
儲存系統科普——單機引擎介紹
簡介
該篇blog只是儲存系列科普文章中的第三篇,所有文章請參考:
在工程架構領域裡,儲存是一個非常重要的方向,這個方向從底至上,我分成了如下幾個層次來介紹:
- 硬體層:講解磁碟,SSD,SAS, NAS, RAID等硬體層的基本原理,以及其為作業系統提供的儲存介面;
- 作業系統層:即檔案系統,作業系統如何將各個硬體管理並對上提供更高層次介面;
- 單機引擎層:常見儲存系統對應單機引擎原理大概介紹,利用檔案系統介面提供更高級別的儲存系統介面;
- 分散式層:如何將多個單機引擎組合成一個分散式儲存系統;
- 查詢層:使用者典型的查詢語義表達以及解析;
本文主要介紹單機引擎層的一些知識。
單機儲存引擎
單機儲存引擎主要是指在單機內部提供一個儲存介質的介面, 對於儲存量不大的需求來說, 一般來說使用單機儲存就夠了, 頂多再多加一個副本作為備份儲存, 類似Mysql的Master/Slave儲存機制。
對於資料量比較大的系統而言, 就需要對資料做拆分並放不到不同的機器上, 單機儲存引擎會是其基本組成元件。關於分散式儲存如何組織我們會在下一篇文章中描述, 本文主要描述單機儲存引擎相關技術。
基本技術點
對於單機儲存引擎而言, 主要考慮點如下:
-
索引組織方式
索引組織方式比較簡單, 主流就兩種方式:
-
hash
-
要點:
hash本身就不用多做介紹了, hash對應的key就是儲存主鍵, value是對應了該key對應資料的儲存位置資訊。不過hash演算法本身也會有如下一些考慮, 回頭筆者再另起文章介紹hash相關知識:
- hash函式選擇
- hash衝突解決
- hash桶大小選擇
- 好處:
- 隨機查詢效率很高
- 壞處:
- 儲存總量受硬碟限制
- 無法順序查詢
-
-
B+樹
-
要點:
B+樹的組織和查詢原理類似二分查詢(類似的演算法還有跳錶), 將所有key按照順序組織, 然後將其分成若干段, 每個段對應上一層節點, 餘此類推直到根節點。其資料組織原理如下: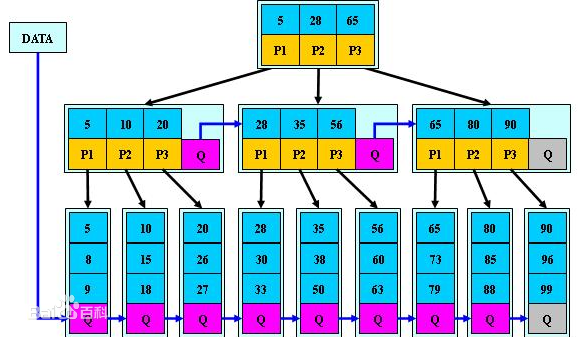
B+樹演算法本身主要考慮兩個引數:
- 樹的高度
- 子節點個數
- 好處
- 可以順序查詢
- 可以考慮有選擇性的將部分資料儲存在硬碟上, 從而增加單機儲存總量
- 壞處
- 查詢效率不如hash函式, 跟樹的高度相關
- 隨著資料更新, B+樹有一定的維護成本
-
-
-
資料組織方式
資料組織方式又分成記憶體儲存還是磁碟儲存。
記憶體儲存主要考慮記憶體管理和分配演算法, 以及讀寫一致性對效能的影響, 這個會在講例項引擎的時候詳解。
磁碟儲存首先考慮行存和列存, 主流儲存引擎中兩者都有, 下面對比一下兩者的好處壞處。
- 行存:
- 要點:
將一行資料連續儲存在磁碟上。典型代表是leveldb, Mysql的innodb。 - 好處
- 所有列資料組織在一起, 查詢整行資料的時候會減少磁碟尋道次數
- 主鍵索引對應附加儲存消耗會較少
- 壞處
- 難以增加, 刪除, 修改列, 即修改schema代價很大
- 為主鍵以外的列建立索引代價較大
- 要點:
- 列存
- 要點
將同一列所有資料連續儲存在磁碟上。典型代表是BigTable/HBase, Cassandra。 - 好處
- 有利於查詢部分列, 尤其是單列查詢, 減少IO消耗
- 有利於資料按列聚合函式計算, 如max, sum等操作
- 易於增加, 刪除, 修改列
- 易於為單獨列建立索引
- 一般來說, 有利於壓縮演算法
- 壞處
- 查詢全行資料效能損耗較大
- 主索引所需要的附加儲存消耗會變大
- 要點
其實像BigTable, HBase這樣的儲存引擎也並非儲存的列儲存引擎, 而是提供行列式儲存介面, 然該使用者自己組織哪些欄位按行存, 哪些欄位按列存。
上面大概介紹了一下單機儲存引擎的資料組織, 在確定了基礎資料組織方式之後, 單機儲存引擎更重要的是在此之上考慮資料一致性, 讀寫效能, 容錯容災等事宜。
下面會以幾個比較常見的例子來介紹這些點。
- 行存:
leveldb
LevelDB是一個Google提供的單機引擎庫, 提供KV儲存介面, 該庫採用了LSM的儲存機制, 適用於多寫少讀的使用場景。
下面我們描述一下LevelDB的原理, 因為其主要設計為寫流量很大的場景, 所以我們來看其寫入邏輯。
當需要寫入一個<key,value>對的時候, 操作很簡單, 只需要將key,value內容寫入備份日誌中, 先寫日誌是為了容災, 然後就將key和value寫入記憶體, 記憶體資料結構為skiplist(跳錶, 跟B+樹類似, 全域性有序)。
但是這樣肯定不夠, 因為這樣其實就變成一個記憶體儲存引擎(比如Memcache)了, 而LevelDB是一個支援很大資料量的儲存引擎, 大部分資料都存在硬碟上的。而如果資料一直存記憶體的話, 記憶體就無限制膨脹最終導致記憶體爆掉了。那麼為了避免記憶體爆掉, LevelDB做的事情也很簡單, 就是當記憶體漲到超過某個閾值之後, 就將其往硬碟上同步, 同步到磁碟的檔案也是按key有序組織的, 後續這部分資料就在磁碟上的檔案中查詢。
同步到磁碟上是一個需要時間的過程, 那麼這段時間如果在有寫請求過來應該怎麼處理呢, 也很簡單, 新的寫資料就寫到一個新的記憶體塊當中, 原來這塊記憶體保證只讀不寫即可, 等資料完全同步到磁碟上之後, 這塊記憶體其實就可以刪掉了, 但是為了查詢效率, 一般都是等到下次需要記憶體的時候才刪掉這塊記憶體。
那麼又有問題了, 如果正在同步的這塊記憶體塊中的某個key又有一個新的寫請求來更新這個key的內容或者刪除, 那麼記憶體中就有兩份該key的值了,會不會造成讀混亂呢? 不會,LevelDB實現也很簡單, 就是保證讀的時候的查詢順序即可, 先查詢當前正在讀寫的記憶體塊, 如果沒有查詢到結果才查詢正在或者已經同步到磁碟上的這塊記憶體塊,因為正在讀寫的這塊記憶體塊中的值一定比只讀不寫的這塊記憶體要新。但是這個對刪除不work, 所以在LevelDB中刪除並不是真正的刪除, 只是相當於有一個特殊的值代表刪除, 其落地也相當於是一個更新。
到目前為止, 記憶體塊相關的邏輯就基本搞清楚了, 接下來細心的同學肯定會問了, 看起來每隔一段時間就會往硬碟上生成一個檔案, 那麼是不是每次查詢很有可能都需要查詢好多個檔案, 如果是這樣的話, 那麼一方面是會有很多歷史無效資料佔據空間浪費空間, 另一方面更要命的是LevelDB的讀取效能肯定非常低。所以LevelDB也採取了辦法, 不是一直往磁碟上寫檔案就不管了, 而是定期將檔案進行合併, 確保磁碟檔案個數控制在一定範圍之內。
那麼合併是怎麼個合併法呢, 在什麼樣的條件下合併, 誰跟誰合併呢? 首先來看看觸發條件, 觸發條件很簡單, 就是檔案個數超出某個閾值的時候就會觸發合併; 誰跟誰合併呢, 首先在當前所有沒合併的檔案中挑一個出來做合併(挑選方式是round-robin), 然後跟之前所有已經之前合併過的檔案進行再次合併, 已經合併過的檔案再單獨放一個目錄, 每一個這樣的目錄就叫一層, 這也是LevelDB取名的由來。查詢的時候先查詢記憶體, 再查詢第0層的所有檔案(即沒經過任何合併操作的檔案), 如果沒查到再查詢合併過後的第1層的檔案。如果第1層的檔案經過多次合併過後太多了, 就會再建立第2層, 將第1層的檔案跟第2層合併, 如此類推。
可以看到, 在查詢第0層檔案的時候, 可能同一個key會查詢多個檔案, 在查詢後面層的時候, 每一層最多隻需要查詢一個檔案即可。而LevelDB的查詢效能並不算高效, 因為可能一次查詢會涉及到多次檔案的IO。而且本文還沒有講單個檔案內部組織, 就確定某個key已經落到某個檔案之後, 也都還需要多次IO才能將key的內容給讀出來。
memcache
memcache內部就是一個hash<key, value>的結構, 首先會有一個hashmap來儲存key以及value對應的指標。
而value對應的真正儲存空間的管理, 最簡單的方式就直接用核心提供的malloc和free函式來操作, 但是隨著不同大小的空間塊的增加和刪除而導致不停增加記憶體碎片, 導致新空間可能無法申請, 且記憶體管理效率降低。
典型的核心用來降低記憶體碎片的演算法就是夥伴演算法, 這裡我們不做詳解, memcache並沒有使用夥伴演算法, 而是使用了一個類似夥伴演算法但是更高效不過可能浪費空間更多的演算法。
該演算法原理如下, 首先確定一系列空間大小數字, 來代表基本申請和分配的單元格大小, 比如104位元組, 136位元組, 224位元組...等。後續申請空間大小都按照這個size來分配, 避免記憶體碎片。
具體按照哪個size, 就看value值大小, 取大於value值的最小的那個值, 這樣浪費的空間最少。
然後為了避免頻繁從作業系統中申請空間, 每次都至少申請一個連續大小的空間(預設1M), 然後將其按照某個單元格大小切分, 下次如果再有相同大小單元格的需求, 先從已經分配的空間中看是否有剩餘塊, 如果有則直接用, 否則再重新申請一個1M的空間再分配。
根據這個演算法引出如下幾個概念:
- Page: 即剛才說的連續大小的空間(預設1M), 作為memcache問作業系統申請空間的基本單元;
- chunk: 即每個單元格
- slab: 即同樣單元格大小的集合