionKeyExpression 生產者屬性。partitionKeyExpression 識別在中介軟體上的訊息的哪一部分用來作為key。一個數據抽取Stream可以定義成 http | averageprocessor | cassandra. 假定要傳送給 http source的負載是一個json格式並且有一個欄位名字叫 sensorId.用shell命令部署stream stream deploy ingest –propertiesFile ingestStream.properties 。內容為:
Deployer.http.count=3
Deployer.averageprocessor.count=2
app.http.producer.partitionKeyExpression=payload.sensorId
將會部署流,所有的資料按照配置的輸入輸出目標流過程式,而且保證獨立的資料集合總是被運送到對應的average processor例項。
在這種情況下,預設演算法是評估payload.sensorId%partitionCount,其中partitionCount是RabbitMQ的情況下的應用程式計數,以及Kafka情況下的主題的分割槽計數 - D) 訊息交付保證
streams是由使用spring Cloud Steam類庫作為與底層訊息中介軟體通訊的基礎的程式所組成的。Spring cloud stream 會提供多個供應商的訊息中介軟體進行選擇配置。
在spring cloud stream 中binder是對程式跟中介軟體連結的抽象。
對消費應用來說,在訊息處理過程中產生異常會有一個重試的策略。
Spring cloud stream 還支援一個為kafka 和rabbitmq binder實現的配置項,會將失敗的訊息和堆疊蹤跡傳送到一個死信佇列
其他的訊息交付保證是由供生產消費應用選擇的訊息中介軟體提供的。
分析
- Spring Cloud Data Flow 瞭解到某些Sink應用程式會將計數資料寫入到redis並且提供一個讀取計數資料的REST端。計數器的型別支援:
- Counter 計數接收的訊息數量,可選擇的將計數資料記錄到分離的倉庫中例如redis
- Field Value Counter 計算訊息有效內容中指定欄位的唯一值得出現次數
- Aggregate counter 儲存總計數而且還會記錄每分鐘 每小時 每天 每月的總計數
重要的是要注意,聚合計數器中使用的時間戳可以來自訊息本身的一個欄位,所以無序的訊息也可以被統計
Task應用程式
Spring Cloud Task 程式設計模型提供:
1.Task生命週期時間的持久化和退出狀態碼
2.生命週期鉤子函式在任務執行前後執行
3.在任務週期中發出一個task事件到一個Stream
4.與Spring Batch Job整合
- 1
- 2
- 3
- 4
- 5
Data Flow Server
1.端
Data Flow Server使用一個嵌入式的servlet容器並且暴露REST端去建立,部署,解除安裝,銷燬Streams和Tasks,查詢執行狀態,資料分析等等。
Data Flow Server的實現是使用spring mvc框架和遵從HATEOAS原則的spring HATEOAS庫去建立REST表現
2.定製化
我們提供一個可執行的Data Flow Server jar包指向一個單一的執行環境。Data Flow Server 委託到ClassPath去尋找部署商的SPI實現。
雖然我們為每一個目標執行環境提供了一個可執行jar的伺服器,
你也可以使用spring initialzr建立你自己的定製化伺服器這可以讓你在我們提供的可執行jar包新增或刪除相關功。
3.安全
Data Flow Server 可執行jar包支援基於http, LDAP(S), File-based, and OAuth 2.0 authentication 的方式去訪問他。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
執行環境
1.容錯
Data Flow支援的所有執行環境都應該有在失敗後重啟應用的能力。
Spring Data Flow在部署程式的時候設定執行環境的健康檢查無論如何都是需要的。
應用的集合狀態構成了stream的狀態。如果一個程式失敗了,stream的狀態將由deployed變成 partial
2.資源管理
每一個執行環境允許你控制分配給每個程式的記憶體硬碟和CPU。
這個是通過每個執行環境中使用唯一關鍵名稱的部署清單的配置檔案。
3.執行時擴充套件
部署stream時,你可以為組成Stream的獨立的應用設定例項的數量。
Stream部署後,每個目標執行環境允許你控制個別的應用的例項的數量。
使用APIs,UIs或者是命令列工具,你可以根據需要為執行環境擴充套件或者是減少例項數量。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12