
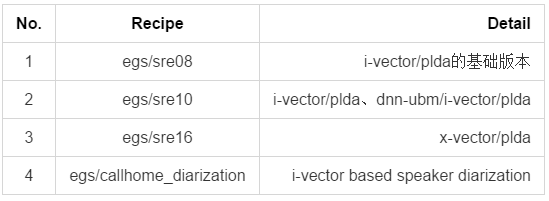
KALDI中聲紋識別學習流程及資源
- KALDI工具包中的例子
首先最基礎的就是egs/aishell/V1,先跑通它,並理解程式碼和基礎理論知識。
- egs/sre08
REMAD.TXT
系統開發所需的資料(除了所描述的測試資料之外) 在../README.txt)中,由Fisher,過去的NIST SRE和Switchboard組成 蜂窩。 你可以只用Fisher的一部分就可以了。 演講稿(見注) Fisher第1部分LDC2004S13 LDC2004T19 Fisher第2部分LDC2005S13 LDC2005T19 SRE 2004測試LDC2006S44 SRE 2005測試LDC2011S04 SWBD Cellular 1 LDC2001S13 SWBD Cellular 2 LDC2004S07 注意: 帶有成績單的分發並不是真正需要的 成績單本身,但因為那是演講者的資訊 居住(所以我們知道哪些錄音來自同一個演講者)。 這是 需要PLDA估算。 但是,請記住費舍爾不相信 對於像PLDA估計這樣的事情非常好。 在較新的食譜,如 ../../sre10/v1我們使用過去的SRE資料進行PLDA估算。
run.sh
. ./cmd.sh . ./path.sh set -e mfccdir=`pwd`/mfcc vaddir=`pwd`/mfcc local/make_fisher.sh /export/corpora3/LDC/{LDC2004S13,LDC2004T19} data/fisher1 #Processed 4948 utterances; 902 had missing wav data. (note: we should figure #out why so much data goes missing.) local/make_fisher.sh /export/corpora3/LDC/{LDC2005S13,LDC2005T19} data/fisher2 #Processed 5848 utterances; 1 had missing wav data. local/make_sre_2005_test.pl /export/corpora5/LDC/LDC2011S04 data local/make_sre_2004_test.pl \ /export/corpora5/LDC/LDC2006S44/r93_5_1/sp04-05/test data/sre_2004_1 local/make_sre_2004_test.pl \ /export/corpora5/LDC/LDC2006S44/r93_6_1/sp04-06/test data/sre_2004_2 local/make_sre_2008_train.pl /export/corpora5/LDC/LDC2011S05 data local/make_sre_2008_test.sh /export/corpora5/LDC/LDC2011S08 data local/make_sre_2006_train.pl /export/corpora5/LDC/LDC2011S09 data local/make_sre_2005_train.pl /export/corpora5/LDC/LDC2011S01 data local/make_swbd_cellular1.pl /export/corpora5/LDC/LDC2001S13 \ data/swbd_cellular1_train local/make_swbd_cellular2.pl /export/corpora5/LDC/LDC2004S07 \ data/swbd_cellular2_train utils/combine_data.sh data/train data/fisher1 data/fisher2 \ data/swbd_cellular1_train data/swbd_cellular2_train \ data/sre05_train_3conv4w_female data/sre05_train_8conv4w_female \ data/sre06_train_3conv4w_female data/sre06_train_8conv4w_female \ data/sre05_train_3conv4w_male data/sre05_train_8conv4w_male \ data/sre06_train_3conv4w_male data/sre06_train_8conv4w_male \ data/sre_2004_1/ data/sre_2004_2/ data/sre05_test mfccdir=`pwd`/mfcc vaddir=`pwd`/mfcc set -e steps/make_mfcc.sh --mfcc-config conf/mfcc.conf --nj 40 --cmd "$train_cmd" \ data/train exp/make_mfcc $mfccdir steps/make_mfcc.sh --mfcc-config conf/mfcc.conf --nj 40 --cmd "$train_cmd" \ data/sre08_train_short2_female exp/make_mfcc $mfccdir steps/make_mfcc.sh --mfcc-config conf/mfcc.conf --nj 40 --cmd "$train_cmd" \ data/sre08_train_short2_male exp/make_mfcc $mfccdir steps/make_mfcc.sh --mfcc-config conf/mfcc.conf --nj 40 --cmd "$train_cmd" \ data/sre08_test_short3_female exp/make_mfcc $mfccdir steps/make_mfcc.sh --mfcc-config conf/mfcc.conf --nj 40 --cmd "$train_cmd" \ data/sre08_test_short3_male exp/make_mfcc $mfccdir sid/compute_vad_decision.sh --nj 4 --cmd "$train_cmd" \ data/train exp/make_vad $vaddir sid/compute_vad_decision.sh --nj 4 --cmd "$train_cmd" \ data/sre08_train_short2_female exp/make_vad $vaddir sid/compute_vad_decision.sh --nj 4 --cmd "$train_cmd" \ data/sre08_train_short2_male exp/make_vad $vaddir sid/compute_vad_decision.sh --nj 4 --cmd "$train_cmd" \ data/sre08_test_short3_female exp/make_vad $vaddir sid/compute_vad_decision.sh --nj 4 --cmd "$train_cmd" \ data/sre08_test_short3_male exp/make_vad $vaddir # Note: to see the proportion of voiced frames you can do, # grep Prop exp/make_vad/vad_*.1.log # Get male and female subsets of training data. grep -w m data/train/spk2gender | awk '{print $1}' > foo; utils/subset_data_dir.sh --spk-list foo data/train data/train_male grep -w f data/train/spk2gender | awk '{print $1}' > foo; utils/subset_data_dir.sh --spk-list foo data/train data/train_female rm foo # Get smaller subsets of training data for faster training. utils/subset_data_dir.sh data/train 4000 data/train_4k utils/subset_data_dir.sh data/train 8000 data/train_8k utils/subset_data_dir.sh data/train_male 8000 data/train_male_8k utils/subset_data_dir.sh data/train_female 8000 data/train_female_8k # The recipe currently uses delta-window=3 and delta-order=2. However # the accuracy is almost as good using delta-window=4 and delta-order=1 # and could be faster due to lower dimensional features. Alternative # delta options (e.g., --delta-window 4 --delta-order 1) can be provided to # sid/train_diag_ubm.sh. The options will be propagated to the other scripts. sid/train_diag_ubm.sh --nj 30 --cmd "$train_cmd" data/train_4k 2048 \ exp/diag_ubm_2048 sid/train_full_ubm.sh --nj 30 --cmd "$train_cmd" data/train_8k \ exp/diag_ubm_2048 exp/full_ubm_2048 sid/train_full_ubm.sh --nj 30 --cmd "$train_cmd" data/train_8k \ exp/diag_ubm_2048 exp/full_ubm_2048 # Get male and female versions of the UBM in one pass; make sure not to remove # any Gaussians due to low counts (so they stay matched). This will be # more convenient for gender-id. sid/train_full_ubm.sh --nj 30 --remove-low-count-gaussians false \ --num-iters 1 --cmd "$train_cmd" \ data/train_male_8k exp/full_ubm_2048 exp/full_ubm_2048_male & sid/train_full_ubm.sh --nj 30 --remove-low-count-gaussians false \ --num-iters 1 --cmd "$train_cmd" \ data/train_female_8k exp/full_ubm_2048 exp/full_ubm_2048_female & wait # Train the iVector extractor for male speakers. sid/train_ivector_extractor.sh --cmd "$train_cmd --mem 35G" \ --num-iters 5 exp/full_ubm_2048_male/final.ubm data/train_male \ exp/extractor_2048_male # The same for female speakers. sid/train_ivector_extractor.sh --cmd "$train_cmd --mem 35G" \ --num-iters 5 exp/full_ubm_2048_female/final.ubm data/train_female \ exp/extractor_2048_female # The script below demonstrates the gender-id script. We don't really use # it for anything here, because the SRE 2008 data is already split up by # gender and gender identification is not required for the eval. # It prints out the error rate based on the info in the spk2gender file; # see exp/gender_id_fisher/error_rate where it is also printed. sid/gender_id.sh --cmd "$train_cmd" --nj 150 exp/full_ubm_2048{,_male,_female} \ data/train exp/gender_id_train # Gender-id error rate is 3.41% # Extract the iVectors for the training data. sid/extract_ivectors.sh --cmd "$train_cmd --mem 6G" --nj 50 \ exp/extractor_2048_male data/train_male exp/ivectors_train_male sid/extract_ivectors.sh --cmd "$train_cmd --mem 6G" --nj 50 \ exp/extractor_2048_female data/train_female exp/ivectors_train_female # .. and for the SRE08 training and test data. (We focus on the main # evaluation condition, the only required one in that eval, which is # the short2-short3 eval.) sid/extract_ivectors.sh --cmd "$train_cmd --mem 6G" --nj 50 \ exp/extractor_2048_female data/sre08_train_short2_female \ exp/ivectors_sre08_train_short2_female sid/extract_ivectors.sh --cmd "$train_cmd --mem 6G" --nj 50 \ exp/extractor_2048_male data/sre08_train_short2_male \ exp/ivectors_sre08_train_short2_male sid/extract_ivectors.sh --cmd "$train_cmd --mem 6G" --nj 50 \ exp/extractor_2048_female data/sre08_test_short3_female \ exp/ivectors_sre08_test_short3_female sid/extract_ivectors.sh --cmd "$train_cmd --mem 6G" --nj 50 \ exp/extractor_2048_male data/sre08_test_short3_male \ exp/ivectors_sre08_test_short3_male ### Demonstrate simple cosine-distance scoring: trials=data/sre08_trials/short2-short3-female.trials # Note: speaker-level i-vectors have already been length-normalized # by sid/extract_ivectors.sh, but the utterance-level test i-vectors # have not. cat $trials | awk '{print $1, $2}' | \ ivector-compute-dot-products - \ scp:exp/ivectors_sre08_train_short2_female/spk_ivector.scp \ 'ark:ivector-normalize-length scp:exp/ivectors_sre08_test_short3_female/ivector.scp ark:- |' \ foo local/score_sre08.sh $trials foo # Results for Female: # Scoring against data/sre08_trials/short2-short3-female.trials # Condition: 0 1 2 3 4 5 6 7 8 # EER: 12.70 20.09 4.78 19.08 16.37 15.87 10.42 7.10 7.89 trials=data/sre08_trials/short2-short3-male.trials cat $trials | awk '{print $1, $2}' | \ ivector-compute-dot-products - \ scp:exp/ivectors_sre08_train_short2_male/spk_ivector.scp \ 'ark:ivector-normalize-length scp:exp/ivectors_sre08_test_short3_male/ivector.scp ark:- |' \ foo local/score_sre08.sh $trials foo # Results for Male: # Scoring against data/sre08_trials/short2-short3-male.trials # Condition: 0 1 2 3 4 5 6 7 8 # EER: 11.10 18.55 5.24 18.03 14.35 13.44 8.47 5.92 4.82 # The following shows a more direct way to get the scores. # condition=6 # awk '{print $3}' foo | paste - $trials | awk -v c=$condition '{n=4+c; \\ # if ($n == "Y") print $1, $4}' | \ # compute-eer - # LOG (compute-eer:main():compute-eer.cc:136) Equal error rate is 11.10%, # at threshold 55.9827 # Note: to see how you can plot the DET curve, look at # local/det_curve_example.sh ### Demonstrate what happens if we reduce the dimension with LDA ivector-compute-lda --dim=150 --total-covariance-factor=0.1 \ 'ark:ivector-normalize-length scp:exp/ivectors_train_female/ivector.scp ark:- |' \ ark:data/train_female/utt2spk \ exp/ivectors_train_female/transform.mat trials=data/sre08_trials/short2-short3-female.trials cat $trials | awk '{print $1, $2}' | \ ivector-compute-dot-products - \ 'ark:ivector-transform exp/ivectors_train_female/transform.mat scp:exp/ivectors_sre08_train_short2_female/spk_ivector.scp ark:- | ivector-normalize-length ark:- ark:- |' \ 'ark:ivector-normalize-length scp:exp/ivectors_sre08_test_short3_female/ivector.scp ark:- | ivector-transform exp/ivectors_train_female/transform.mat ark:- ark:- | ivector-normalize-length ark:- ark:- |' \ foo local/score_sre08.sh $trials foo # Results for Female: # Scoring against data/sre08_trials/short2-short3-female.trials # Condition: 0 1 2 3 4 5 6 7 8 # EER: 7.96 9.82 1.49 9.44 10.51 10.70 8.81 5.83 7.11 ivector-compute-lda --dim=150 --total-covariance-factor=0.1 \ 'ark:ivector-normalize-length scp:exp/ivectors_train_male/ivector.scp ark:- |' \ ark:data/train_male/utt2spk \ exp/ivectors_train_male/transform.mat trials=data/sre08_trials/short2-short3-male.trials cat $trials | awk '{print $1, $2}' | \ ivector-compute-dot-products - \ 'ark:ivector-transform exp/ivectors_train_male/transform.mat scp:exp/ivectors_sre08_train_short2_male/spk_ivector.scp ark:- | ivector-normalize-length ark:- ark:- |' \ 'ark:ivector-normalize-length scp:exp/ivectors_sre08_test_short3_male/ivector.scp ark:- | ivector-transform exp/ivectors_train_male/transform.mat ark:- ark:- | ivector-normalize-length ark:- ark:- |' \ foo local/score_sre08.sh $trials foo # Results for Male: # Scoring against data/sre08_trials/short2-short3-male.trials # Condition: 0 1 2 3 4 5 6 7 8 # EER: 6.20 8.30 1.21 8.10 8.43 7.03 7.32 5.70 3.51 ### Demonstrate PLDA scoring: ## Note: below, the ivector-subtract-global-mean step doesn't appear to affect ## the EER, although it does shift the threshold. trials=data/sre08_trials/short2-short3-female.trials ivector-compute-plda ark:data/train_female/spk2utt \ 'ark:ivector-normalize-length scp:exp/ivectors_train_female/ivector.scp ark:- |' \ exp/ivectors_train_female/plda 2>exp/ivectors_train_female/log/plda.log ivector-plda-scoring --simple-length-normalization=true --num-utts=ark:exp/ivectors_sre08_train_short2_female/num_utts.ark \ "ivector-copy-plda --smoothing=0.0 exp/ivectors_train_female/plda - |" \ "ark:ivector-subtract-global-mean scp:exp/ivectors_sre08_train_short2_female/spk_ivector.scp ark:- |" \ "ark:ivector-normalize-length scp:exp/ivectors_sre08_test_short3_female/ivector.scp ark:- | ivector-subtract-global-mean ark:- ark:- |" \ "cat '$trials' | awk '{print \$1, \$2}' |" foo local/score_sre08.sh $trials foo # Result for Female is below: # Scoring against data/sre08_trials/short2-short3-female.trials # Condition: 0 1 2 3 4 5 6 7 8 # EER: 6.44 9.76 1.49 9.76 7.66 7.21 6.87 4.06 4.74 trials=data/sre08_trials/short2-short3-male.trials ivector-compute-plda ark:data/train_male/spk2utt \ 'ark:ivector-normalize-length scp:exp/ivectors_train_male/ivector.scp ark:- |' \ exp/ivectors_train_male/plda 2>exp/ivectors_train_male/log/plda.log ivector-plda-scoring --simple-length-normalization=true --num-utts=ark:exp/ivectors_sre08_train_short2_male/num_utts.ark \ "ivector-copy-plda --smoothing=0.0 exp/ivectors_train_male/plda - |" \ "ark:ivector-subtract-global-mean scp:exp/ivectors_sre08_train_short2_male/spk_ivector.scp ark:- |" \ "ark:ivector-normalize-length scp:exp/ivectors_sre08_test_short3_male/ivector.scp ark:- | ivector-subtract-global-mean ark:- ark:- |" \ "cat '$trials' | awk '{print \$1, \$2}' |" foo; local/score_sre08.sh $trials foo # Result for Male is below: # Scoring against data/sre08_trials/short2-short3-male.trials # Condition: 0 1 2 3 4 5 6 7 8 # EER: 4.68 7.41 1.21 7.48 5.70 4.69 5.61 3.19 2.19 ### Demonstrate PLDA scoring after adapting the out-of-domain PLDA model with in-domain training data: # first, female. trials=data/sre08_trials/short2-short3-female.trials cat exp/ivectors_sre08_train_short2_female/spk_ivector.scp exp/ivectors_sre08_test_short3_female/ivector.scp > female.scp ivector-plda-scoring --simple-length-normalization=true --num-utts=ark:exp/ivectors_sre08_train_short2_female/num_utts.ark \ "ivector-adapt-plda $adapt_opts exp/ivectors_train_female/plda scp:female.scp -|" \ scp:exp/ivectors_sre08_train_short2_female/spk_ivector.scp \ "ark:ivector-normalize-length scp:exp/ivectors_sre08_test_short3_female/ivector.scp ark:- |" \ "cat '$trials' | awk '{print \$1, \$2}' |" foo; local/score_sre08.sh $trials foo # Results: # Condition: 0 1 2 3 4 5 6 7 8 # EER: 5.45 6.73 1.19 6.79 7.06 6.61 6.32 4.18 4.74 # Baseline (repeated from above): # Condition: 0 1 2 3 4 5 6 7 8 # EER: 6.44 9.76 1.49 9.76 7.66 7.21 6.87 4.06 4.74 trials=data/sre08_trials/short2-short3-male.trials ivector-compute-plda ark:data/train_male/spk2utt \ 'ark:ivector-normalize-length scp:exp/ivectors_train_male/ivector.scp ark:- |' \ exp/ivectors_train_male/plda 2>exp/ivectors_train_male/log/plda.log ivector-plda-scoring --simple-length-normalization=true --num-utts=ark:exp/ivectors_sre08_train_short2_male/num_utts.ark \ "ivector-copy-plda --smoothing=0.0 exp/ivectors_train_male/plda - |" \ "ark:ivector-subtract-global-mean scp:exp/ivectors_sre08_train_short2_male/spk_ivector.scp ark:- |" \ "ark:ivector-normalize-length scp:exp/ivectors_sre08_test_short3_male/ivector.scp ark:- | ivector-subtract-global-mean ark:- ark:- |" \ "cat '$trials' | awk '{print \$1, \$2}' |" foo; local/score_sre08.sh $trials foo # Result for Male is below: # Scoring against data/sre08_trials/short2-short3-male.trials # Condition: 0 1 2 3 4 5 6 7 8 # EER: 4.68 7.41 1.21 7.48 5.70 4.69 5.61 3.19 2.19 ### Demonstrate PLDA scoring after adapting the out-of-domain PLDA model with in-domain training data: # first, female. trials=data/sre08_trials/short2-short3-female.trials cat exp/ivectors_sre08_train_short2_female/spk_ivector.scp exp/ivectors_sre08_test_short3_female/ivector.scp > female.scp ivector-plda-scoring --simple-length-normalization=true --num-utts=ark:exp/ivectors_sre08_train_short2_female/num_utts.ark \ "ivector-adapt-plda $adapt_opts exp/ivectors_train_female/plda scp:female.scp -|" \ scp:exp/ivectors_sre08_train_short2_female/spk_ivector.scp \ "ark:ivector-normalize-length scp:exp/ivectors_sre08_test_short3_female/ivector.scp ark:- |" \ "cat '$trials' | awk '{print \$1, \$2}' |" foo; local/score_sre08.sh $trials foo # Results: # Condition: 0 1 2 3 4 5 6 7 8 # EER: 5.45 6.73 1.19 6.79 7.06 6.61 6.32 4.18 4.74 # Baseline (repeated from above): # Condition: 0 1 2 3 4 5 6 7 8 # EER: 6.44 9.76 1.49 9.76 7.66 7.21 6.87 4.06 4.74 # next, male. trials=data/sre08_trials/short2-short3-male.trials cat exp/ivectors_sre08_train_short2_male/spk_ivector.scp exp/ivectors_sre08_test_short3_male/ivector.scp > male.scp ivector-plda-scoring --simple-length-normalization=true --num-utts=ark:exp/ivectors_sre08_train_short2_male/num_utts.ark \ "ivector-adapt-plda $adapt_opts exp/ivectors_train_male/plda scp:male.scp -|" \ scp:exp/ivectors_sre08_train_short2_male/spk_ivector.scp \ "ark:ivector-normalize-length scp:exp/ivectors_sre08_test_short3_male/ivector.scp ark:- |" \ "cat '$trials' | awk '{print \$1, \$2}' |" foo; local/score_sre08.sh $trials foo # Results: # Condition: 0 1 2 3 4 5 6 7 8 # EER: 4.03 4.71 0.81 4.73 5.01 4.84 5.61 3.87 2.63 # Baseline is as follows, repeated from above. Focus on condition 0 (= all). # Condition: 0 1 2 3 4 5 6 7 8 # EER: 4.68 7.41 1.21 7.48 5.70 4.69 5.61 3.19 2.19
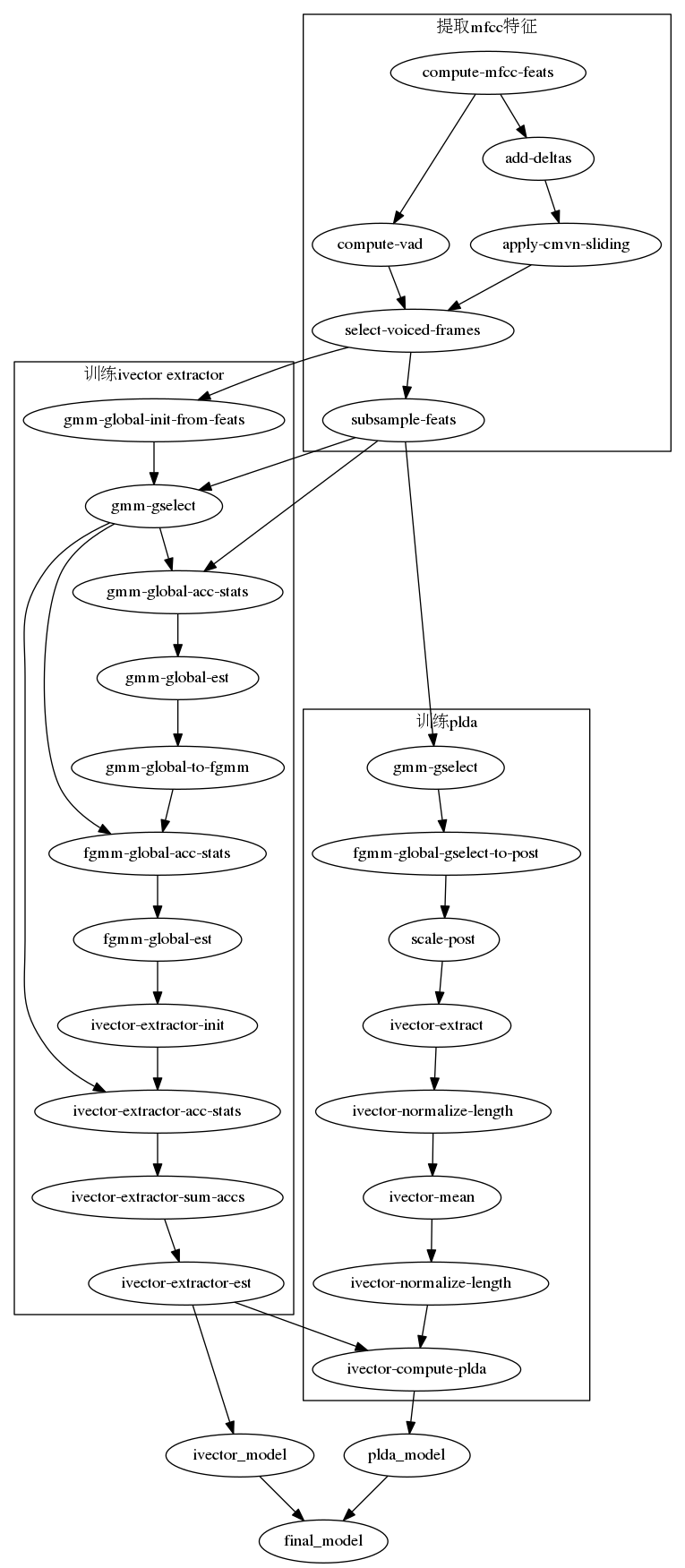
2kaldi中的聲紋流程圖
2. TensorFlow-based Deep Speaker
實現ResNet網路上的TE2E(Tuple-base end-to-end)Loss function訓練方式。安裝TensorFlow、Python3和FFMPEG(檔案格式轉換工具)後,準備好資料,即可一鍵訓練。只可惜驗證部分還沒做,而且GRU沒實現、tensor實現部分也不嚴謹,可詳細閱讀程式碼和論文,並貢獻下您的程式碼。
- 原始碼地址:https://github.com/philipperemy/deep-speaker
- 論文地址:Deep Speaker: an End-to-End Neural Speaker Embedding System
- 資料集合:http://www.robots.ox.ac.uk/~vgg/data/voxceleb/
3. PyTorch-based Deep Speaker
基於百度論文[1],實現了ResNet + Triplet Loss。不過在 牛津大學的Voxceleb庫上,EER比論文[2]所宣稱的(7.8%)要高不少,看來實現還是有改進空間。Owner在求助了,大家幫幫忙contribute。
- 原始碼地址:https://github.com/qqueing/DeepSpeaker-pytorch
- 論文地址:Deep Speaker: an End-to-End Neural Speaker Embedding System
4. TristouNet from pyannote-audio
一個音訊處理工具箱,包括Speech change detection, feature extraction, speaker embeddings extraction以及speech activity detection。其中speaker embeddings extraction部分,包括TristouNet的實現。
- 原始碼地址:https://github.com/pyannote/pyannote-audio
- 論文地址:TristouNet: Triplet Loss for Speaker Turn Embedding
5. CNN-based Speaker verification
Convolutional Neural Networks(卷積神經網路)在聲紋識別上的試驗,一個不錯的嘗試,可以與TDNN/x-vector做下對比。
- 原始碼地址:https://github.com/astorfi/3D-convolutional-speaker-recognition
- 論文地址:Text-Independent Speaker Verification Using 3D Convolutional Neural Networks
- 資料集合:https://biic.wvu.edu/data-sets/multimodal-dataset
聲紋識別基礎理論論文
這個部落格就是把最具有代表性的資料記錄下來,前提,我假設你知道啥是MFCC,啥是VAD,啥是CMVN了.
說話人識別學習路徑無非就是 GMM-UBM -> JFA -> Ivector-PLDA -> DNN embeddings -> E2E
首先 GMM-UBM, 最經典代表作: Speaker Verification Using Adapted Gaussian Mixture Models
從訓練普遍人聲紋特徵的UBM到經過MAP的目標人GMM-UBM到後面的識別的分數似然比,分數規整都有介紹,老哥Reynold MIT教授,這篇論文可以說是說話人識別開發者必讀
(然後,直接跳過JFA吧)JFA太多太繁瑣,但假如你是個熱愛學習的好孩子,那想必這篇論文你應該很喜歡 Patrick Kenny的: Eigenvoice Modeling With Sparse Training Data
接下來我們來看看Ivector, ivector的理論,ivector 總變化空間矩陣的訓練.
首先你需要知道Ivector的理論知識, 所以經典中的經典: Front-End Factor Analysis for Speaker Verification
訓練演算法推薦: A Straightforward and Efficient Implementation of the Factor Analysis Model for Speaker Verification
但假如你很喜歡數學,Patrick Kenny的這篇結合Eigenvoice應該很適合你: A Small Footprint i-Vector Extractor
到這裡,基本上從GMM-UBM 到IVECTOR的理論和訓練,你只要讀完以上,再加上kaldi的一些小實驗,相信聰明的朋友們絕對沒問題.
Kaldi參考:train_ivector_extractor.sh和extract_ivector.sh,注意要看他們的底層C++,對著公式來,然後注意裡面的符號跟論文的符號是不同的,之前的部落格有說過. 你會發現,跟因子分析有關的論文不管是JFA還是Ivector都會有Patrick Kenny這個人物!沒有錯,這老哥公式狂魔,很猛很變態,對於很多知識點,跟著它公式推導的思路來絕對會沒錯,但對於像我這種數學渣,我會直接跳過.
記下來我們來看看PLDA的訓練和打分
首先, 需要知道PLDA的理論,他從影象識別發展而來的,也跟因子分析有關.參考:Probabilistic Linear Discriminant Analysis for Inferences About Identity
PLDA的引數訓練請主要看他的EM的演算法,在該論文的APPENDIX裡面
接著是PLDA的打分識別,請參考: Analysis of I-vector Length Normalization in Speaker Recognition Systems
將EM訓練好的PLDA引數結合著兩個IVECTOR進行打分, 這篇論文值得擁有,另外推薦Daniel Garcia-Romero,這老哥的論文多通俗易懂, 重點清晰不含糊, 並且這老哥在speaker diarization的造詣很高,在x-vector也很活躍,十分推薦.
接著來看看深度學習的東西
首先給個直覺,為什麼要用深度學習,說話人能用DNN,如何借鑑語音識別在DNN的應用,參考: NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK
有了DNN的技術後, 各種老哥們開始用embeddings的方法取代ivector的方法,最開始的是GOOGLE的 d-vector
d-vector: DEEP NEURAL NETWORKS FOR SMALL FOOTPRINT TEXT-DEPENDENT SPEAKER VERIFICATION
d-vector: End-to-End Text-Dependent Speaker Verification
然後眾所周知,說話人識別or聲紋識別對語音的時長是很敏感的,短時音訊的識別效能是決定能不商用的一個很關鍵的點,所以x-vector應運而生,也是JHU的那幫人,就是Kaldi的團隊
x-vector前身 : DEEP NEURAL NETWORK-BASED SPEAKER EMBEDDINGS FOR END-TO-END SPEAKER VERIFICATION
x-vector底座: IME DELAY DEEP NEURAL NETWORK-BASED UNIVERSAL BACKGROUND MODELS FOR SPEAKER RECOGNITION
x-vector正宮: X-VECTORS: ROBUST DNN EMBEDDINGS FOR SPEAKER RECOGNITION
然後然後呢,牛逼的Triplet Loss出來了, 輸入是一個三元組,目的就是提升效能,(但我實驗的過程經常會不收斂,攤手,本渣也不知道為什麼)
Triplet Loss : TRISTOUNET: TRIPLET LOSS FOR SPEAKER TURN EMBEDDING
Triplet Loss : End-to-End Text-Independent Speaker Verification with Triplet Loss on Short Utterances
Deep speaker: Deep Speaker: an End-to-End Neural Speaker Embedding System
最後E2E,但可能我個人才疏學淺,感覺論文上說的E2E其實都是做了一個EMBEDDING出來,然後外接cosine distance,但真正的EMBEDDING是輸入註冊和測試音訊,直接輸出分數.
參考文章:
1.https://zhuanlan.zhihu.com/p/35687281
2.https://blog.csdn.net/robingao1994/article/details/80320999
3.https://blog.csdn.net/robingao1994/article/details/82659005