
關於深度學習的一點思考
原文連結:http://m.elecfans.com/article/664646.html
周志華,南京大學教授,計算機系主任,南京大學人工智慧學院院長,歐洲科學院外籍院士,美國計算機學會 (ACM)、美國科學促進會 (AAAS)、國際人工智慧學會 (AAAI) 、國際電氣電子工程師學會 (IEEE) 、國際模式識別學會 (IAPR)、國際工程技術 (IET/IEE) 等學會的會士,實現了 AI 領域會士大滿貫。

導讀:周志華教授從深度神經網路的深層含義說起,條分縷析地總結出神經網路取得成功的三大原因:
有逐層的處理
有特徵的內部變化
有足夠的模型複雜度
並得出結論:如果滿足這三大條件,則並不一定只能用深度神經網路。
各位嘉賓,各位朋友大家下午好!
很高興今天下午來參加京東的這個活動,各位最近可能都聽說過我們南京大學成立了人工智慧學院,這是中國C9高校(編輯注:C9高校是指北京大學、清華大學、復旦大學、上海交通大學、南京大學、浙江大學、中國科學技術大學、哈爾濱工業大學、西安交通大學共9所高校)的第一所人工智慧學院。我們會和京東在科學研究和人才培養方面開展非常深度的合作。具體的合作內容過一段時間會陸續地告訴大家。今天參加這個活動,謝謝伯文(編輯注:指周伯文博士,京東集團副總裁,京東AI平臺與研究部負責人)的邀請,在跟伯文溝通的時候談到今天講些什麼呢?伯文說,今天的會議會有很多對技術前沿感興趣的專家,所以希望我分享些我們對技術前沿的一些思考。所以,我今天就跟大家分享些我們對深度學習的一點點思考,僅供大家一起來討論。

我們知道今天人工智慧很熱,人工智慧背後掀起的熱潮技術之一就是深度學習,當我們談到深度學習的時候,在各種應用場景中都應用到它,包括影象、視訊、聲音和自然語言處理等等,但是,如果我們問一個問題,什麼是深度學習?可能大多數人差不多都會認為,深度學習就等於深度神經網路。

我給大家看一個例子。有一個非常著名的學會是國際工業與應用數學學會,他們有一個報紙叫 SIAM News。去年 6 月份的頭版上有一篇文章,它裡面的重點說的就是深度學習是什麼?它(深度學習)是機器學習的一個子域(subfield),這裡面要用深度神經網路。


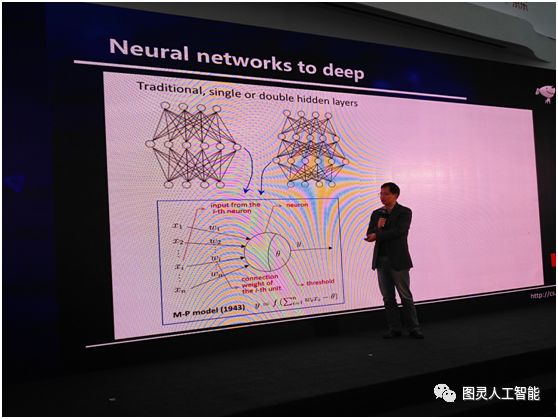
所以,基本上,如果我們要談深度學習的話,我們必須談深度神經網路,或者必須從深度神經網路說起,神經網路並不是一個新生事物,它在人工智慧界已經研究了半個多世紀。以往的話,我們一般會用這樣的神經網路,就是中間有一個隱層或者兩個隱層。在這樣的神經網路當中,它的每個單元是個什麼東西呢?其實,網路中的每個單元是一個非常簡單的計算模型,如下圖左下角所示,這個計算模型在半個世紀以前人們就已經總結出來了。給定一些輸入,它們通過連線和放大,到達一個細胞之後,它的加和不超過一個閾值,就被啟用。說穿了,它就是這麼一個非常簡單的公式,深度神經網路就是很多這樣的公式通過巢狀和迭代得到的一個數學系統。
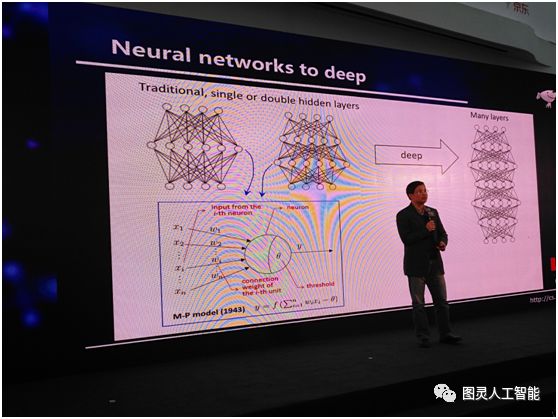
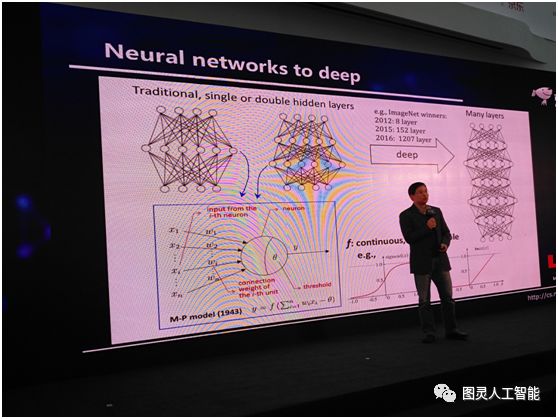
我們今天用到深度神經網路的時候,其實指的是什麼呢?其實是指這個網路的層數很深很深,很多層,大概是多少呢,給大家看一組資料:2012年,ImageNet競賽的冠軍,用到的是8層;2015年,用到的是152層;2016年用到的是1207層;這是一個非常龐大的系統,把這樣的一個系統訓練出來,難度是非常大的。但是呢,我們有一個非常好的訊息,神經網路中的計算單元的啟用函式是連續的、可微的,比如說,我們在深度神經網路中,可能會用Sigmod函式,有了這麼一個性質之後,我們會得到一個非常好的結果。這個結果就是現在我們可以很容易計算系統的梯度。因此就可以很容易用著名的 BP 演算法(注:反向傳播演算法)來訓練這系統。
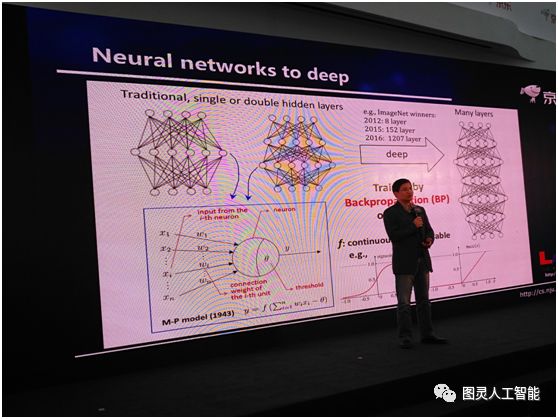
今天通過這樣的演算法,神經網路已經取得了非常多的勝利,但實際上在學術界大家一直沒有想清楚一件事情,就是我們為什麼要用這麼深的模式?可能今天有很多人會說深度學習已經取得了很多的成功,但它一個很大的問題就是理論基礎不清楚,我們理論上還說不清楚它到底怎麼做?為什麼會成功?這裡面的關鍵是什麼?其實我們根本不知道該從什麼角度去看它。因為如果我們要做理論分析的話,首先應該有一點直覺,你到底因為什麼有用,在這條路上往前走才能有關鍵的結果。
關於深度神經網路為什麼能深,其實這件事情到今天為止學術界都沒有統一的看法。在這裡面給大家講一個我們前一段時間給出的論述,這個論述其實是從主要模型的複雜度的角度來討論的。

我們知道一個機器學習模型的複雜度實際上和它的容量有關,而這個容量直接決定了它的學習能力,所以說學習能力和複雜度是有關的。其實我們老早就知道,如果我們能夠增強一個學習模型的複雜度,它的學習能力就能夠提升,那麼怎樣去提高複雜度呢?
對神經網路這樣的模型來說有兩條很明顯的途徑,一條是我們把模型變深,一條是我們把它變寬,但是如果從提升複雜度的角度,變深會更有效。當你變寬的時候你只不過增加了一些計算單元、增加了函式的個數,而在變深的時候不僅增加了個數,其實還增加了嵌入的層次,所以泛函的表達能力會更強。所以從這個角度來說,我們應該嘗試變深。

我們知道一個機器學習模型的複雜度實際上和它的容量有關,而這個容量直接決定了它的學習能力,所以說學習能力和複雜度是有關的。其實我們老早就知道,如果我們能夠增強一個學習模型的複雜度,它的學習能力就能夠提升,那麼怎樣去提高複雜度呢?
對神經網路這樣的模型來說有兩條很明顯的途徑,一條是我們把模型變深,一條是我們把它變寬,但是如果從提升複雜度的角度,變深會更有效。當你變寬的時候你只不過增加了一些計算單元、增加了函式的個數,而在變深的時候不僅增加了個數,其實還增加了嵌入的層次,所以泛函的表達能力會更強。所以從這個角度來說,我們應該嘗試變深。

給定一個數據集,我們希望把資料集裡的東西學出來,但是有時候可能把這個資料本身的一些特性學出來了,而這個特性卻不是一般的規律。當把學出來的錯誤東西當成一般規律來用的時候,就會犯巨大的錯誤,這種現象就是過擬合。為什麼會把資料本身的特性學出來?就是因為我們的模型學習能力太強了。
所以以往我們不太用太複雜的模型,為什麼現在我們可以用這樣的模型?其實有很多因素,第一個因素是現在我們有很大的資料,那麼比如說我手上如果只有 3000 多資料,學出來的特性就不太可能是一般規律。但是如果有三千萬、甚至三千萬萬的資料,那麼這些資料裡的特性本來就是一般規律,所以使用大的資料本身就是緩解過擬合的關鍵條件。
第二個因素,今天有很多很強大的計算裝置,所以才能夠訓練出這樣的模型,同時通過領域裡很多學者的努力,我們有了大量關於訓練這樣複雜模型的技巧和演算法,所以這使得我們使用複雜模型成為可能。
按照這個思路來說,其實有三件事:第一,我們今天有更大的資料;第二;有強力的計算裝置;第三,有很多有效的訓練技巧。
這導致我們可以用高複雜度的模型。而深度神經網路恰恰就是一種很便於實現的高複雜度的模型。所以這麼一套理論解釋,如果我們說它是一個解釋的話,它好像是能告訴我們為什麼我們現在能用深度神經網路。為什麼它能成功?就是因為複雜度大。


在一年多之前,我們把這個解釋說出來的時候,其實國內外很多同行也很贊同這麼一個解釋,因為大家覺得這聽起來蠻有道理的,其實我一直對這個不是特別滿意,這是為什麼?其實有一個潛在的問題我們一直沒有回答。如果從複雜度解釋的話,我們就沒有辦法說為什麼扁平的或者寬的網路做不到深度神經網路的效能?因為事實上我們把網路變寬,雖然它的效率不是那麼高,但是它同樣也能起到增加複雜度的能力。
實際上我們在 1989 年的時候就已經有一個理論證明,說神經網路有萬有逼近能力:只要你用一個隱層,就可以以任意精度逼近任意複雜度的定義在一個緊集上的連續函式。
其實不一定要非常深。這裡面我要引用一個說法,神經網路有萬有逼近能力,可能是有的人會認為這是導致神經網路為什麼這麼強大的一個主要原因,其實這是一個誤解。
我們在機器學習裡面用到的所有模型,它必須具有萬有逼近能力。如果沒有這個能力,根本不可用。所以最簡單的,哪怕傅立葉變換,它就已經有這個能力,所以這個能力不是神經網路所特有的。那我們在這兒要強調的一件事情是什麼?其實我只要有一個隱層,我加無限度的神經元進去,它的能力也會變得很強,複雜度會變得很高。但是這樣的模型無論在應用裡面怎麼試,我們發現都不如深度神經網路好。所以從複雜的角度可能很難解決這個問題,我們需要一點更深入的思考。




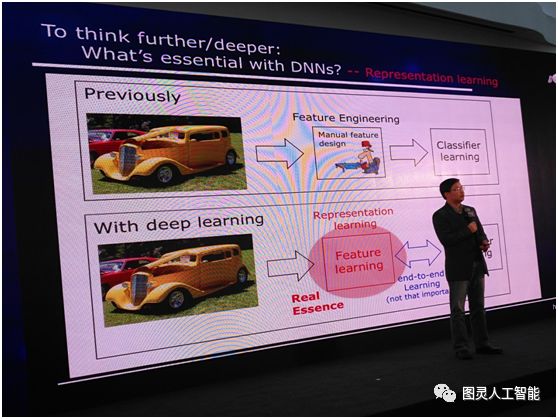
所以我們要問這麼一個問題:深度神經網路裡面最本質的東西到底是什麼?今天我們的答案可能是要做表示學習的能力。以往我們用機器學習,首先拿到一個數據,比如這個資料物件是一個影象,我們就用很多特徵把它描述出來,比如說顏色、紋理等等,這一些特徵都是我們人類專家通過手工來設計的,表達出來之後我們再去進行學習。
而今天我們有了深度學習之後,現在不再需要手工設計特徵,把資料從一端扔進去,模型從另外一端出來,中間所有的特徵完全通過學習自己來解決,這是所謂的特徵學習或者表示學習,這和以往的機器學習技術相比是一個很大的進步,我們不再需要完全依賴人類專家去設計特徵了。
有時候我們的工業界朋友會說,這裡面有一個很重要的叫做端到端學習,大家認為這個非常重要。其實這一件事情要分兩個方面來看:一個方面當我們把特徵學習和分類器學習聯合起來考慮,可以達到聯合優化的作用,這是好的方面;但另一方面,如果這裡面發生什麼我們不清楚,這時候端到端的學習不一定真的好,因為可能第一部分往東,第二部分往西,合起來看往東走的更多一些,其實內部有一些東西已經抵消了。
實際上機器學習裡面早就有端到端學習,比如說做特徵選擇,但這類方法是不是比其它特徵選擇的方法要強?不一定,所以這不是最重要的,真正重要的還是特徵學習或者表示學習。
我們再問下一個問題,表示學習最關鍵的又是什麼?對這件事情我們現在有這麼一個答案,就是逐層的處理。現在我們就引用非常流行的《深度學習》一書裡的一張圖,當我們拿到一個影象的時候,如果我們把神經網路看作很多層的時候,首先在最底層我們看到是一些畫素的東西,當我們一層一層往上的時候,慢慢的有邊緣,再往上有輪廓等等,在真正的神經網路模型裡不一定有這麼清晰的分層,但總體上確實是在往上不斷做物件的抽象。

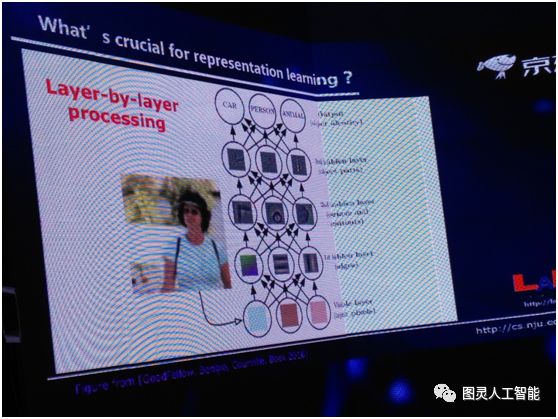
而這個特點,我們現在認為這好像是深度學習真正成功的關鍵因素之一,因為扁平神經網路能做很多深層神經網路所做的事,但是有一點它做不到:當它是扁平的時候,就沒有進行一個深度加工,所以深度的逐層抽象可能很關鍵。那如果我們再看一看,大家可能就會問,其實逐層處理這件事,在機器學習裡也不是一個新東西。
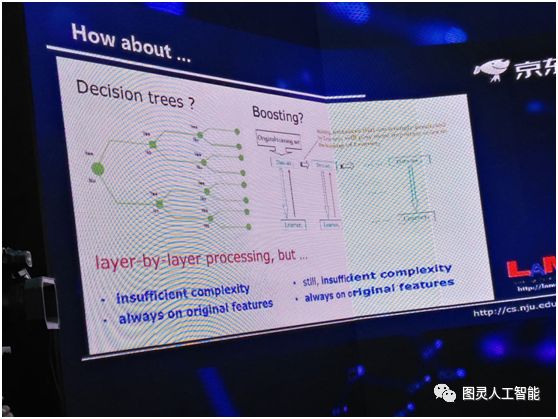
以前有很多逐層處理的東西,比如說決策樹,它就是逐層處理,這是非常典型的模型。這個已經有五六十年的歷史了,但它為什麼做不到深度神經網路這麼好呢?首先它的複雜度不夠,因為決策樹的深度,如果我們只考慮離散特徵,其最深的深度不會超過特徵的個數,所以它的模型複雜度有上限;第二整個決策樹的學習過程中,它內部沒有進行特徵變化,始終是在一個特徵空間裡面進行,這可能也是一個問題。
大家如果對高階一點的機器學習模型有所瞭解,你可能會問,現在很多 Boosting 模型也是一層一層往下走,為什麼它沒有取得深度學習的成功?我想問題其實差不多,首先複雜度還不夠,第二,更關鍵的一點,它始終在原始空間裡面做事情,所有的這些學習器都是在原始特徵空間,中間沒有進行任何的特徵變換。
深度神經網路到底為什麼成功?裡面的關鍵原因是什麼?我想首先我們需要兩件事,第一是逐層地處理,第二我們要有一個內部的特徵變換。而當我們考慮到這兩件事情的時候,我們就會發現,其實深度模型是一個非常自然的選擇。有了這樣的模型,我們很容易可以做上面兩件事。但是當我們選擇用這麼一個深度模型的時候,我們就會有很多問題,它容易 overfit,所以我們要用大資料,它很難訓練,我們要有很多訓練的 trick,這個系統的計算開銷非常大,所以我們要有非常強有力的計算裝置,比如 GPU 等等。

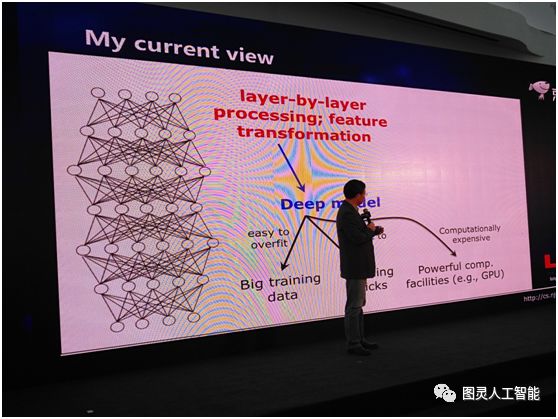
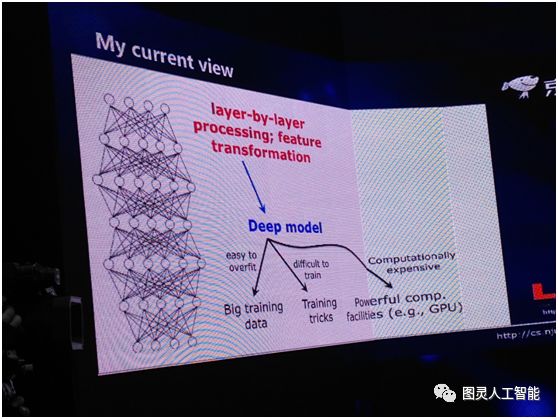
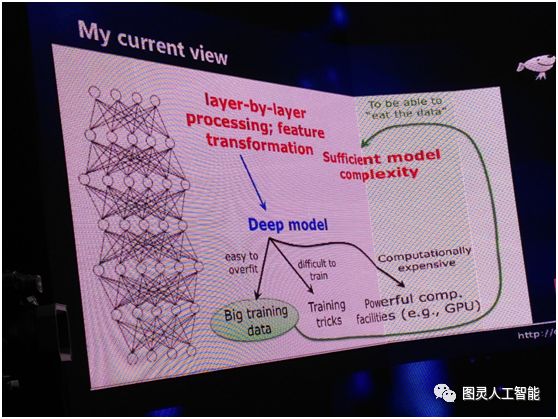
實際上所有這些東西是因為我們選擇了深度模型之後產生的一個結果,他們不是我們用深度學習的原因。所以這和以往我們的思考不太一樣,以往我們認為有了這些東西,導致我們用深度模型,現在我們覺得這個因果關係恰恰是反過來的——因為我們要用它,所以我們才會考慮上面的這些東西。
而另外還有一點我們要注意,當我們要有很大的訓練資料的時候,這就要求我們必須要有很複雜的模型。假設我們有一個線性模型的話,給你 2000 萬要的還是 2 億的樣本,其實對它不是太大區別,它已經學不進去。而我們有了充分的複雜度,其實我們看到恰恰它又給我們使用深度模型加了一分。
由於這幾個原因,我們才覺得可能這是深度學習裡面最關鍵的事情。所以這是我們現在的一個認識:第一我們要有逐層的處理;第二我們要有特徵的內部變化;第三,我們要有足夠的模型複雜度。
這三件事情是我們現在認為深度神經網路為什麼能夠成功的關鍵原因,或者說這是一個猜測。如果滿足這幾個條件,我其實可以馬上想到,不一定真的要用神經網路,神經網路是選擇的幾個方案之一,我只要同時做到這三件事,別的模型也可以,並不一定只能用深度神經網路。

我們就要想一想,我們有沒有必要考慮神經網路之外的模型?其實是有的。因為大家都知道神經網路有很多缺陷。
第一,凡是用過深度神經網路的人都知道,你要花大量的精力來調它的引數,因為這是一個巨大的系統。這裡面會帶來很多問題,首先當我們調引數的時候,這個經驗其實是很難共享的。有的朋友可能說,我在第一個影象資料集之上調資料的經驗,當我用第二個影象資料集的時候,這個經驗肯定可以重用的。但是我們有沒有想過,比如說我們在影象方面做了一個很大的神經網路,這時候如果要去做語音,其實在影象上面調引數的經驗,在語音問題上可能基本上不太有借鑑作用,所以當我們跨任務的時候,經驗可能就很難有成效。
而且還帶來第二個問題,我們今天都非常關注結果的可重複性,不管是科學研究、技術發展,都希望這結果可重複,而在整個機器學習領域裡面,深度學習的可重複性是最弱的。我們經常會碰到這樣的情況,有一組研究人員發文章報告了一個結果,而這結果其他的研究人員很難重複。因為哪怕你用同樣的資料、同樣的方法,只要超引數的設計不一樣,你的結果就不一樣。
我們在用深度神經網路的時候,模型的複雜度必須事先指定,因為在訓練模型之前,神經網路是什麼樣就必須定了,然後才能用 BP 演算法等等去訓練它。其實這就會帶來很大的問題,因為在沒有解決這個任務之前,我們怎麼知道這個複雜度應該有多大呢?所以實際上大家做的通常都是設更大的複雜度。
如果在座各位關注過去三四年裡深度神經網路、深度學習領域的進展,你可以看到很多最前沿的工作在做什麼事呢?其實都是在有效地縮減網路的複雜度。比如說 ResNet 網路,還有最近大家經常用的模型壓縮等,其實我們想一想不都是把複雜度變小,實際上是先用了一個過大的複雜度,然後再降下來。
那麼我們有沒有可能在一開始就讓這個模型的複雜度隨著資料而變化?這一點對神經網路可能很困難,但是對別的模型是有可能的。還有很多別的問題,比如說理論分析很困難,需要非常大的資料,黑箱模型等等。






那麼這些能不能用來構建深度模型?能不能通過構建深度模型之後得到更好的效能呢?能不能通過把它們變深之後,使得今天深度模型還打不過隨機森林這一些模型的任務,能夠得到更好的結果呢?
那我們自己就受到這樣的一個啟發,我們要考慮這三件事,就是剛才跟大家分析得到的三個結論:第一要做逐層處理,第二是特徵的內部變換,第三我們希望得到一個充分的模型複雜度。



我自己領導的研究組最近在這一方面做了一些工作,我們最近提出了一個 深度森林的方法。
在這個方法裡面我今天不跟大家講技術細節,它是一個基於樹模型的方法,主要是借用整合學習的很多想法。其次在很多不同的任務上,它的模型得到的結果和深度神經網路是高度相似的,除了一些大規模的影象等等。在其他的任務上,特別是跨任務表現非常好,我們可以用同樣一套引數,用在不同的任務中得到不錯的效能,就不需要逐任務的慢慢調引數。
還有一個很重要的特性,它有自適應的模型複雜度,可以根據資料的大小自動來判定該模型長到什麼程度。它的中間有很多好的性質,有很多朋友可能也會下載我們的開原始碼拿去試,到時候我們會有更大規模分散式的版本等等,要做大的任務必須要有更大規模的實現,就不再是單機版能做的事。
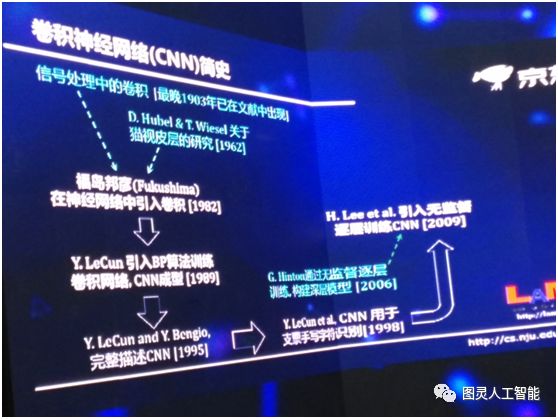
但另一方面,我們要看到這實際上是在發展學科思路上一個全新的思路探索,所以今天雖然它已經能夠解決一部分問題了,但是我們應該可以看到它再往下發展,前景可能是今天我們還不太能夠完全預見到的,所以我這邊簡單回顧一下卷積神經網路,這麼一個非常流行的技術,它其實也是經過了很長期的發展。


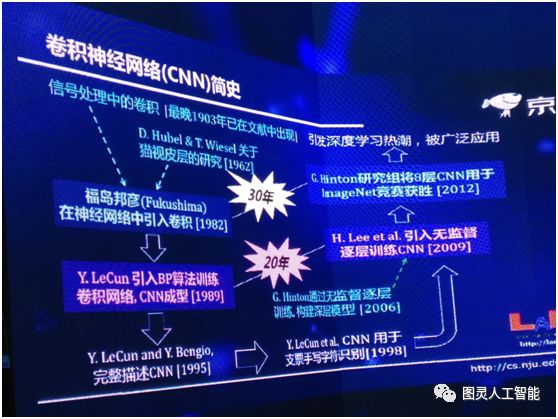
最早訊號處理裡面關於卷積的出現,其實是有一個多世紀了,但是現在深度神經網路的歷史是從 1962 年兩位諾貝爾獎得主關於生物視覺皮層的研究開始。但是不管怎麼樣第一次在神經網路裡引入卷積是 1982 年,在此之後他們做了很多的工作,1989 年引入 BP 演算法,那時演算法就已經成型了,到了 1995 年第一次對 CNN 有了一個完整的描述,在 1998 年對美國支票的識別取得了很大的成功,在 2006 年提出了通過無監督逐層訓練深層模型,到了 2009 年這個技術被引到 CNN 裡,我們可以做深度的 CNN,2012年深度的 CNN 被用在 ImageNet 比賽中,直接掀起了一波深度學習的浪潮。

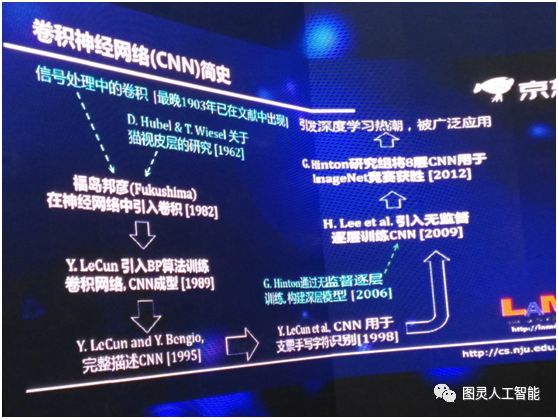


我所做的工作的最重要的意義是什麼呢?以前我們說深度學習是一個黑屋子,這個黑屋子裡面有什麼東西呢?大家都知道它有深度神經網路,現在我們把這個屋子打開了一扇門,把深度森林放進來,我想以後可能還有更多的東西。所以這是這個工作從學術科學發展上的意義上,有一個更重要的價值。


最後我想用兩分鐘的時間談一談,南京大學人工智慧學院馬上跟京東開展全面的、深入的在科學研究和人才培養方面的合作。
關於人工智慧產業的發展,我們要問一個問題,我們到底需要什麼?大家說需要裝置嗎?其實做人工智慧的研究不需要特殊機密的裝置,你只要花錢,這些裝置都買得到,GPU 這些都不是什麼高階的禁運的商品。第二是不是缺資料?也不是,現在我們的資料收集儲存、傳輸、處理的能力大幅度的提升,到處都是資料,真正缺的是什麼?

其實人工智慧時代最缺的就是人才。因為對這個行業來說,你有多好的人,才有多好的人工智慧。所以我們現在可以看到,其實全球都在爭搶人工智慧人才,不光是中國,美國也是這樣。所以我們成立人工智慧學院,其實就有這樣的考慮。




可能我們投資風口裡面有一些詞,今年還很熱,明年就已經不見了,這些詞如果我們追究一下,它裡面科學含義到底是什麼?可能沒幾個人說的清楚,而人工智慧和這些東西完全不一樣,是經過 60 多年發展出來的一個學科。
高水平的人工智慧人才奇缺,這是一個世界性的問題,我們很多企業都是重金挖人,但實際上挖人不能帶來增量,所以我們要從源頭做起,為國家、社會、產業的發展培養高水平的人工智慧人才。
