【論文速讀】Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation[2018-CPVR]
方法概述
該方法用一個端到端網路完成文字檢測整個過程——除了基礎卷積網路(backbone)外,包括兩個並行分支和一個後處理。第一個分支是通過一個DSSD網路進行角點檢測來提取候選文字區域,第二個分支是利用類似於RFCN進行網格劃分的方式來做position-sensitive的segmentation。後處理是利用segmentation的score map的綜合得分,過濾角點檢測得到的候選區域中的噪聲。
文章亮點:
(1)不是用一般的目標檢測的框架,而是用角點檢測(corner point detection)來做。(可以更好解決文字方向任意、文字長寬比很大的文字)
(2)分割用的是“position sensitive segmentation”,仿照RFCN劃分網格的思路,把位置資訊融合進去(對於檢測單詞這種細粒度的更有利)
(3)把檢測+分割兩大類的方法整合起來,進行綜合打分的pipeline(可以使得檢測精度更高)
主要流程
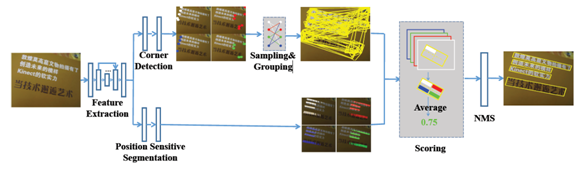
Figure 2. Overview of our method. Given an image, the network outputs corner points and segmentation maps by corner detection and position-sensitive segmentation. Then candidate boxes are generated by sampling and grouping corner points. Finally, those candidate boxes are scored by segmentation maps and suppressed by NMS.
(1)backbone:基礎網路(DSSD),用來特徵提取(不同分支特徵共享)
(2)corner detection:用來生成候選檢測框,是一個獨立的檢測模組,類似於RPN的功能
(3)Position Sensitive Segmentation:整張圖逐畫素的打分,和一般分割不同的是輸出4個score map,分別對應左上、左下、右上、右下不同位置的得分
(4)Scoring + NMS:綜合打分,利用(2)的框和(3)的score map再綜合打分,去掉非文字框,最後再接一個NMS
網路結構
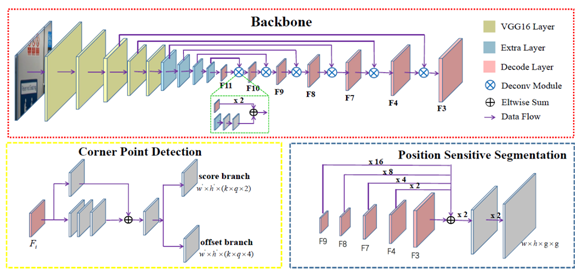
網路包含三個部分:基礎網路(backbone)、角點檢測和敏感位置分割。
Backbone改編於DSSD;Corner Point Detection建立在多個特徵層(粉紅色的塊)上;Position Sensitive Segmentation與Corner Point Detection共享部分特徵(粉紅色塊)。
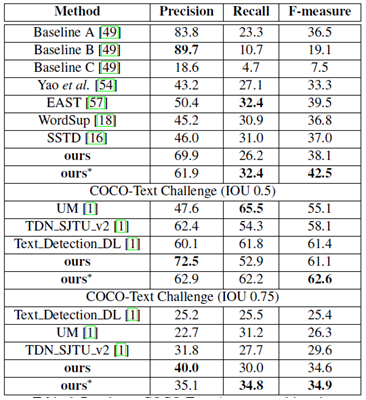
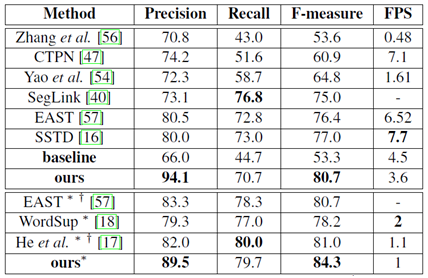
實驗結果
(1)深度學習框架:PyTorch
(2)實驗條件:CPU: Intel(R) Xeon(R) CPU E5-2650 v3 @ 2.30GHz;
GPU: Nvidia Titan Pascal;
RAM: 64GB
所有表格中,*表示多尺度輸入,†表示網路的基礎模型不是VGG16
(3)
多尺度(512*512,768*768,768*1280,1280*1280)
ICDAR2015(傾斜文字)
ICDAR2013(水平文字)
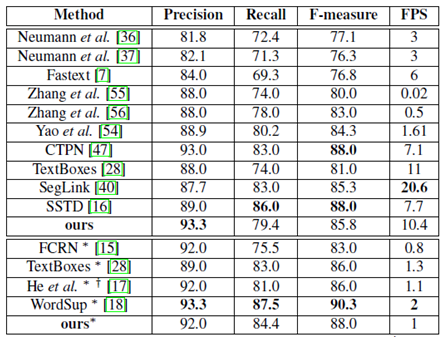
MSRA-TD500(傾斜文字行)

MLT(多語言文字)

COCO-Text