
實戰--Scrapy框架爬去網站資訊
Scrapy的框架圖
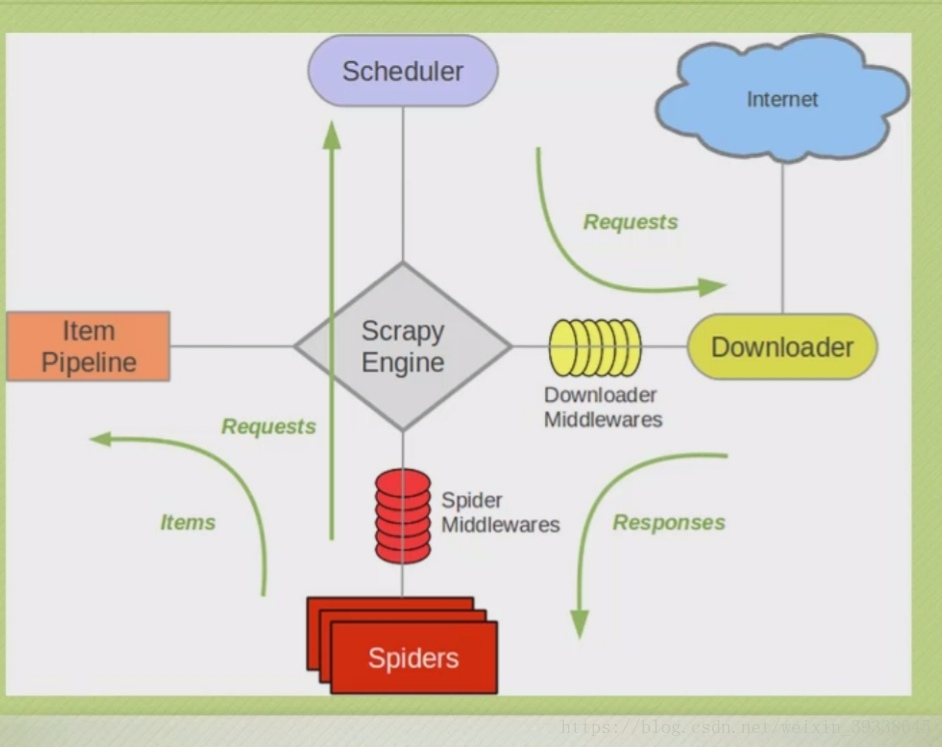
一、使用Strapy抓取網站一共需要四個步驟:
(1)建立一個Scrapy專案;

(2)定義Item容器;
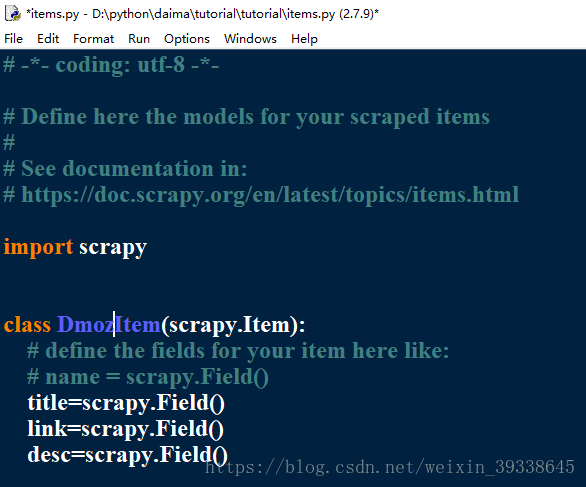
Item是儲存爬取到的資料的容器,其使用方法和python字典類似,並且提供了額外保護機制來i避免拼寫錯誤導致的未定義欄位。
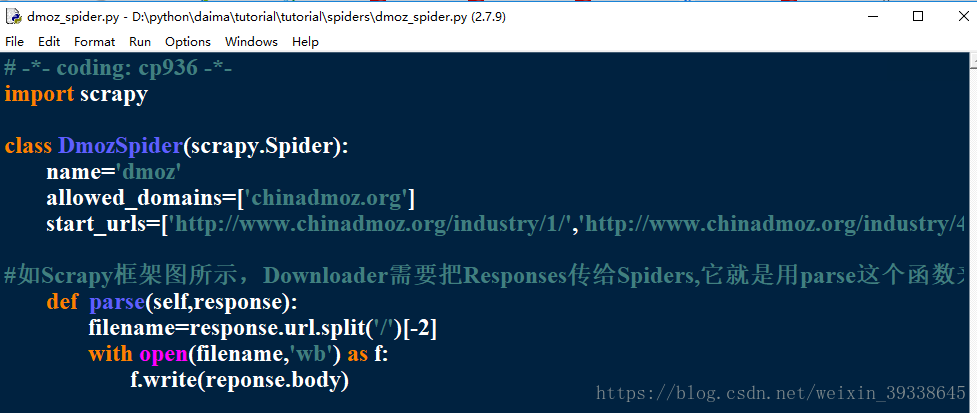
(3)編寫爬蟲;
:在新建的dmoz_spider.py裡面填寫程式碼
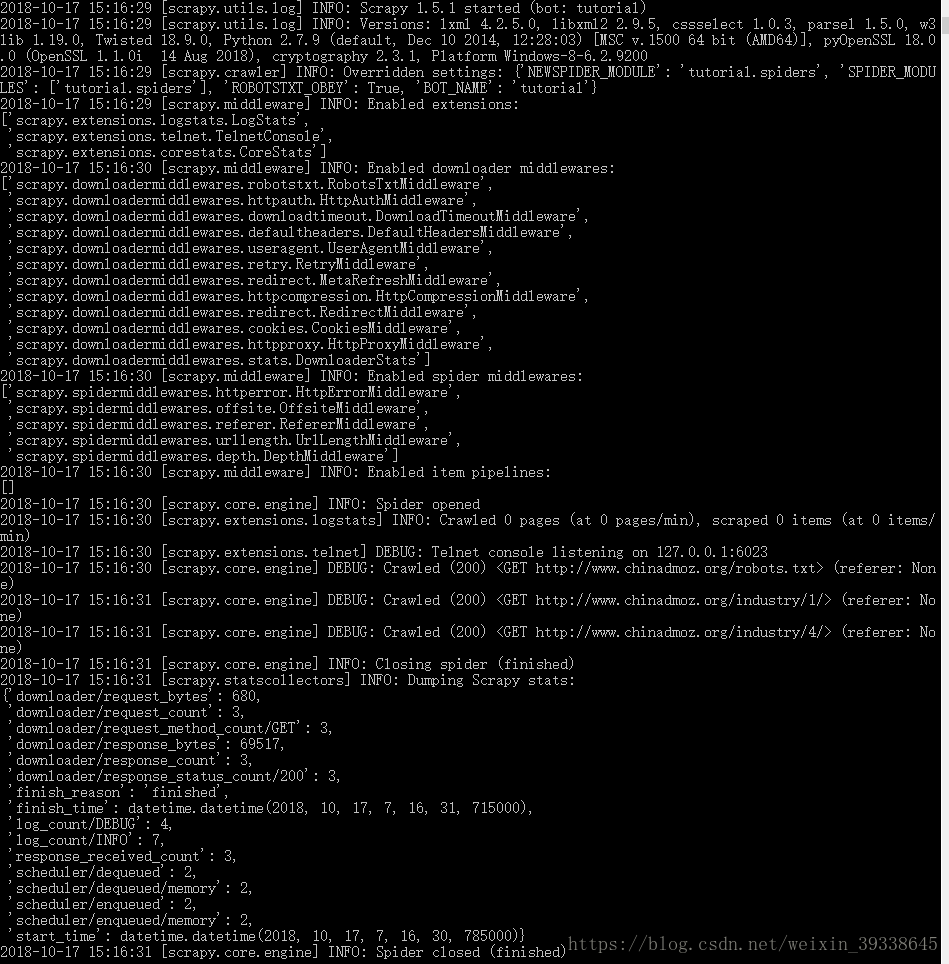
:在cmd控制器裡面爬取,輸入以下程式碼兩句程式碼

:爬取結果
:再次編輯item.py,下圖是理論基礎

在cmd的控制器下進入shell,輸入以下語句,其中的連結就是我所要爬取的其中一個頁面
輸出結果如下即為正確:
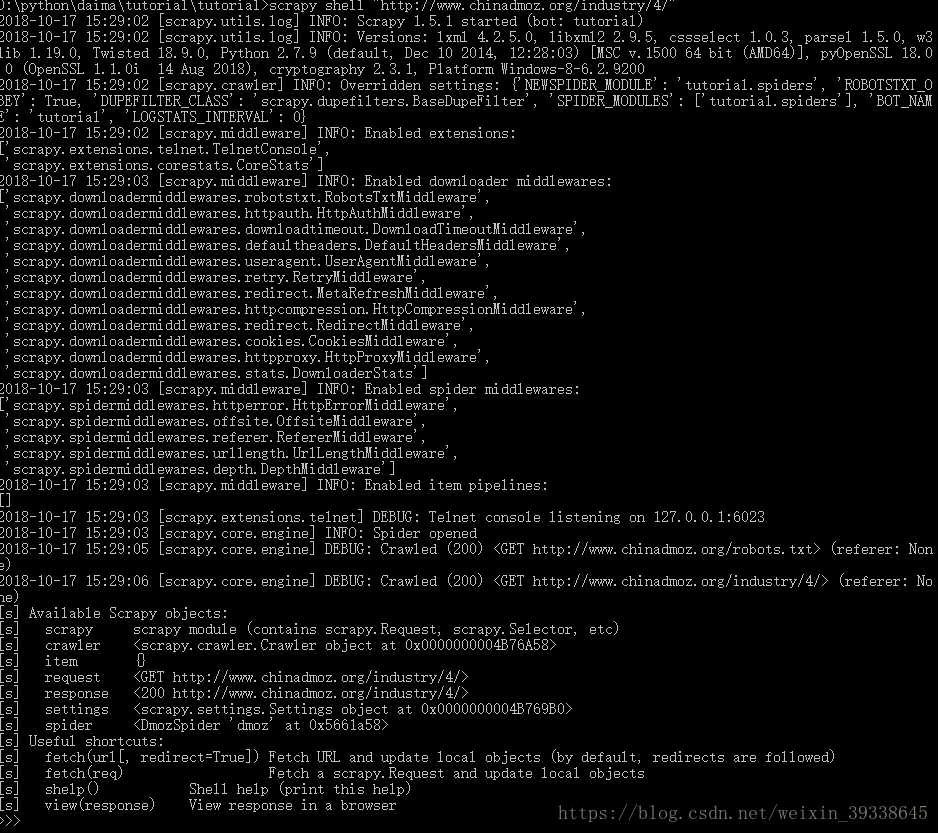
然後再箭頭所指處可以輸入response.body,就可以看到網頁的所有內容,輸入response.headers,就可以看到網頁的頭,但是想在網頁的內容中找到自己想要的,就必須利用Selector選擇器中的方法,例如XPath,XPath是一門再網頁中查詢特定資訊的語言。所以用XPath來篩選資料,要比使用正則表示式容易些。如下圖:

得到一個列表,對列表字串化時利用extract(),如果只想要title裡面的文字,直接在title後面加/text(),結果如下:

通過網站的審查元素我們可以知道,我們所需要的網站描述性內容都在ul中的li標籤下,所以在cmd控制器下輸出程式碼進行查詢,如下圖:

想看到標籤裡面的內容,如下:

如果想得到網站的標題,根據審查元素可以看到它們是在a標籤下,具體執行如下:結果都是二進位制顯示

如果想獲得所有網址的連結,具體執行如下:

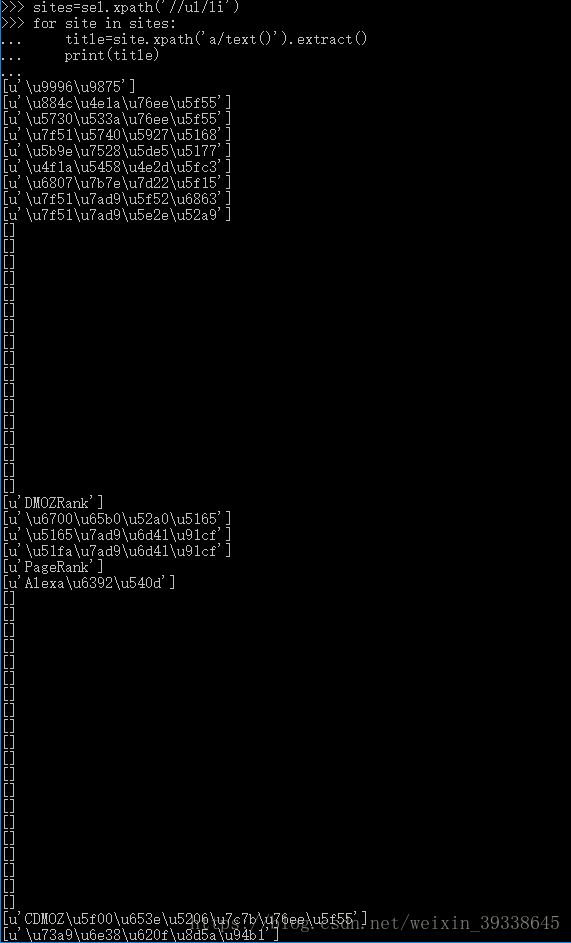
下面是迴圈輸出title
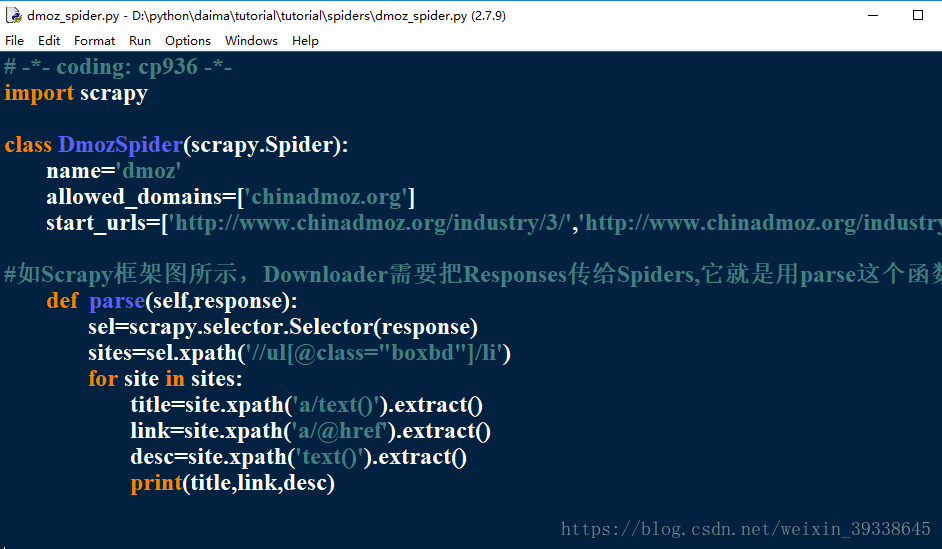
爬取指定位置的資訊,修改dmoz_spider.py
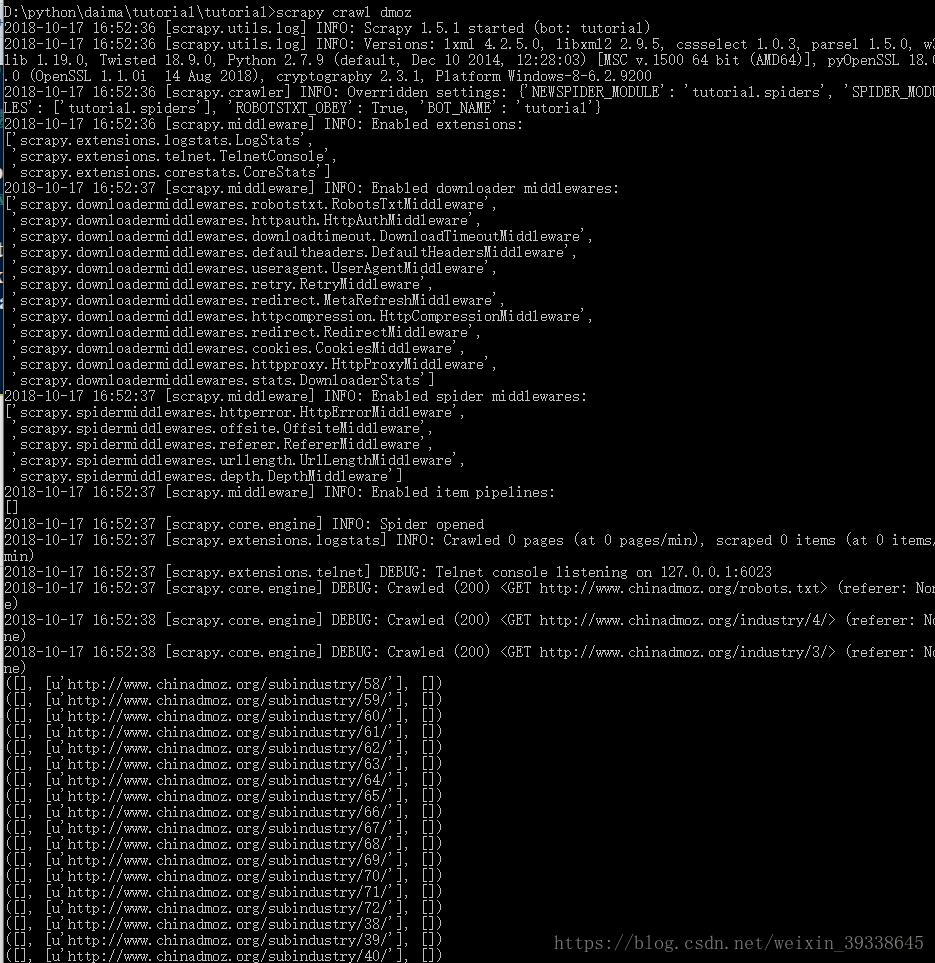
爬取結果如下:
標題-連結-描述,由於是中文的原因,沒有顯示出來
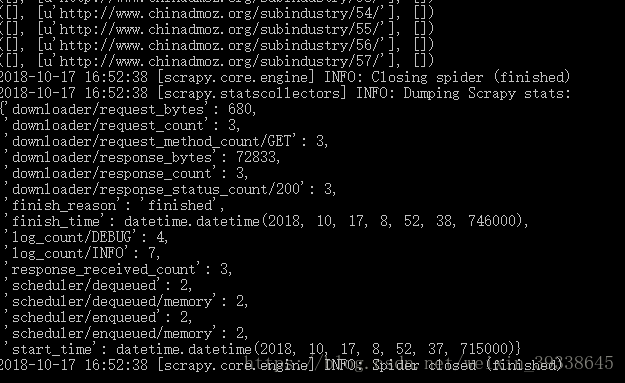
(4)儲存內容。
修改dmoz_spider.py,修改如下:
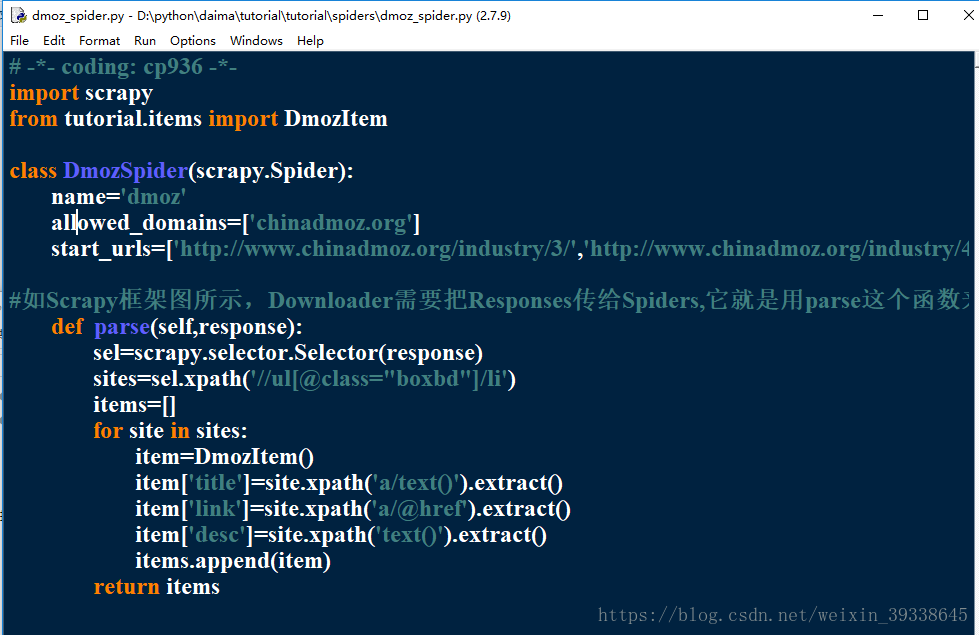
然後再cmd控制器下輸入,如下圖所示的第一行程式碼進行儲存,-o後面是檔名,-t後面是儲存的檔案形式
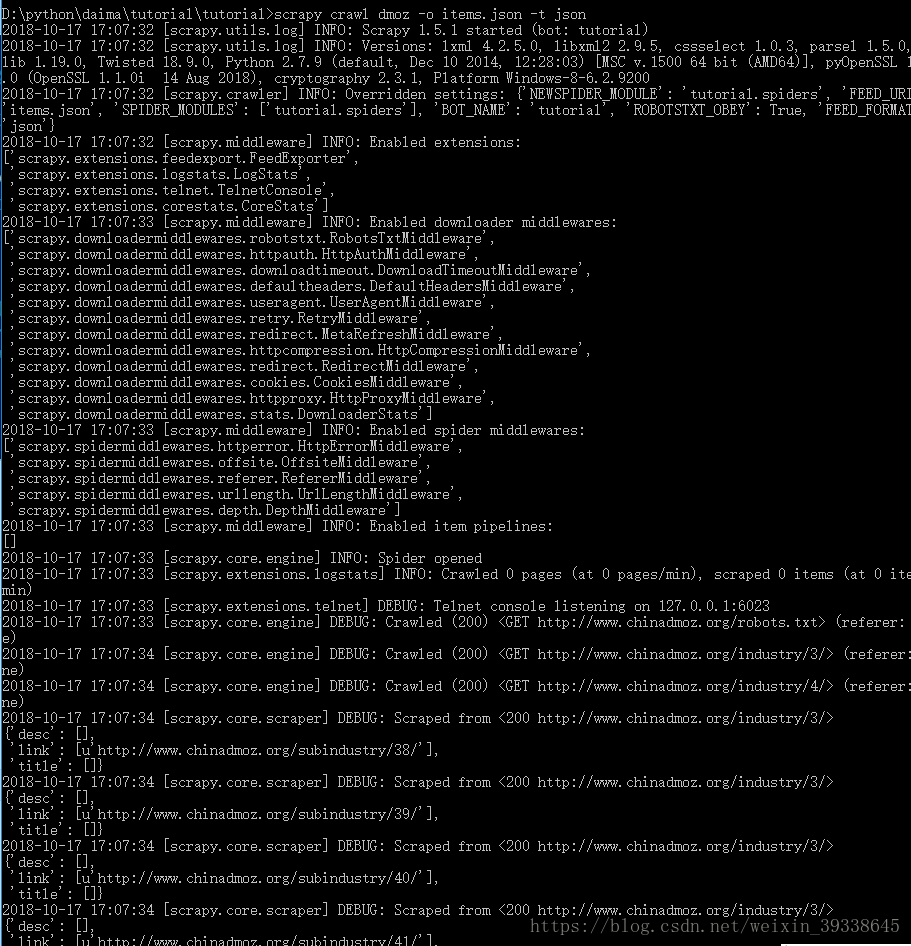
然後再tutorial根目錄下找到items.json,用記事本開啟,裡面就是我爬取的內容,有title標題,link連結,desc描述
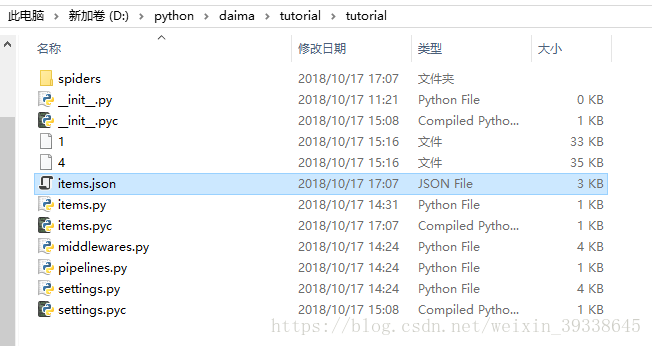
到此,基於Scrapy框架的網頁爬取就結束了。希望對各位有所幫助!