
Sqoop與HDFS、Hive、Hbase等系統的資料同步操作
Sqoop與HDFS結合
下面我們結合 HDFS,介紹 Sqoop 從關係型資料庫的匯入和匯出。
Sqoop import
它的功能是將資料從關係型資料庫匯入 HDFS 中,其流程圖如下所示。
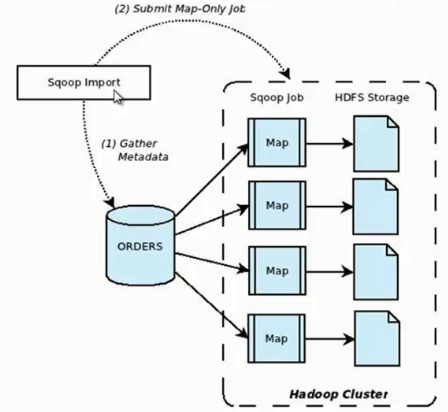
我們來分析一下 Sqoop 資料匯入流程,首先使用者輸入一個 Sqoop import 命令,Sqoop 會從關係型資料庫中獲取元資料資訊,比如要操作資料庫表的 schema是什麼樣子,這個表有哪些欄位,這些欄位都是什麼資料型別等。它獲取這些資訊之後,會將輸入命令轉化為基於 Map 的 MapReduce作業。這樣 MapReduce作業中有很多 Map 任務,每個 Map 任務從資料庫中讀取一片資料,這樣多個 Map 任務實現併發的拷貝,把整個資料快速的拷貝到 HDFS 上。
下面我們看一下 Sqoop 如何使用命令列來匯入資料的,其命令列語法如下所示
sqoop import \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --target-dir /junior/sqoop/ \ //可選,不指定目錄,資料預設匯入到/user下 --where "sex='female'" \ //可選 --as-sequencefile \ //可選,不指定格式,資料格式預設為 Text 文字格式 --num-mappers 10 \ //可選,這個數值不宜太大 --null-string '\\N' \ //可選 --null-non-string '\\N' \ //可選
--connect:指定 JDBC URL。
--username/password:mysql 資料庫的使用者名稱。
--table:要讀取的資料庫表。
--target-dir:將資料匯入到指定的 HDFS 目錄下,檔名稱如果不指定的話,會預設資料庫的表名稱。
--where:過濾從資料庫中要匯入的資料。
--as-sequencefile:指定資料匯入資料格式。
--num-mappers:指定 Map 任務的併發度。
--null-string,--null-non-string:同時使用可以將資料庫中的空欄位轉化為'\N',因為資料庫中欄位為 null,會佔用很大的空間。
下面我們介紹幾種 Sqoop 資料匯入的特殊應用。
1、Sqoop 每次匯入資料的時候,不需要把以往的所有資料重新匯入 HDFS,只需要把新增的資料匯入 HDFS 即可,下面我們來看看如何匯入新增資料。
sqoop import \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --incremental append \ //代表只匯入增量資料 --check-column id \ //以主鍵id作為判斷條件 --last-value 999 //匯入id大於999的新增資料
上述三個組合使用,可以實現資料的增量匯入。
2、Sqoop 資料匯入過程中,直接輸入明碼存在安全隱患,我們可以通過下面兩種方式規避這種風險。
1)-P:sqoop 命令列最後使用 -P,此時提示使用者輸入密碼,而且使用者輸入的密碼是看不見的,起到安全保護作用。密碼輸入正確後,才會執行 sqoop 命令。
sqoop import \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --table user \ -P
2)--password-file:指定一個密碼儲存檔案,讀取密碼。我們可以將這個檔案設定為只有自己可讀的檔案,防止密碼洩露。
sqoop import \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --table user \ --password-file my-sqoop-password
Sqoop export
它的功能是將資料從 HDFS 匯入關係型資料庫表中,其流程圖如下所示。

我們來分析一下 Sqoop 資料匯出流程,首先使用者輸入一個 Sqoop export 命令,它會獲取關係型資料庫的 schema,建立 Hadoop 欄位與資料庫表字段的對映關係。 然後會將輸入命令轉化為基於 Map 的 MapReduce作業,這樣 MapReduce作業中有很多 Map 任務,它們並行的從 HDFS 讀取資料,並將整個資料拷貝到資料庫中。
下面我們看一下 Sqoop 如何使用命令列來匯出資料的,其命令列語法如下所示。
sqoop export \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --export-dir user
--connect:指定 JDBC URL。
--username/password:mysql 資料庫的使用者名稱和密碼。
--table:要匯入的資料庫表。
--export-dir:資料在 HDFS 上的存放目錄。
下面我們介紹幾種 Sqoop 資料匯出的特殊應用。
1、Sqoop export 將資料匯入資料庫,一般情況下是一條一條匯入的,這樣匯入的效率非常低。這時我們可以使用 Sqoop export 的批量匯入提高效率,其具體語法如下。
sqoop export \ --Dsqoop.export.records.per.statement=10 \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --export-dir user \ --batch
--Dsqoop.export.records.per.statement:指定每次匯入10條資料,--batch:指定是批量匯入。
2、在實際應用中還存在這樣一個問題,比如匯入資料的時候,Map Task 執行失敗, 那麼該 Map 任務會轉移到另外一個節點執行重新執行,這時候之前匯入的資料又要重新匯入一份,造成資料重複匯入。 因為 Map Task 沒有回滾策略,一旦執行失敗,已經匯入資料庫中的資料就無法恢復。Sqoop export 提供了一種機制能保證原子性, 使用--staging-table 選項指定臨時匯入的表。Sqoop export 匯出資料的時候會分為兩步:第一步,將資料匯入資料庫中的臨時表,如果匯入期間 Map Task 失敗,會刪除臨時表資料重新匯入;第二步,確認所有 Map Task 任務成功後,會將臨時表名稱為指定的表名稱。
sqoop export \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --staging-table staging_user
3、在 Sqoop 匯出資料過程中,如果我們想更新已有資料,可以採取以下兩種方式。
1)通過 --update-key id 更新已有資料。
sqoop export \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --update-key id
2)使用 --update-key id和--update-mode allowinsert 兩個選項的情況下,如果資料已經存在,則更新資料,如果資料不存在,則插入新資料記錄。
sqoop export \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --update-key id \ --update-mode allowinsert
4、如果 HDFS 中的資料量比較大,很多欄位並不需要,我們可以使用 --columns 來指定插入某幾列資料。
sqoop export \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --column username,sex
5、當匯入的欄位資料不存在或者為null的時候,我們使用--input-null-string和--input-null-non-string 來處理。
sqoop export \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --input-null-string '\\N' \ --input-null-non-string '\\N'
Sqoop與其它系統結合
Sqoop 也可以與Hive、HBase等系統結合,實現資料的匯入和匯出,使用者需要在 sqoop-env.sh 中新增HBASE_HOME、HIVE_HOME等環境變數。
1、Sqoop與Hive結合比較簡單,使用 --hive-import 選項就可以實現。
sqoop import \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --hive-import
2、Sqoop與HBase結合稍微麻煩一些,需要使用 --hbase-table 指定表名稱,使用 --column-family 指定列名稱。
sqoop import \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --hbase-table user \ --column-family city
參考資料:https://www.cnblogs.com/qiaoyihang/p/6229714.html