
【論文速讀】Sheng Zhang_AAAI2018_Feature Enhancement Network_A Refined Scene Text Detector
Sheng Zhang_AAAI2018_Feature Enhancement Network_A Refined Scene Text Detector
作者

關鍵詞
文字檢測、水平文字、Faster- RCNN、xywh、multi-stage
方法亮點
- Feature Enhancement RPN (FE-RPN) :在原來的RPN基礎上增加了兩個卷積分支來增強文字特徵的魯棒性,一個分支通過增加長條形卷積核來提高對長條形文字的檢測能力, 另一個分支利用增加池化和上取樣層等方式來擴大感受野以此提高對文字大小的魯棒性。
- Adaptively Weighted Position-Sensitive RoI Pooling:通過增加ROI pooling的池化網格種類數並取加權平均的方式來保證針對不同大小的文字都能進行自適應的池化。
方法概述
本文方法是對Faster RCNN進行改造,改造的點主要包括對增加RPN卷積的分支、特徵融合時參照HyperNet壓縮中間層特徵、ROI Pooling增加網格種類數並進行加權平均這幾點來檢測水平文字。
方法細節
網路結構
該網路框架是Faster RCNN。主要修改是圖中的四個紅色虛線框。
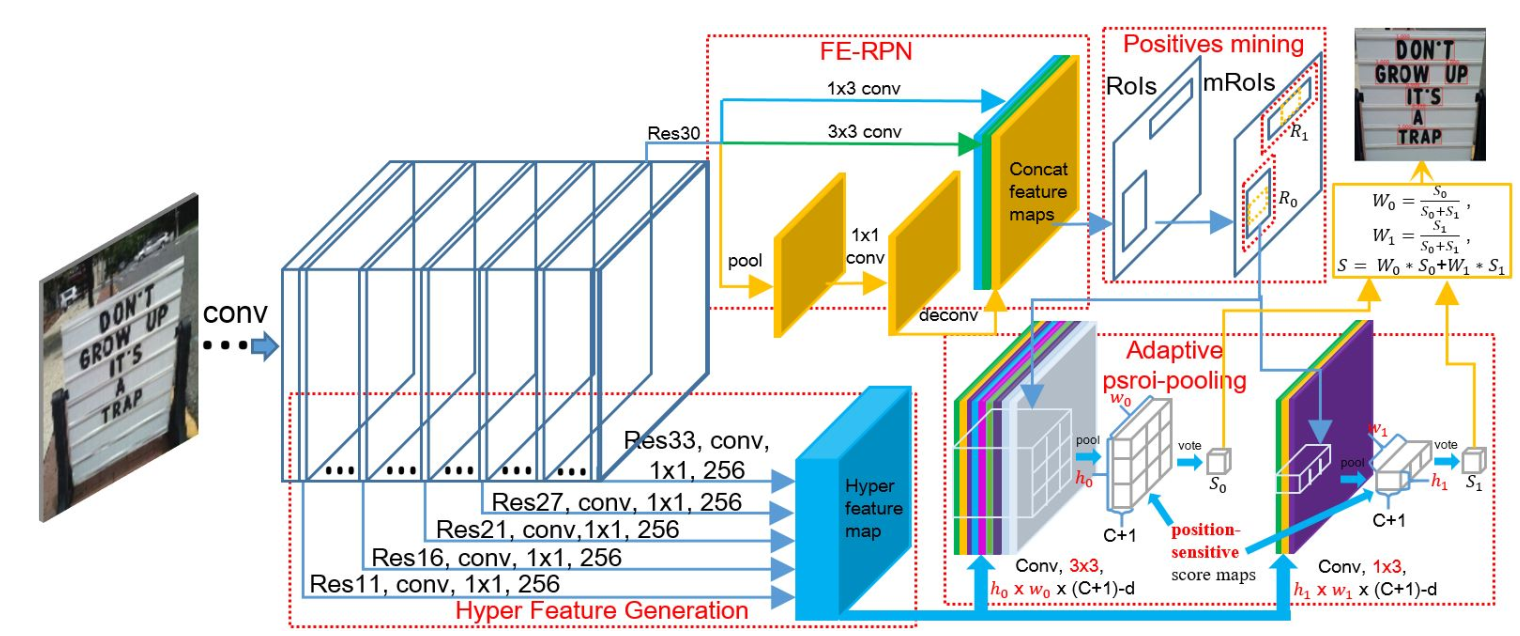
Figure 1: The overall architecture of our FEN. It consists of three innovative components. 1, Feature Enhancement network stem with Feature Enhancement RPN (FE-RPN) and Hyper Feature Generation; 2, Positives mining; 3, Adaptively weighted position-sensitive RoI pooling.
FE-RPN
原來的RPN只有$3*3$的卷積核,現在增加了兩個分支。
一個分支是一個$1*3$的長條形卷積核,主要是為了檢測長條形文字。
另一個分支是一個池化 +一個$1*1$的卷積 +一個上取樣層。這個分支主要是為了擴大感受野增加對文字大小的魯棒性。
Hyper Feature Generation
其實就是一個多層特徵融合的類似於FPN的結構。
Previous object detection approaches always make full use of single scale and high level semantic feature to conduct the refinement of object detection, which may lose much information of object details and thus insufficient for accurate objection localization, especially for smaller text regions.
In a word, high level semantic feature is conducive to object classification while low level feature is beneficial for accurate object localization.
In HyperNet,feature maps originated from different intermediate layers have different spatial size and are merged together by pooling, convolution, deconvolution operations.
Positive Mining
利用對groundTruth做一些scale上的隨機變換,以此來擴增正樣本(利用的原理是:框在小範圍內波動都可以視為正確的檢測)

Adaptively Weighted Position-Sensitive RoI Pooling
原來只有1個$77$的池化,這種方形池化不適合文字這種長條形目標。所以又增加了$37,3*3$等多種池化方式,然後採用加權平均方式來算得到最終池化結果。
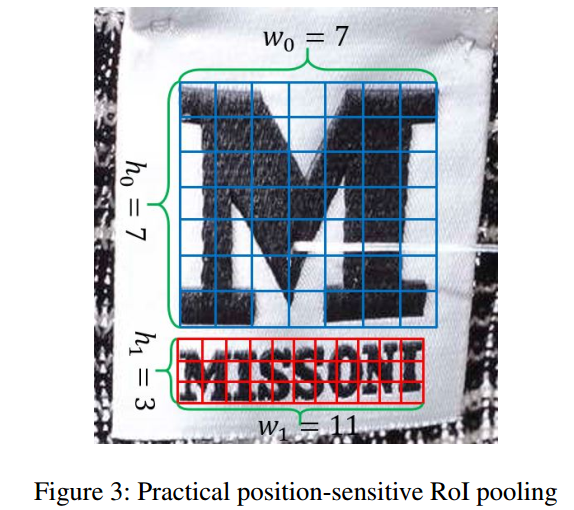

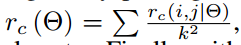
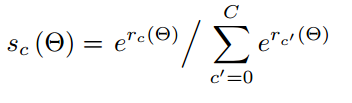
Clearly, different pooling sizes are suitable for different text regions which own different spatial sizes and aspect-ratios, the most suitable pooling size will get the highest score.
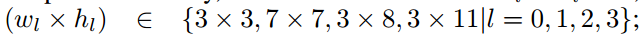

Moreover, with regard to bounding-box regression, we will share the evaluated adaptive weight and do it in the same way.
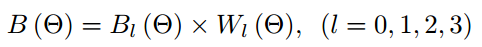
實驗結果
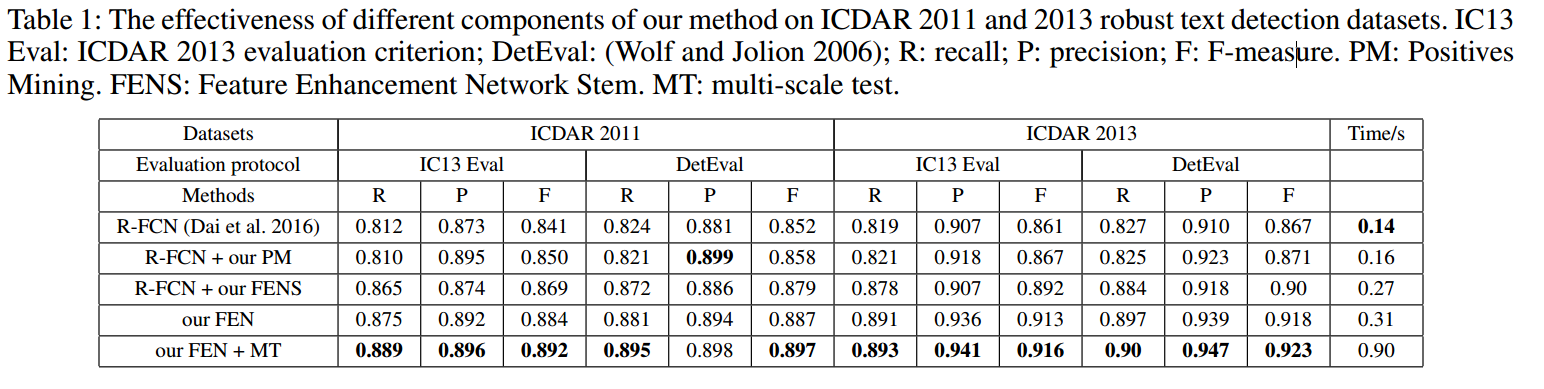
- 每個步驟的有效性
Table 1: The effectiveness of different components of our method on ICDAR 2011 and 2013 robust text detection datasets. IC13 Eval: ICDAR 2013 evaluation criterion; DetEval: (Wolf and Jolion 2006); R: recall; P: precision; F: F-measure. PM: Positives Mining. FENS: Feature Enhancement Network Stem. MT: multi-scale test.
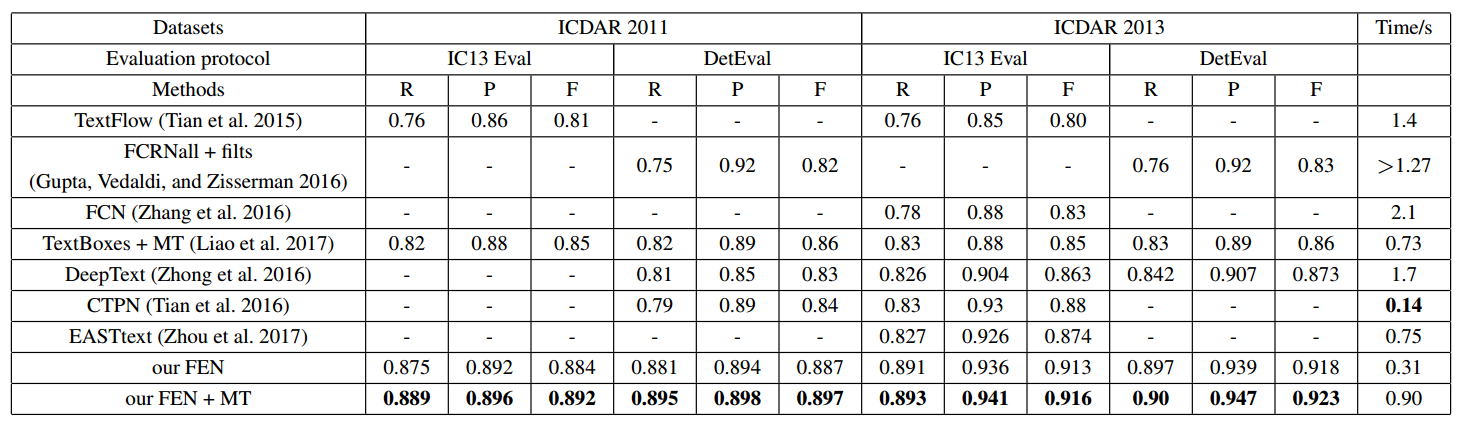
- ICDAR2011和ICDAR2013
Table 2: Comparison with state-of-the-art methods on ICDAR 2011 and 2013 robust text detection datasets. IC13 Eval: ICDAR 2013 evaluation criterion; DetEval: (Wolf and Jolion 2006); R: recall; P: precision; F: F-measure. MT: multi-scale test.
- Positive Mining(PM)的有效性

總結與收穫
這篇文章改進的方法主要是針對文字特徵進行enhance,主要思路簡單說就是增加分支擴大網路寬度。