
ElasticSearch架構以及底層實現
阿新 • • 發佈:2018-11-14
Elasticsearch 是一個兼有搜尋引擎和NoSQL資料庫功能的開源系統,基於Java/Lucene構建,可以用於全文搜尋,結構化搜尋以及近實時分析。可以說Lucene是當今最先進,最高效的全功能開源搜尋引擎框架。 說明: Lucene:只是一個框架,要充分利用它的功能,需要使用JAVA,並且在程式中整合Lucene,學習成本高,Lucene確實非常複雜。 Elasticsearch 是 面向文件型資料庫,這意味著它儲存的是整個物件或者 文件,它不但會儲存它們,還會為他們建立索引,這樣你就可以搜尋他們了
目錄:
- 應用場景
- solr VS ES
- 核心概念
- ES模組結構
- 分片示例
應用場景
- 站內搜尋:主要和 Solr 競爭,屬於後起之秀
- NoSQL json文件資料庫:主要搶佔 Mongo 的市場,它在讀寫效能上優於 Mongo ,同時也支援地理位置查詢,還方便地理位置和文字混合查詢,屬於歪打正著 (對比測試參見:http://blog.quarkslab.com/mongodb-vs-elasticsearch-the-quest-of-the-holy-performances.html)
- 監控:統計以及日誌類時間序的資料的儲存和分析以及視覺化,這方面是引領者
- 國外:Wikipedia使用 ES 提供全文搜尋並高亮關鍵字、StackOverflow結合全文搜尋與地理位置查詢、Github使用Elasticsearch檢索1300億行的程式碼
- 國內:百度(在casio、雲分析、網盟、預測、文庫、直達號、錢包、風控等業務上都應用了ES,單叢集每天匯入30TB+資料,總共每天60TB+)、新浪(見大資料架構--log),阿里巴巴、騰訊等公司均有對ES的使用
- 使用比較廣泛的平臺ELK(ElasticSearch, Logstash, Kibana)
solr VS ES
- Solr是Apache Lucene專案的開源企業搜尋平臺。其主要功能包括全文檢索、命中標示、分面搜尋、動態聚類、資料庫整合,以及富文字(如Word、PDF)的處理。
- Solr是高度可擴充套件的,並提供了分散式搜尋和索引複製。Solr是最流行的企業級搜尋引擎,Solr4 還增加了NoSQL支援。
- Solr是用Java編寫、執行在Servlet容器(如 Apache Tomcat 或Jetty)的一個獨立的全文搜尋伺服器。 Solr採用了 Lucene Java 搜尋庫為核心的全文索引和搜尋,並具有類似REST的HTTP/XML和JSON的API。
- Solr強大的外部配置功能使得無需進行Java編碼,便可對 其進行調整以適應多種型別的應用程式。Solr有一個外掛架構,以支援更多的高階定製
- Elasticsearch 與 Solr 的比較總結
-
- 二者安裝都很簡單
- Solr 利用 Zookeeper 進行分散式管理,而 Elasticsearch 自身帶有分散式協調管理功能
- Solr 支援更多格式的資料,而 Elasticsearch 僅支援json檔案格式
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重於核心功能,高階功能多有第三方外掛提供
- Solr 在傳統的搜尋應用中表現好於 Elasticsearch,但在處理實時搜尋應用時效率明顯低於 Elasticsearch
- Solr 是傳統搜尋應用的有力解決方案,但 Elasticsearch 更適用於新興的實時搜尋應用
核心概念
- 叢集(Cluster): 包含一個或多個具有相同 cluster.name 的節點.
-
- 叢集內節點協同工作,共享資料,並共同分擔工作負荷。
- 由於節點是從屬叢集的,叢集會自我重組來均勻地分發資料.
- cluster Name是很重要的,因為每個節點只能是群集的一部分,當該節點被設定為相同的名稱時,就會自動加入群集。
- 叢集中通過選舉產生一個mater節點,它將負責管理叢集範疇的變更,例如建立或刪除索引,新增節點到叢集或從叢集刪除節點。master 節點無需參與文件層面的變更和搜尋,這意味著僅有一個 master 節點並不會因流量增長而成為瓶頸。任意一個節點都可以成為 master 節點。我們例舉的叢集只有一個節點,因此它會扮演 master 節點的角色。
- 作為使用者,我們可以訪問包括 master 節點在內的叢集中的任一節點。每個節點都知道各個文件的位置,並能夠將我們的請求直接轉發到擁有我們想要的資料的節點。無論我們訪問的是哪個節點,它都會控制從擁有資料的節點收集響應的過程,並返回給客戶端最終的結果。這一切都是由 Elasticsearch 透明管理的
- 節點(node): 一個節點是一個邏輯上獨立的服務,可以儲存資料,並參與叢集的索引和搜尋功能, 一個節點也有唯一的名字,群集通過節點名稱進行管理和通訊.
- 索引(Index): 索引與關係型資料庫例項(Database)相當。索引只是一個 邏輯名稱空間,它指向一個或多個分片(shards),內部用Apache Lucene實現索引中資料的讀寫
- 文件型別(Type):相當於資料庫中的table概念。每個文件在ElasticSearch中都必須設定它的型別。文件型別使得同一個索引中在儲存結構不同文件時,只需要依據文件型別就可以找到對應的引數對映(Mapping)資訊,方便文件的存取
- 文件(Document) :相當於資料庫中的row, 是可以被索引的基本單位。例如,你可以有一個的客戶文件,有一個產品文件,還有一個訂單的文件。文件是以JSON格式儲存的。在一個索引中,您可以儲存多個的文件。請注意,雖然在一個索引中有多分文件,但這些文件的結構是一致的,並在第一次儲存的時候指定, 文件屬於一種 型別(type),各種各樣的型別存在於一個 索引 中。你也可以通過類比傳統的關係資料庫得到一些大致的相似之處:
關係資料庫 ⇒ 資料庫 ⇒ 表 ⇒ 行 ⇒ 列(Columns) Elasticsearch ⇒ 索引 ⇒ 型別 ⇒ 文件 ⇒ 欄位(Fields) - 模擬示意圖如:
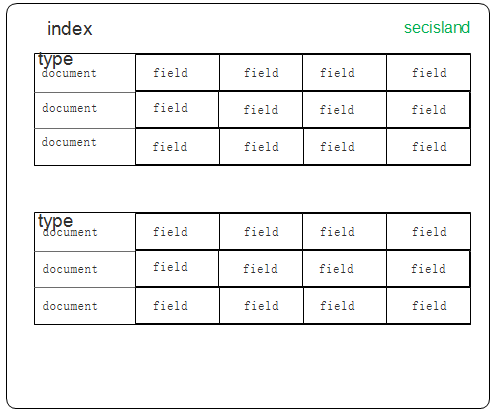
- Mapping: 相當於資料庫中的schema,用來約束欄位的型別,不過 Elasticsearch 的 mapping 可以自動根據資料建立
- 分片(shard) :是 工作單元(worker unit) 底層的一員,用來分配叢集中的資料,它只負責儲存索引中所有資料的一小片。
-
- 分片是一個獨立的Lucene例項,並且它自身也是一個完整的搜尋引擎。
- 文件儲存並且被索引在分片中,但是我們的程式並不會直接與它們通訊。取而代之,它們直接與索引進行通訊的
- 把分片想象成一個數據的容器。資料被儲存在分片中,然後分片又被分配在叢集的節點上。當你的叢集擴充套件或者縮小時,elasticsearch 會自動的在節點之間遷移分配分片,以便叢集保持均衡
- 分片分為 主分片(primary shard) 以及 從分片(replica shard) 兩種。在你的索引中,每一個文件都屬於一個主分片
- 從分片只是主分片的一個副本,它用於提供資料的冗餘副本,在硬體故障時提供資料保護,同時服務於搜尋和檢索這種只讀請求
- 索引中的主分片的數量在索引建立後就固定下來了,但是從分片的數量可以隨時改變。
- 一個索引預設設定了5個主分片,每個主分片有一個從分片對應
ES模組結構
- 模組結構圖如下
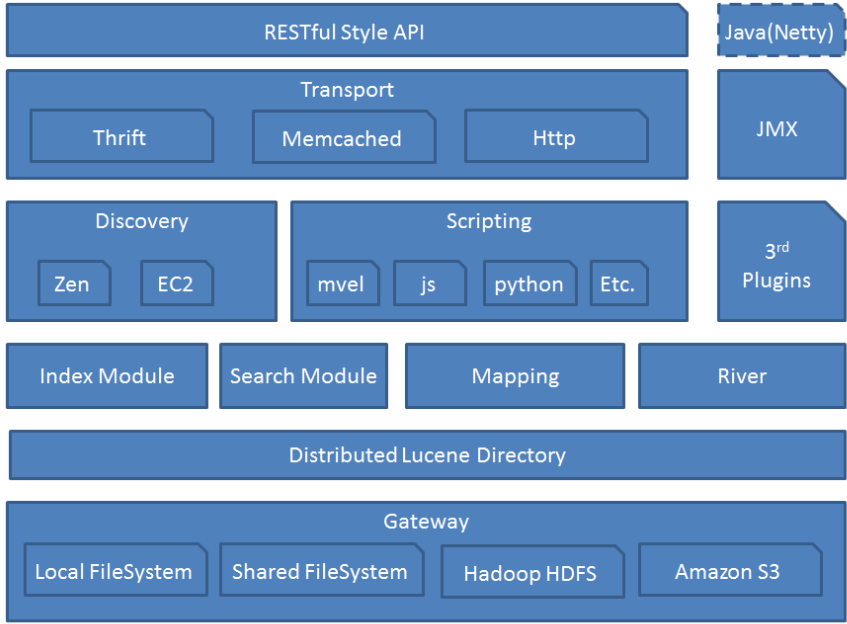
- Gateway: 代表ES的持久化儲存方式,包含索引資訊,ClusterState(叢集資訊),mapping,索引碎片資訊,以及transaction log等
- 對於分散式叢集來說,當一個或多個節點down掉了,能夠保證我們的資料不能丟,最通用的解放方案就是對失敗節點的資料進行復制,通過控制複製的份數可以保證叢集有很高的可用性,複製這個方案的精髓主要是保證操作的時候沒有單點,對一個節點的操作會同步到其他的複製節點上去。
- ES一個索引會拆分成多個碎片,每個碎片可以擁有一個或多個副本(建立索引的時候可以配置),這裡有個例子,每個索引分成3個碎片,每個碎片有2個副本,如下:
$ curl -XPUT http://localhost:9200/twitter/ -d ' index : number_of_shards : 3 number_of_replicas : 2 -
每個操作會自動路由主碎片所在的節點,在上面執行操作,並且同步到其他複製節點,通過使用“non blocking IO”模式所有複製的操作都是並行執行的,也就是說如果你的節點的副本越多,你網路上的流量消耗也會越大。複製節點同樣接受來自外面的讀操作,意義就是你的複製節點越多,你的索引的可用性就越強,對搜尋的可伸縮行就更好,能夠承載更多的操作
- 第一次啟動的時候,它會去持久化裝置讀取叢集的狀態資訊(建立的索引,配置等)然後執行應用它們(建立索引,建立mapping對映等),每一次shard節點第一次例項化加入複製組,它都會從長持久化儲存裡面恢復它的狀態資訊
- Lucence Directory: 是lucene的框架服務發現以及選主 ZenDiscovery: 用來實現節點自動發現,還有Master節點選取,假如Master出現故障,其它的這個節點會自動選舉,產生一個新的Master
- 它是Lucene儲存的一個抽象,由此派生了兩個類:FSDirectory和RAMDirectory,用於控制索引檔案的儲存位置。使用FSDirectory類,就是儲存到硬碟;使用RAMDirectory類,則是儲存到記憶體

- 一個Directory物件是一份檔案的清單。檔案可能只在被建立的時候寫一次。一旦檔案被建立,它將只被讀取或者刪除。在讀取的時候進行寫入操作是允許的
- Discovery
-
- 節點啟動後先ping(這裡的ping是 Elasticsearch 的一個RPC命令。如果 discovery.zen.ping.unicast.hosts 有設定,則ping設定中的host,否則嘗試ping localhost 的幾個埠, Elasticsearch 支援同一個主機啟動多個節點)
- Ping的response會包含該節點的基本資訊以及該節點認為的master節點
- 選舉開始,先從各節點認為的master中選,規則很簡單,按照id的字典序排序,取第一個
- 如果各節點都沒有認為的master,則從所有節點中選擇,規則同上。這裡有個限制條件就是 discovery.zen.minimum_master_nodes,如果節點數達不到最小值的限制,則迴圈上述過程,直到節點數足夠可以開始選舉
- 最後選舉結果是肯定能選舉出一個master,如果只有一個local節點那就選出的是自己
- 如果當前節點是master,則開始等待節點數達到 minimum_master_nodes,然後提供服務, 如果當前節點不是master,則嘗試加入master.
- ES支援任意數目的叢集(1-N),所以不能像 Zookeeper/Etcd 那樣限制節點必須是奇數,也就無法用投票的機制來選主,而是通過一個規則,只要所有的節點都遵循同樣的規則,得到的資訊都是對等的,選出來的主節點肯定是一致的. 但分散式系統的問題就出在資訊不對等的情況,這時候很容易出現腦裂(Split-Brain)的問題,大多數解決方案就是設定一個quorum值,要求可用節點必須大於quorum(一般是超過半數節點),才能對外提供服務。而 Elasticsearch 中,這個quorum的配置就是 discovery.zen.minimum_master_nodes 。
- memcached
-
- 通過memecached協議來訪問ES的介面,支援二進位制和文字兩種協議.通過一個名為transport-memcached外掛提供
- Memcached命令會被對映到REST介面,並且會被同樣的REST層處理,memcached命令列表包括:get/set/delete/quit
- River : 代表es的一個數據源,也是其它儲存方式(如:資料庫)同步資料到es的一個方法。它是以外掛方式存在的一個es服務,通過讀取river中的資料並把它索引到es中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的,river這個功能將會在後面的檔案中重點說到
分片示例
- 啟用一個既沒有資料,也沒有索引的單一節點, 如下圖

- 在空的單節點叢集中上建立一個叫做 blogs 的索引,設定3個主分片和一組從分片(每個主分片有一個從分片對應),程式碼如下:
PUT /blogs { "settings" : { "number_of_shards" : 3, "number_of_replicas" : 1 } } -
叢集示例圖如下: (此時叢集健康狀態為: yellow 三個從分片還沒有被分配到節點上)
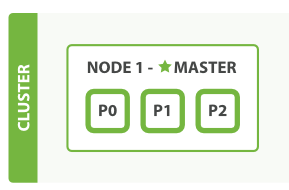

- 主分片(primary shards) 啟動並且運行了,這時叢集已經可以成功的處理任意請求,但是 從分片(replica shards) 沒有完全被啟用。事實上,當前這三個從分片都處於 unassigned(未分配)的狀態,它們還未被分配到節點上。在同一個節點上儲存相同的資料副本是沒有必要的,如果這個節點故障了,就等同於所有的資料副本也丟失了
- 啟動第二個節點,配置第二個節點與第一個節點的 cluster.name 相同(./config/elasticsearch.yml檔案中的配置),它就能自動發現並加入到第一個節點的叢集中,如下圖:


- cluster-health 的狀態為 green,這意味著所有的6個分片(三個主分片和三個從分片)都已啟用,文件在主節點和從節點上都能被檢索
- 隨著應用需求的增長,啟動第三個節點進行橫向擴充套件,叢集內會自動重組,如圖

- 在 Node 1 和 Node 2 中分別會有一個分片被移動到 Node 3 上,這樣一來,每個節點上就都只有兩個分片了。這意味著每個節點的硬體資源(CPU、RAM、I/O)被更少的分片共享,所以每個分片就會有更好的效能表現
- 一共有6個分片(3個主分片和3個從分片),因此最多可以擴充套件到6個節點,每個節點上有一個分片,這樣每個分片都可以使用到所在節點100%的資源了
- 主分片的數量在索引建立的時候就已經指定了,實際上,這個數字定義了能儲存到索引中的資料最大量(具體的數量取決於你的資料,硬體的使用情況)。例如,讀請求——搜尋或者文件恢復就可以由主分片或者從分片來執行,所以當你擁有更多份資料的時候,你就擁有了更大的吞吐量
- 從分片的數量可以在執行的叢集中動態的調整,這樣我們就可以根據實際需求擴充套件或者縮小規模。接下來,我們來增加一下從分片組的數量:
PUT /blogs/_settings { "number_of_replicas" : 2 } -
現在 blogs 的索引總共有9個分片:3個主分片和6個從分片, 又會變成一個節點一個分片的狀態了,最終得到了三倍搜尋效能的三節點叢集
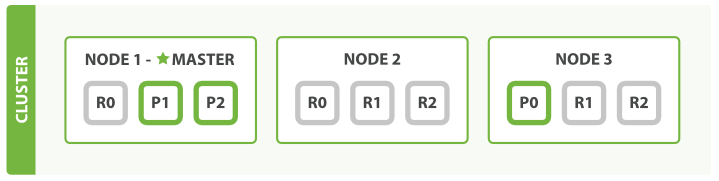
- 說明:僅僅是在同樣數量的節點上增加從分片的數量是根本不能提高效能的,因為每個分片都有訪問系統資源的許可權。你需要升級硬體配置以提高吞吐量。
- 嘗試一下,把第一個節點殺掉,我們的叢集就會如下圖所示:

- 被殺掉的節點是主節點,主分片 1 和 2 在我們殺掉 Node 1 後就丟失了,我們的索引在丟失主節點的時候是不能正常工作的。如果我們在這個時候檢查叢集健康狀態,將會顯示 red:存在不可用的主節點
- 而為了叢集的正常工作必須需要一個主節點,所以首先進行的程序就是從各節點中選擇了一個新的主節點:Node 2
- 新的主節點所完成的第一件事情就是將這些在 Node 2 和 Node 3 上的從分片提升為主分片,然後叢集的健康狀態就變回至 yellow。這個提升的程序是瞬間完成了,就好像按了一下開關
- 如果再次殺掉 Node 2 的時候,我們的程式依舊可以在沒有丟失任何資料的情況下執行,因為 Node 3 中依舊擁有每個分片的備份
- 如果我們重啟 Node 1,叢集就能夠重新分配丟失的從分片,這樣結果就會與三節點兩從叢集一致。如果 Node 1 依舊還有舊節點的內容,系統會嘗試重新利用他們,並只會複製在故障期間的變更資料
--------------------- 本文來自 向上攀爬的程式設計師 的CSDN 部落格 ,全文地址請點選:https://blog.csdn.net/qq_17864929/article/details/54923720?utm_source=copy