
Hadoop2.5.2集群部署(完全分布式)
環境介紹
硬件環境
CPU 4 MEM 4G 磁盤 60G軟件環境
OS:centos6.5版本 64位Hadoop:hadoop2.5.2 64位
JDK: JDK 1.8.0_91
主機配置規劃
Hadoop01 172.16.1.156 (NameNode) Hadoop02 172.16.1.157 (DataNode) Hadoop03 172.16.1.158 (DataNode)設置主機名
這裏主機名修改不是必須條件,但是為了操作簡單,建議將主機名設置一下,需要修改調整各臺機器的hosts文件配置,命令如下:如果沒有足夠的權限,可以切換用戶為root
三臺機器統一增加以下host配置:

配置免密碼登錄SSH
1)生成密鑰: ssh-keygen -t rsa2)將id_dsa.pub(公鑰)追加到授權key中:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys3)將認證文件復制到另外兩臺DataNode節點上:
scp ~/.ssh/authorized_keys 172.16.1.157:~/.ssh/
scp ~/.ssh/authorized_keys 172.16.1.158:~/.ssh/3)測試:
ssh hadoop02或ssh hadoop03各節點安裝JDK
(1)檢查jdk版本、卸載openjdk版本查看目前安裝openjdk信息:rpm -qa|grep java

卸載以上三個文件(需要root權限,登錄root權限卸載)
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64
rpm -e --nodeps tzdata-java-2013g-1.el6.noarch
 (2)選擇版本是jdk-8u91-linux-x64.gz
(2)選擇版本是jdk-8u91-linux-x64.gz (4)重命名jdk為jdk1.8(用mv命令)
(4)重命名jdk為jdk1.8(用mv命令)
 (5) 配置環境變量:vi /etc/profile加入以下三行
#JAVA_HOME
export JAVA_HOME=/home/hadoop/jdk1.8
export PATH=$JAVA_HOME/bin:$PATH
(6)執行source /etc/profile使環境變量的配置生效
(7)執行Java –version查看jdk版本,驗證是否成功
(8)將hadoop01機器上安裝好JDK復制到另外兩臺節點上
(5) 配置環境變量:vi /etc/profile加入以下三行
#JAVA_HOME
export JAVA_HOME=/home/hadoop/jdk1.8
export PATH=$JAVA_HOME/bin:$PATH
(6)執行source /etc/profile使環境變量的配置生效
(7)執行Java –version查看jdk版本,驗證是否成功
(8)將hadoop01機器上安裝好JDK復制到另外兩臺節點上


Hadoop安裝
每臺節點都要安裝
Hadoop。上傳
hadoop-2.5.2.tar.gz到用戶
/home/hadoop/software目錄下。
解壓
tar -zvxf hadoop-2.5.2.tar.gz -C /home/hadoop/添加環境變量
vi /etc/profile,尾部添加如下 export JAVA_HOME=/home/hadoop/jdk1.8 export HADOOP_HOME=/home/hadoop/hadoop-2.5.2 export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export CLASSPATH=.:$JAVA_HOME/lib:$HADOOP_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH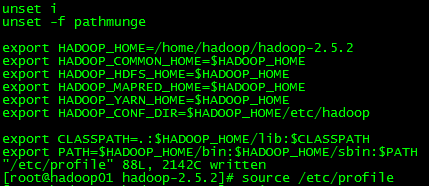
設置環境變量立即生效
source /etc/profile配置Hadoop文件
(1) core-site.xml <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop01:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoop/hadoop-2.5.2/hadoop_tmp</value> </property> <property> <name>io.file.buffer.size</name><value>131072</value>
</property> </configuration> (2)hdfs-site.xml <configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value> hadoop01 :9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file: /home/hadoop/hadoop-2.5.2 /dfs/name</value> <description>namenode上存儲hdfs元數據</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/ home/hadoop/hadoop-2.5.2 /dfs/data</value> <description>datanode上數據塊物理存儲位置</description> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration> 註:訪問namenode的 webhdfs 使用50070端口,訪問datanode的webhdfs使用50075端口。要想不區分端口,直接使用namenode的IP和端口進行所有webhdfs操作,就需要在所有datanode上都設置hdfs-site.xml中dfs.webhdfs.enabled為true。 (3)mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop01:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop01:19888</value> </property> </configuration> jobhistory是Hadoop自帶一個歷史服務器,記錄Mapreduce歷史作業。默認情況下,jobhistory沒有啟動,可用以下命令啟動: sbin/mr-jobhistory-daemon.sh start historyserver (4)yarn-site.xml <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.address</name> <value> hadoop01 :8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>hadoop01:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>hadoop01:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>hadoop01:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>hadoop01:8088</value> </property> </configuration>
(5)修改slaves文件,添加datanode節點hostname到slaves文件中
hadoop01 hadoop02 (6)如果已經配置了JAVA_HOME環境變量,hadoop-env.sh與yarn-env.sh這兩個文件不用修改,因為裏面配置就是:
export JAVA_HOME=${JAVA_HOME}
如果沒有配置JAVA_HOME環境變量,需要分別在hadoop-env.sh和yarn-env.sh中
手動添加
JAVA_HOME
export JAVA_HOME= /home/hadoop/jdk1.8

運行Hadoop
格式化
hdfs namenode –format
啟動Hadoop
start-dfs.sh start-yarn.sh 可以用一條命令: start-all.sh停止Hadoop
stop-all.shJPS查看進程
master主節點進程: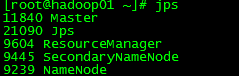 slave數據節點進程:
slave數據節點進程:

通過瀏覽器查看集群運行狀態
http://172.16.1.156:50070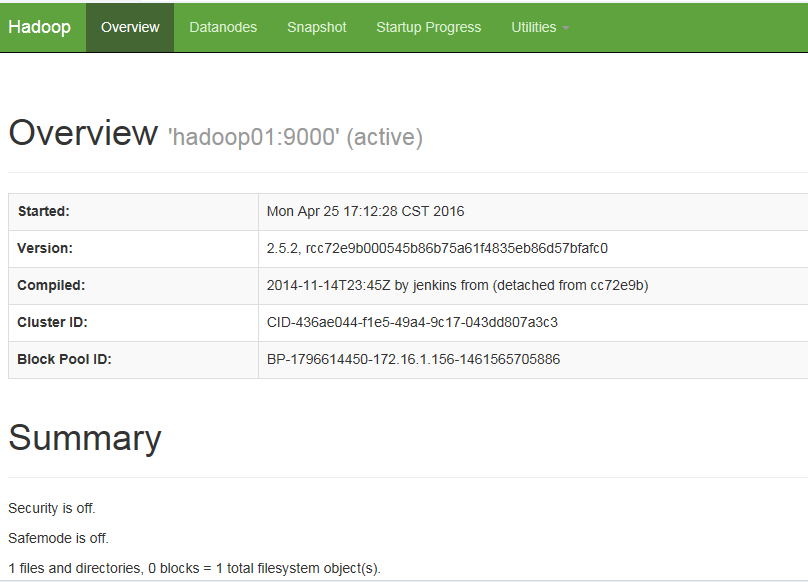
http://172.16.1.156:8088/
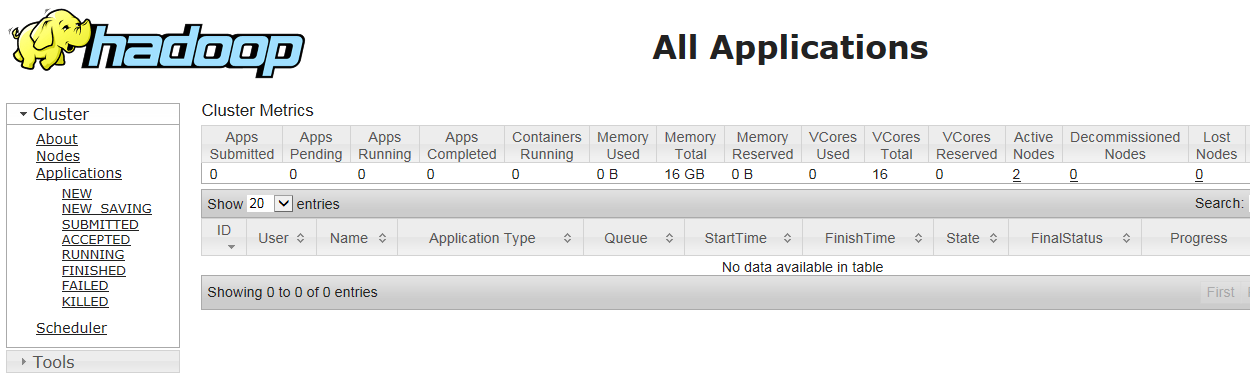
http://172.16.1.156:19888
jobhistory是Hadoop自帶一個歷史服務器,記錄Mapreduce歷史作業。默認情況下,jobhistory沒有啟動,可用以下命令啟動: sbin/mr-jobhistory-daemon.sh start historyserver

測試Hadoop
1)建立輸入文件:vi wordcount.txt
輸入內容為:
hello you
hello me
hello everyone
2)建立目錄
hadoop fs -mkdir /data/wordcount
hadoop fs –mkdir /output/
目錄/data/wordcount用來存放Hadoop自帶WordCount例子的數據文件,運行這個MapReduce任務結果輸出到/output/wordcount目錄中。3)上傳文件
hadoop fs -put wordcount.txt/data/wordcount/
4)執行wordcount程序
hadoop jar usr/local/program/Hadoop-2.5.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.1.jar wordcount /data/wordcount /output/wordcount/
5)查看結果
hadoop fs -text /output/wordcount/part-r-00000
[root@m1mydata]# hadoop fs -text /output/wordcount/part-r-00000 everyone 1 hello 3 me 1 you 1搭建中遇到問題總結
問題一: 在配置環境變量過程可能遇到輸入命令ls命令不能識別問題: ls -bash: ls: command not found 原因:在設置環境變量時,編輯profile文件沒有寫正確,將export PATH=$JAVA_HOME/bin:$PATH中冒號誤寫成分號 ,導致在命令行下ls等命令不能夠識別。 解決方案:export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin 問題二: 在主機上啟動hadoop集群,然後使用jps查看主從機上進程狀態,能夠看到主機上的resourcemanager和各個從機上的nodemanager,但是過一段時間後,從機上的nodemanager就沒有了,主機上的resourcemanager還在。
原因是防火墻處於開啟狀態: 註:nodemanager啟動後要通過心跳機制定期與RM通信,否則RM會認為NM死掉,會停止NM服務。 service 方式
開啟: service iptables start
關閉: service iptables stop
Hadoop2.5.2集群部署(完全分布式)