
數學基礎-概率論03(統計推斷)
目錄:

統計推斷是通過樣本推斷總體的分佈或者分佈的數字特徵。
1.引數假設檢驗:引數估計
已知一個總體的分佈型別,但是對分佈裡面的引數不清楚,如泊松分佈P(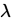 ),正態分佈的N(
),正態分佈的N(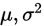 ),這時候需要對這些未知引數進行估計。
),這時候需要對這些未知引數進行估計。
1.1 點估計
點估計:以某個適當的統計量的估測值作為未知引數的估計值
1.1.1 矩估計
矩估計法是用樣本n階矩去估計總體n階矩,n的大小由未知引數決定,在估計的過程中,解得未知引數。
例子:
1.泊松分佈矩估計:已知總體X~P( )[泊松分佈],現有樣本
)[泊松分佈],現有樣本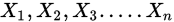 ,求
,求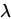 的矩估計量。
的矩估計量。
首先只有一個未知引數,一階矩(期望)可以解決,泊松分佈的一階矩為:
其次樣本的一階矩是
令總體的一階矩等於樣本的一階矩,即 ,解得
,解得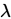 估計量(記為
估計量(記為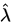 )為:
)為:
2.正態分佈矩估計:已知總體X~N(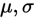 )[正態分佈],現有樣本
)[正態分佈],現有樣本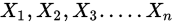 ,求
,求 和
和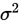 的矩估計量。
的矩估計量。
兩個未知引數,用一階原點矩和二階原點矩解決。並使總體的相應矩等於樣本矩,建立其方程組後,解出兩個引數。
解得: 和
和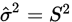
特點:
1.矩估計的方法依賴於抽取的樣本,不同的樣本對應不同的引數估計值,所以具有一定隨意性
2.使用矩估計要求總體存在原點矩,有些隨機變數(如柯西分佈)的原點矩不存在,因此無法使用矩估計
1.1.2 極大似然估計
極大似然估計始於高斯誤差理論,直觀的想法是目前為止所觀測到的事件是最有可能出現的事件。比如你和職業車手比賽,有一人贏了,我們總是傾向於是職業車手贏得比賽。
設總體含有待估計引數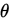 ,他可以取很多值,在這很多值值中取出 使得樣本出現 的概率最大的那些值,稱這些值
,他可以取很多值,在這很多值值中取出 使得樣本出現 的概率最大的那些值,稱這些值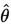 為
為 的極大似然估計。
的極大似然估計。
例子:
1.泊松分佈極大似然估計:已知總體X~P(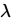 )[泊松分佈],現有樣本
)[泊松分佈],現有樣本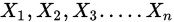 ,求
,求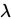 的極大似然估計值。
的極大似然估計值。
已知泊松分佈的分佈律為: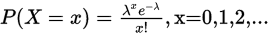
首先得到似然方程,該批次觀測值出現的概率為所以事件的概率乘積,即
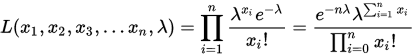
取對數得:
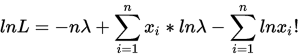
由於L和lnL在同一個 有極值,因此為了求L的極值,可以對lnL使用極限的思想進行分析。
有極值,因此為了求L的極值,可以對lnL使用極限的思想進行分析。

解得 的極大是然估計值(記為
的極大是然估計值(記為 ):
):

特點:
1.不要求總體原點矩存在
2.需要求解似然方程
1.1.3 估計量的評選標準
1.無偏性
假設每次抽樣,對引數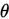 均有一個估計值,記為
均有一個估計值,記為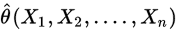 ,若取所有估計值的期望是對引數的
,若取所有估計值的期望是對引數的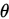 正確無偏估計,即
正確無偏估計,即 ,則
,則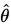 為
為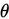 的無偏估計量。
的無偏估計量。
2.有效性
多次抽樣,使用不同的方法計算得到多組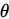 的估計量,這兩組中較穩定的(即方差小)較其他組更為有效的估計。方差反映估計值在真實值附近更為“集中”。
的估計量,這兩組中較穩定的(即方差小)較其他組更為有效的估計。方差反映估計值在真實值附近更為“集中”。
3.一致性(相合性)
毫無疑問,抽取樣本的容量越大,對未知引數的估計越接近真實值,估計量的這種性質稱為一致性(相合性)
相合估計量:
設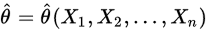 為未知引數
為未知引數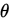 的估計量,若
的估計量,若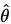 依概率收斂於
依概率收斂於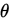 ,則對任意
,則對任意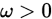 ,有
,有
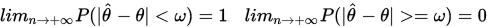
此時,稱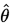 為
為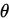 (弱)相合估計量。
(弱)相合估計量。
注:
1.一般而言,三個估計量評選標準只要滿足前面兩個標準就不錯了,因為使用一致性要求樣本容量足夠大
以下很快補上...........
1.2 區間估計
區間估計:用兩個統計量的觀測值鎖確定的區間來估計未知引數的大致範圍