
儲存系統科普——硬體層介紹
https://www.cnblogs.com/xuanku/p/io_hardware.html
簡介
該篇blog只是儲存系列文章中的第一篇,所有文章請參考:
在工程架構領域裡,儲存是一個非常重要的方向,這個方向從底至上,我分成了如下幾個層次來介紹:
- 硬體層:講解磁碟,SSD,SAS, NAS, RAID等硬體層的基本原理,以及其為作業系統提供的儲存介面;
- 作業系統層:即檔案系統,作業系統如何將各個硬體管理並對上提供更高層次介面;
- 單機引擎層:常見儲存系統對應單機引擎原理大概介紹,利用檔案系統介面提供更高級別的儲存系統介面;
- 分散式層:如何將多個單機引擎組合成一個分散式儲存系統;
- 查詢層:使用者典型的查詢語義表達以及解析;
主機板結構
在進入對硬體層的分析前,讓我們來看看電腦主機板上各個原件之間的關係。

圖1展示了主機板上主要元件的結構圖,以及他們之間的匯流排連線情況。核心連線點是北橋和南橋兩塊晶片。
其中北橋比較吊,連線的都是些高速裝置。一般來說只連線CPU,記憶體和顯示卡幾種裝置。不過近些年也出現了PCIE2.0的高速介面接入北橋,使得一些符合標準的裝置就可以接入北橋。
而南橋就相對搓了,他負責接入所有低速裝置。什麼USB,滑鼠,磁碟,音效卡等等都是接在南橋上的。而不同的裝置用途和協議都有很大不同,所以設計了不同的互動協議。由於歷史原因,不同裝置傳輸介質可能都不一樣,導致總線上佈線十分複雜。所以到目前為止,主流裝置都已經統一成為了PCI匯流排,大家一起用這條匯流排。
讀寫過程
我們來模擬一下CPU要從磁碟讀入一份資料的過程:
-
CPU發出一條指令說哥要準備讀資料了
這條指令依次通過系統匯流排,橋間匯流排,PCI匯流排傳遞到了磁碟控制器。控制器收到指令了之後知道這是一次讀請求,且讀完了是否要發中斷的資訊。做好一些準備工作,等待讀取資料。
-
CPU再發出一條指令說要讀取的邏輯地址
這條指令還是通過系列匯流排發給磁碟控制器之後。磁碟控制器就忙活了,查詢邏輯快對應的物理塊地址,查詢,尋道等工作,就開始讀取資料了。
-
CPU再發出一條指令說讀入記憶體的地址
當收到這條指令之後,CPU就不管了,他告訴一個叫DMA的總管,說接下來就靠你了。DMA裝置會接管匯流排,負責將磁碟資料通過PCI匯流排,橋間匯流排,記憶體匯流排同步到記憶體指定位置。
寫操作的過程是類似的,就不累述了。
上面我們只是講解了在主機板上資料流轉的過程,但是還有一個黑盒,就是磁碟控制器。這哥們到底是怎麼管理的各個磁碟呢?在下一節我們將為你描述。
儲存介質原理
上面講了計算機讀取資料的過程。這一章我們來大概說一下常見的儲存介質的儲存原理。
磁帶
磁帶就跟小時候聽歌的時候的磁帶類似。一條黑色帶子上面有很多小的磁性粒子,根據粒子的南北級來判定0/1。
軟盤
軟盤比磁帶要先進一點,記錄資料的原理是一樣的,只是可以隨機讀取,而磁帶只能順序讀取。
硬碟
硬體原理
如果說前兩個都是古老的東西,技術含量一般的話。硬碟就是一個很有技術含量的儲存裝置了,主要包含三大裝置:
-
電機
電機的目的是控制磁臂精準定位到磁軌,一個磁軌可能很小,要精準定位到哪個地方是高科技。
-
盤面
盤面主要有兩點。一點是基板要足夠光滑平整,不能有任何瑕疵;一點是要將磁粉均勻的鍍到基板上。這裡有兩個高科技,一個是磁粉的製造,一個是如何均勻的鍍到基板上。
-
磁頭
磁頭的主要難點是要控制好跟盤面的距離,跟軟盤類似,硬碟也是通過修改磁粉的南北極來記錄資料的。如果隔得太遠,就感知不到磁性資料了,隔得太近呢,又可能把盤面刮到。當然0/1的表示並不是只有一個磁粉,而是一片區域的磁粉。
現在磁碟都是利用空氣動力學,將磁頭漂浮在盤面上面一點距離來控制磁頭和盤面的距離。但是當硬碟停止工作不轉的時候,磁頭就肯定掉在盤面上了,所以一般盤面靠近圓心的地方一般都有一塊沒有磁粉的地方,用於安全停靠磁頭。當硬碟要開始工作的時候,磁頭在同心圓裡面起飛,飛起來了之後再移動到其他地區。
不過我一直在想,是否可以有這樣的技術,能在磁臂上裝多個磁頭,每個磁軌對應一個,停止工作的時候就把磁臂固定在某個高度讓他不挨著盤面,這樣是不是能大大提高硬碟的讀寫效率,因為這樣減少了尋道的時間。
基本概念
硬碟組成原理圖如下:
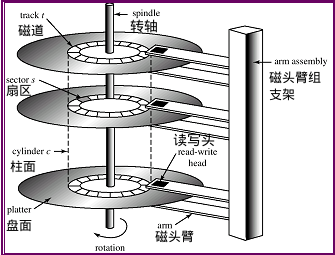
如上圖, 硬碟主要有如下幾個概念(概念比較簡單,就不解釋了):
- 扇區
- 磁軌
- 柱面
讀寫過程
讀寫過程得分成兩頭來說,一頭說將資料從各個盤面中讀取出來;一頭說如何將資料送給計算機。
-
從盤面中讀取資料
我們知道再磁碟中,順序讀取會比隨機讀取快很多,那麼有這麼多盤面,磁軌,這個順序到底是什麼順序呢?
假設我們現在是再順序遍歷磁碟上的資料,那麼讀取順序是這樣的。首先讀完最上面一塊盤面的最外面一個磁軌,等盤面旋轉完一圈之後,即這個磁軌被讀取完畢,然後立即切換到第二塊盤面,讀第二塊盤面的最外面一個磁軌,以此類推,直到讀完最底下一塊盤面。然後磁臂在向內移動一個磁軌,重複剛才的過程,直到讀到最裡面一個磁軌。
其實再讀取過程中還會更復雜一點,因為盤面是一直勻速高速旋轉的,可能在一個扇區過度到下一個扇區的時候,就那麼一點時間,可能存在誤差,導致下一個扇區的資料沒讀到。為了解決這個問題,一般資料是在磁軌上是間隔儲存的。假設一個數據有10個扇區,分別為,d1,d2,...,d10;為了說明這個思想,我們假設一個磁軌正好也有10個扇區,分別為,s1,s2,...s10。如果是緊挨著存放的話,那麼扇區和資料的對應關係為:[(s1,d1), (s2, d2), ... , (s10, d10)]。這樣就存在剛才說的有誤差。那麼間隔儲存的話,對映關係為:[(s1,d1), (s3,d2), (s5,d3), ..., (s2, d10)]。
而且在切換盤面的時候,雖然是電子切換,但是速度還是會有一定延遲,下一個盤面和上一個盤面的起始點位置不能一一對應,也是會有一定錯開的。
在古老的磁盤裡面,這些值可能還需要使用者來設定,不過現在都是廠商給咱們設定好,使用者不需要關心了。
由於磁臂的移動要比盤面的切換要慢很多(一個是機械切換,一個是電子切換),所以為了減少磁臂的移動,所以如上的順序讀取會是先讀一個柱面,再讀取下一個磁軌,而不是先讀完一個盤面,在讀下一個盤面。
那麼既然磁臂的移動如此的慢,剛才講了順序讀取的時候的磁臂移動邏輯。那麼在真實情況下,有大量隨機訪問的情況下,磁臂是如何移動的呢?這裡就需要考慮常見的磁臂排程演算法了:
- RSS:隨機排程。這個就是扯蛋,只是拿來給別人做綠葉對比效能用的。
- FIFO:先進先出。這個對於隨機讀取來說,效能很不友好。
- PRI:交給使用者來管理。這個跟FIFO類似,只不過優先順序是由使用者來指定的,不僅增加了使用者使用磁碟的成本,效率也不見得高。
- SSTF:最短時間排程。這個是指磁頭總是處理離自己這次請求最近的一次請求處理。這樣最大的問題就是會存在餓死的情況。
- SCAN:電梯演算法。在磁碟上往復。這個是比較常見的演算法,跟電梯類似,磁臂就一個磁軌一個磁軌的動,移動最外面或者最裡面的磁軌就轉向。這個演算法不會餓死。
- C-SCAN:類似電梯演算法,只是單向讀取資料。磁臂總是再內圈到外圈的時候讀取資料,當到達外圈過後迅速返回內圈,返回過程中不讀取資料,在重複之前的過程。
- LOOK:類似SCAN,只是會快速返回,如果前面沒有讀寫請求就立即返回。
- C-LOOK:類似C-SCAN和SCAN之間的關係。
一般來說,再IO比較少的情況下,SSTF效能會比較好,在IO壓力比較大的情況下,SCAN/LOOK演算法會更優秀。
大家可以到這裡來看看硬碟讀取資料的視訊:http://v.ku6.com/show/2gl1CHY7iNa_CVLum3NQHg.html
-
將資料送給計算機
剛才我們從磁碟中讀到了資料,接下來我們講解磁碟通過什麼樣的介面跟計算機做互動。這個介面也叫磁碟管理協議。
磁碟管理協議的定義又分成兩部分:軟體和硬體。其中軟體是指指令級,目前指令級就兩個:ATA和SCSI;硬體代表資料傳輸方式,一般都是主機板上的導線傳輸原理,但並不限制,資料甚至可以通過TCP/IP傳輸。定義一個協議需要同時定義了指令級以及硬體傳輸方式。
-
ATA
全稱是Advanced Technology Attachment,現在看起來不咋地,不過從名字看來,當時這個東西還是很高階的。
這個指令是上個世紀80年代提出的。按照硬體介面的不同,又分成了兩類,一類是並行ATA(PATA,一類是序列ATA(SATA)。一開始流行起來的是PATA,也叫IDE。不過由於並行線抗干擾能力太差,排線佔空間,不利電腦散熱。而更高階的SATA協議自從2000年被提出之後,很快PATA/IDE介面的磁碟就被歷史淘汰,目前的ATA介面的磁碟只有SATA磁碟了。
-
SCSI
全稱是Small Computer System Interface。也是上個世紀80年代提出來的,當時設計他的目的就是為了小型伺服器設計的磁碟互動介面。用該介面可以達到更大的轉速,更快的傳輸效率。但是價格也相對較高。
所以目前基本上在伺服器領域SCSI磁碟會比較多,在PC機領域SATA硬碟會比較多。不過隨著SATA盤的進化以及其得天獨厚的價格優勢,在伺服器領域SATA也在逐步侵蝕SCSI的市場。
不過SCSI也不會坐以待斃,他按照PATA進化成SATA的思路,自己也搞序列化,進化出來了SAS(Serial Attach SCSI)介面。這個介面目前很對市場胃口,不僅價格低廉,而且效能也還不錯。所以估計SATA淘汰PATA的一幕在不久的將來也會在SCSI領域裡上演。
SCSI指令還可以通過Internet傳輸(iSCSI),通過FC網路傳輸(FC-SCSI),這些我們會再後文提及。
-
ssd
硬體原理
ssd是近些年才火起來的儲存介質。ssd一般有兩種,一種利用flash快閃記憶體為晶片,另一種直接用記憶體(DRAM)作為儲存介質,只是在裡面加了個電池,在斷電以後還能繼續用電池來維持資料。
我們本文中講的ssd全部是都指代前者,即用flash快閃記憶體做儲存介質。先來看一下ssd的儲存原理。
在磁碟中0/1的表示是用的磁粉的南北極的資訊,在快閃記憶體中則用的是電子訊號。他利用的是一種叫浮動門場效應電晶體作為基本儲存介質。在該電晶體裡面,主要是由兩個閘電路構成:控制門和浮動門。在兩個門之間有一堆電子。當控制門加上一個電勢的時候,電子就往浮動門那邊跑,然後控制門斷開電勢,電子會儲存在浮動門那邊(靠中間的二氧化矽絕緣層),則代表二進位制中的0;控制門加一個反向電勢的時候,電子跑回到控制門這邊,浮動門那邊沒電子,代表二進位制中的1。這樣就通過檢測浮動門那邊的電勢就能得到0或者1。而且現在有的ssd製造商,根據不同的電勢,將一個電晶體表示的值從0/1拓展到0/1/2/3。這樣就使得儲存容量翻倍。這種型別的電晶體叫MLC(Multi Level Cell),相對,只表示0/1的叫SLC(Single Level Cell)。不過一般而言,MLC的出錯率也高很多,所以目前市面上主流產品還是SLC的。
瞭解了ssd的基本原理之後,我們來看看ssd是怎麼組織這些電晶體的。看如下幾個概念:
- Page。一般一個Page為4K。則該Page包含4K*8個電晶體,Page是ssd讀寫的最小單元;
- Block。一般128個Page組成一個Block,Block的概念非常重要,讀寫資料的控制都是針對Block的,待會我們再重點講一下Block的概念;
- Plane。一般2048個Block組成一個Plane;
- 一塊晶片再包含多個Plane,多個Plane之間可以並行操作。
Block的組織,見下圖:
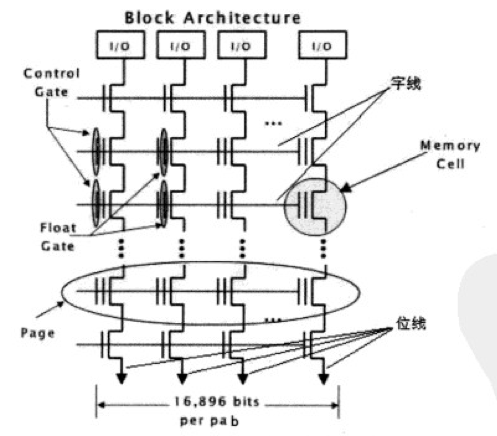
如圖2,可以看到block中的電晶體是按照井字型組織的。一橫排就代表一個Page,所以一個Block一般就有128行,4K*8列。當然,由於還需要針對每個Page加一些糾錯資料,所以一般還會多一些列。
橫排是控制線,負責給電壓,來做充電放電的作用;豎排是讀取線,負責讀浮動門裡的電勢之用。
讀寫過程
讀取的過程是這樣的:
假設要讀取第三行資料,那麼會給第三行控制線的電勢置位0,其他127行控制線都會給一個電勢,這樣就能保證再豎排的讀取線上只讀到第三行的資料,而讀不到其他資料。可以看到ssd再讀取資料的時候不再需要尋道這些複雜的事情,速度會比傳統的磁碟塊很多。
而ssd寫入就比較麻煩了,因為ssd無法再一個block內對部分cell充電,對部分cell放電,這樣訊號會相互干擾從而造成不可預期的情況發生。那ssd怎麼處理這個問題呢,那就暴力了,把一個block的資料全部讀到ssd自帶的記憶體當中,並做好修改,接下來把整個block全部放電,即擦除所有資料,最後再將記憶體中整個block寫回。可以看到,即使是隻修改一個bit的資料,也需要大動干戈,倒騰4K*128這麼多資料,所以ssd寫資料的代價是很大的。但是瘦死的駱駝比馬大,比起機械硬碟,還是要快好幾個數量級的。
而且,ssd還有一個很頭疼的問題,就是隨著充放電次數的增加,中間的二氧化矽絕緣層絕緣效果會逐步降低,當降低到一定程度之後浮動門儲存不住電子了的話,這個電晶體就算廢了。所以單個電晶體還有擦寫次數壽命,目前主流的電晶體這個上限大概是10萬的數量級。而MLC的更差,只有1萬次左右。
那麼針對如上兩個問題,ssd目前一般都有哪些解決方案來應對呢?
- 為了優化寫的時候的效能,一般ssd並不在寫的時候做擦除。而是在寫資料的時候,選擇另外一塊乾淨的block寫資料。對於老的block資料,會做一個標記,回頭定期做擦除工作;
- 對於壞掉的電晶體,可以通過額外的糾錯位來實現。根據不同的糾錯演算法,可以容忍同一個Page中壞掉的位的個數也是不一樣的。如果超過上限,只能報告說不可恢復的錯誤。
常見儲存介質效能數字
最後我們來對比一下目前主流的硬碟和ssd的引數,這是筆者在工作中測試得到的資料,測試資料為各種儲存介質在4K大小下的隨機/順序 讀/寫資料,數字做了模糊化處理,保留了數量級資訊,大家看個大概,心裡有數即可:
| 測試項\磁碟型別 | SATA | SAS | SSD |
| 順序讀(MB/s) | 400 | 350 | 500 |
| 順序寫(MB/s) | 200 | 300 | 400 |
| 隨機讀(IOPS) | 700 | 1300 | 7w |
| 隨機寫(IOPS) | 400 | 800 | 3w |
硬碟組合
上面一節中,我們瞭解了單個磁碟的儲存原理和讀寫過程。在實際生產環境中,單個磁碟能提供的容量和效能還是有限,我們就需要利用一些組合技術將多個磁碟組合起來提供更好的服務。
這一節,我們主要介紹各種磁碟組合技術。首先,我們會看一下最基本的組合技術RAID系列技術;然後,我們在看一下更大規模的整合技術SAN和NAS。
RAID
RAID技術是上個世紀80年代提出來的。
- RAID0:條帶化。讀寫效率都很高。但是容錯很差。
- RAID1:映象儲存。讀效率可達2倍,寫的時候差不多。容錯牛B。
- RAID2 & RAID3:多加一塊校驗盤。在RAID0的基礎之上多了容錯性。RAID2和RAID3的區別是使用了不同的校驗演算法。而且這兩個的校驗是針對bit的,所以讀寫效率很高。
- RAID4 & RAID5 & RAID6:這幾個都是針對block的,所以效率比RAID2&RAID3要更差一些。RAID4是沒有交錯,有一塊盤就是校驗盤;RAID5是有交錯,每塊盤都有資料和校驗資訊;RAID6是雙保險,存了兩個校驗值。
目前用得比較多的就是Raid5和Raid1。
Raid的實現方式一般有兩種:軟Raid和硬Raid。軟Raid是指作業系統通過軟體的方式,對下封裝SCSI/SATA介面的硬碟操作,對上提供虛擬硬碟的介面,中間實現Raid對應邏輯;硬Raid就是一個再普通的SCSI/SATA卡上加了一塊晶片,裡面執行可以執行Raid對應的邏輯。
現在一般的Raid實現方案都是硬Raid,因為軟Raid有如下兩個確定:
- 佔用額外的記憶體和CPU資源;
- Raid依賴作業系統,所以作業系統本身無法使用Raid,如果作業系統對應的那塊硬碟壞了,那麼整個Raid就無法用了;
現在Raid卡一般都比較高階,可以針對插在上面的多塊磁碟做多重Raid。比如這三塊磁碟做Raid5,另外兩塊做Raid1。然後對作業系統提供兩塊『邏輯盤』。這裡的邏輯盤對作業系統而言就是一塊磁碟,但實際底層可能是多塊磁碟。
邏輯盤不一定要佔據整塊獨立的磁碟,同樣RAID的幾塊盤也可以做成多塊邏輯盤。假設有三塊磁碟做成了Raid5,假設一共有200G空間,也可以從中在劃分成兩塊,每塊100G,相當於使用者就看到了兩塊100G的磁碟。不過一般邏輯盤不會跨Raid實現。倒不是不能做,而是沒需求,而且對上層造成不一致的印象:這磁碟怎麼忽快忽慢的呀。
這個邏輯盤還有一個英語名字:LUN(Logic Unit Number),現在儲存系統一般把硬體虛擬出來的盤叫『LUN』,軟體虛擬出來的盤叫『卷』。LUN這個名詞原本是SCSI協議專屬的,SCSI協議規定一條匯流排最多隻能接16個裝置(主機或者磁碟),在大型儲存系統中,可能有成千上萬個裝置,肯定是不夠的,所以發明了一個新的地址標註方法,叫LUN,通過SCSI_ID+LUN_ID來定址磁碟。後來這個概念逐步發展成為所有硬體虛擬磁碟了。
作業系統看到邏輯盤之後,一般還要再做一次封裝。邏輯盤始終都還是硬體層在做的事情,硬體層實現的特點就是效率高,但是不靈活,比如邏輯盤定好了100G就是100G,空間用光了想要調整為150G就只有乾瞪眼了,實現成本很高。為了達到靈活性的目的,所以作業系統還要再做一層封裝『卷管理』。這層卷管理就是把邏輯盤在軟體層再拆分合並一下,組成新的作業系統真正看到的"磁碟"。
最後作業系統再在這些捲上面去做一些分割槽,並在分割槽上安裝作業系統等工作。
磁碟獨立鬧革命
上面都是講的單臺機器內部的磁碟組織方式,而單臺機器所提供的儲存空間是有限的,畢竟機器大小空間是有限的,只能放得下那麼幾塊盤。在一般的2U的機器裡面能放得下20塊盤就算是很不錯的了。在實際工業需求中,對於一些大型應用來說,肯定是遠遠不夠的。而工業界採用的方案就是:堆磁碟,單臺機器裝不下這麼多磁碟就單獨拿一個大箱子來裝磁碟,再通過專線接到電腦介面上。
當然,在近些年又發展起來了一塊新的技術領域大資料儲存的市場——分散式儲存。分散式儲存價格便宜,但是效能較低,佔據了不少不需要太高效能和查詢語義不復雜的市場。分散式儲存我們後面再談,現在先看看堆磁碟這條路。
當磁碟多了之後,人們發現,磁碟容量是上去了,但是傳輸速度還是上不去。預設SCSI的導線傳輸機制有如下幾個限制:
- 規定最多隻能接16個裝置,也就是說一個儲存裝置最多隻能有15臺機器來訪問;
- SCSI導線最長不能超過25米,這對機房佈線來說造成了很大的挑戰;
於是SCSI在一些企業級應用市場開始遭到嫌棄,於是人們就尋求別的硬體解決方案,人們找到了:FC網路。
FC網路是上個世紀80年代研究網路的一幫人搞出來的網路互動方式,跟乙太網是同類產品,有自己完整的一套OSI協議體系(從物理鏈路層到傳輸層以及應用層)。他就是乙太網的高富帥版本,價格更貴,效能更高。而當時FC網路也主要是為了高速骨幹網設計的,人家都沒想到這東西還在儲存系統領域裡面大放異彩。
這裡提一下,FC中的F是Fibre,而不是Fiber。前者是網路的意思,而不是光線。雖然一般FC網路都採用光纖作為傳輸介質,但是其主要定義並不只是光纖,而是一整套網路協議。
但是不管怎麼樣,FC網路的引入,完美解決了SCSI導線的問題:
- FC網路就跟乙太網類似,有自己的交換機,網路連線方式和路由演算法,可以隨便連線多少個裝置;
- 光纖傳輸最大甚至可以有上百公里,也就是說主機在北京,儲存可以在青島;
- 傳輸頻寬更大;
並且只是替換了硬體層的東西,指令集仍然是SCSI,所以對於上層來說遷移成本很低,所以在企業級應用裡得到了廣泛使用。
就目前主流的儲存協議:短距離(機內為主)使用SAS,長距離使用FC。
經過如上的系列技術發展,大規模儲存系統的技術方案也就逐漸成熟了,於是市面上就逐步出現了商業化的產品,其實就是一個帶得有一堆磁碟的盒子,這個盒子我們把它叫做SAN(Storage Area Network)。
說到SAN,就必須要提另外一個概念:NAS(Network Attach Storage)。因為字母都一樣只是換了個順序,所以比較容易混淆。NAS其實就是SAN+檔案系統。SAN提供的還是磁碟管理協議級的介面(ATA/SCSI);NAS直接提供一個檔案系統介面(ext/NTFS)。但是一般來說,SAN都是以FC網路(光纖高速網狀網路)提供給主機的,所以效能高;而NAS一般都是通過乙太網接入儲存系統的,所以效能低。
另外,經常跟SAN和NAS一起的還有另外一個概念,DAS(Direct Attached Storage)。這個跟SAN類似,只是DAS只能被一臺機器使用,而SAN提供了多個介面可以供多個使用者使用。