
語音識別、聲紋識別的區別及測試

很多除接觸AI的小夥伴, 不清楚語音識別和聲紋識別的區別,經常混淆概念,以為語音識別、聲紋識別、語義識別是同一回事,其實不然。這篇文章主要為小夥伴普及一下這三者的區別, 並且分別講一講如何測試。
語音識別、聲紋識別、語義識別的區別
聲紋識別和語音識別在原理上一樣,都是通過對採集到的語音訊號進行分析和處理,提取相應的特徵或建立相應的模型,然後據此做出判斷。但二者的根本目的,提取的特徵、建立的模型是不一樣的。
語音識別的目的:識別語音的內容。並以電腦自動將人類的語音內容轉換為相應的文字。
聲紋識別的目的:識別說話人的身份。又稱說話人識別,是生物識別技術的一種。
語義識別的目的:對語音識別出來的內容進行語義理解和糾正。比如同聲翻譯機。
聲紋識別,是通過語音波形中反映說話人生理和行為特徵的語音引數,進而連線到聲紋庫,一般式公安部聲紋資料庫,鑑別人的身份。所承載的功能特點和人臉識別是一樣的,都是為了證明,“你是張三,還是李四”。
因此,聲紋識別不注重語音訊號的語義,而是從語音訊號中提取個人聲紋特徵,挖掘出包含在語音訊號中的個性因素。
而語音識別是從不同人的詞語訊號中尋找共同因素。
關於語音識別和聲紋識別的測試重點分析
語音識別已經是比較成熟,測試的重點是聲音的錄入、及內容的識別準確性。
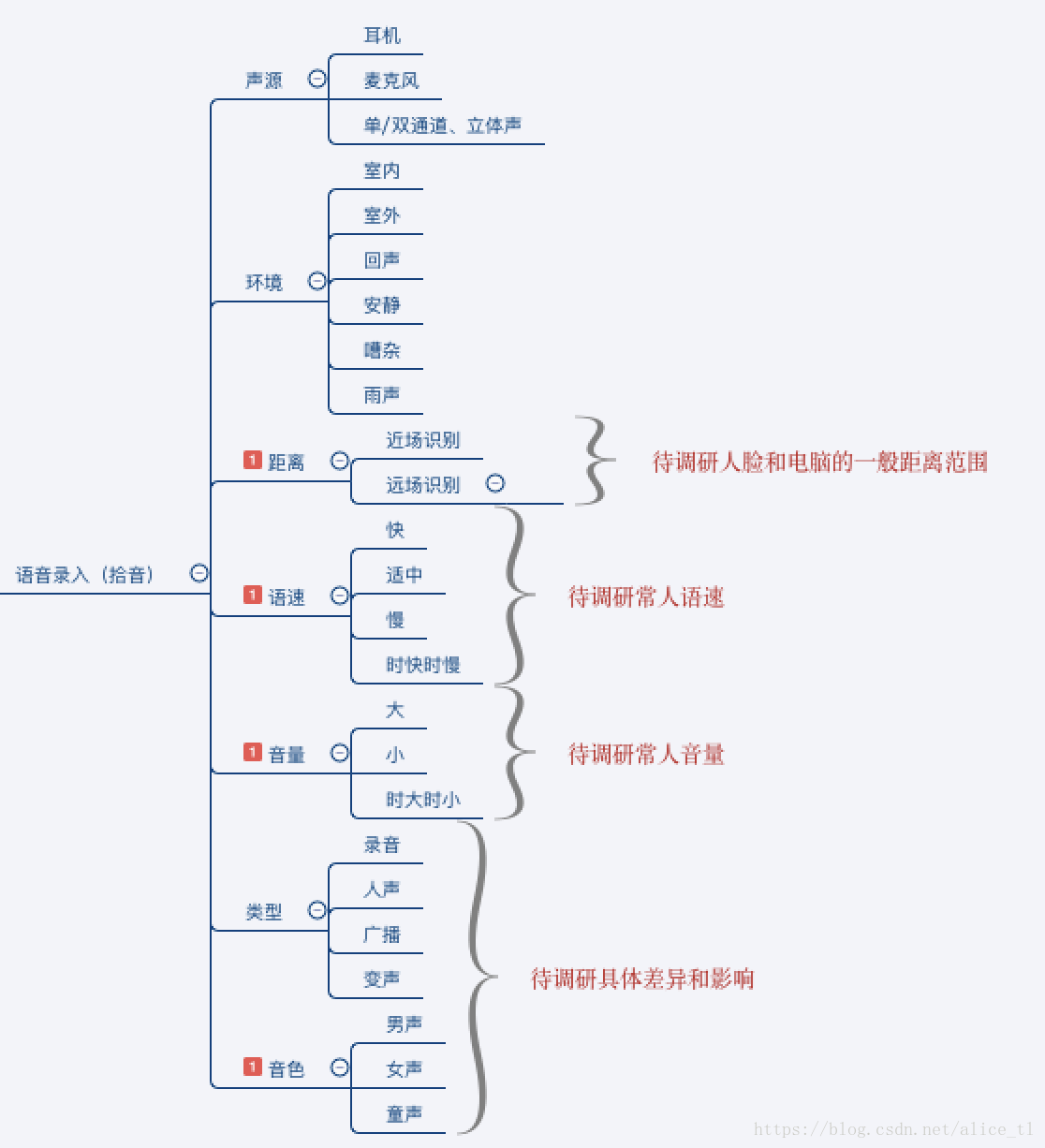
對聲音的錄入,也叫拾音而言:
1、錄入時的聲源、環境影響、距離影響
2、講話人的語速、音量、音色等(通過對幾家語音識別的開放demo進行評測後,發現女聲的語音識別準確度要高過於男聲)
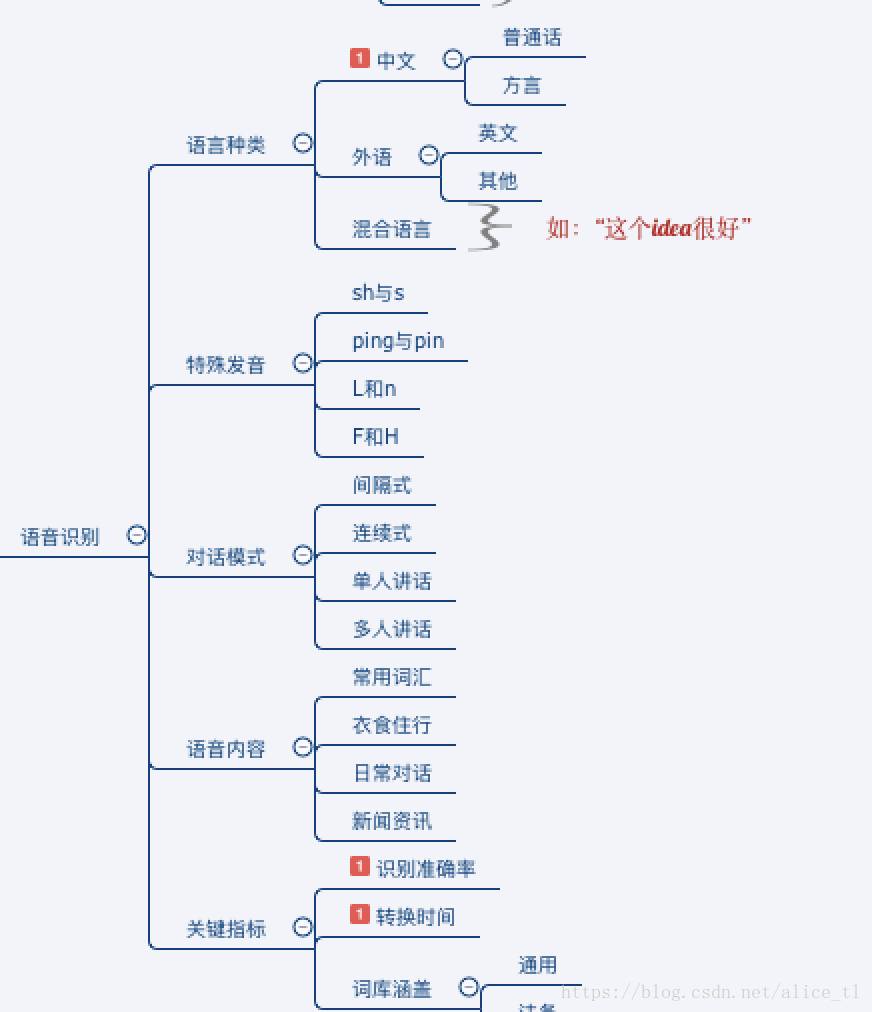
對於識別的內容準確性而言,要考慮:
1、語種的覆蓋,中文普通話、方言等,英文以及其他的外語等
2、語音的內容覆蓋日常對話、衣食住行、新聞資訊等等
3、詞庫的涵蓋,比如出了通用詞庫,是否包含了應用場景比如金融、法律、醫療對應領域的詞庫訓練
4、不標準的發音和吐詞等
聲紋識別的測試
常見的聲紋識別有固定數字、隨機數字、固定文字和隨機文字,以及其他的衍生等等。
不同於人類的雙耳,機器的識別都是在數以百萬、千萬計的資料訓練中不斷改善的,如果沒有足夠的資料支援, 不能全方位的對聲紋識別演算法進行訓練。
理論上來講,聲紋就像指紋一樣,很少會有兩個人具有相同的聲紋特徵。但比如雙胞胎、親屬等,均可能存在極其相似的聲音特徵。另外說話環境、說話人身體健康狀況、情緒變化等都能對聲紋識別的結果造成極大影響。
因此聲紋識別的重點在於是否能夠輕易的被相似特徵的聲音攻擊。