大資料下基於Tensorflow框架的深度學習示例教程
近幾年,資訊時代的快速發展產生了海量資料,誕生了無數前沿的大資料技術與應用。在當今大資料時代的產業界,商業決策日益基於資料的分析作出。當資料膨脹到一定規模時,基於機器學習對海量複雜資料的分析更能產生較好的價值,而深度學習在大資料場景下更能揭示資料內部的邏輯關係。本文就以大資料作為場景,通過自底向上的教程詳述在大資料架構體系中如何應用深度學習這一技術。大資料架構中採用的是hadoop系統以及Kerberos安全認證,深度學習採用的是分散式的Tensorflow架構,hadoop解決了大資料的儲存問題,而分散式Tensorflow解決了大資料訓練的問題。本教程是我們團隊在開發基於深度學習的實時欺詐預警服務時,部署深度學習這一模組時總結出的經驗,感興趣的歡迎深入交流。
安裝Tensorflow
我們安裝Tensorflow選擇的是Centos7,因為Tensorflow需要使用GNU釋出的1.5版本的libc庫,Centos6系統並不適用該版本庫而被拋棄。對於如何聯網線上安裝Tensorflow,官網有比較詳盡的教程。本教程著重講一下網上資料較少的離線安裝方式,系統的安裝更需要在意的是各軟體版本的一致性,下面教程也是解決了很多版本不一致的問題後給出的一個方案。首先我們先將整個系統搭建起來吧。
1.安裝程式語言Python3.5:在官網下載軟體並解壓後執行如下安裝命令:
./configure make make test sudo make install
2.安裝基於Python的科學計算包python-numpy:在官網下載軟體並解壓後執行如下安裝命令:
python setup.py install3.安裝Python模組管理的工具wheel:在官網下載軟體後執行如下安裝命令:
pip install wheel-0.30.0a0-py2.py3-none-any.whl4.安裝自動下載、構建、安裝和管理 python 模組的工具setuptools:在官網下載軟體並解壓後執行如下安裝命令:
python setup.py install5.安裝Python開發包python-devel:在官網下載軟體後執行如下安裝命令:
sudo rpm -i --nodeps python3-devel-3.5.2-4.fc25.x86_64.rpm6.安裝Python包安裝管理工具six:在官網下載軟體後執行如下安裝命令:
sudo pip install six-1.10.0-py2.py3-none-any.whl7.安裝Java 開發環境JDK8:在官網下載軟體並解壓後執行如下移動命令:
mv java1.8 /usr/local/software/jdk設定JDK的環境變數,編輯檔案 .bashrc,加入下面內容
export JAVA_HOME=/usr/local/software/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=$CLASSPATH:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$PATH:${JAVA_HOME}/bin進行Java版本的切換,選擇對應的版本
sudo update-alternatives --config java
sudo update-alternatives --config javac8.安裝Bazel:Bazel是一個類似於Make的工具,是Google為其內部軟體開發的特點量身定製的工具,構建Tensorflow專案。在官網下載後執行如下安裝命令:
chmod +x bazel-0.4.3-installer-linux-x86_64.sh
./bazel-0.4.3-installer-linux-x86_64.sh –user9.安裝Tensorflow:在官網下載軟體後執行如下安裝命令:
pip install --upgrade tensorflow-0.12.1-cp35-cp35m-linux_x86_64.whlTensorflow訪問HDFS的部署
1.首先安裝Hadoop客戶端,在官網下載後執行下面解壓移動命令:
tar zxvf hadoop-2.6.0.tar.gz
mv hadoop-2.6.0.tar.gz /usr/local/software/Hadoop進行環境變數的配置/etc/profile,加入如下內容
export PATH=$PATH:/usr/local/software/hadoop/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$JAVA_HOME/jre/lib/amd64/server
export HADOOP_HOME=/usr/local/software/hadoop
export HADOOP_HDFS_HOME=/usr/local/software/hadoop配置完後進行配置更新source /etc/profile
2.其次,安裝完客戶端後,配置自己的hadoop叢集環境檔案。
Tensorflow與Kerberos驗證的部署
在Tesorflow0.12版本中已經支援了Kerberos驗證,本機只要配置好Kerberos檔案即可使用。該文中不詳述Kerberos的配置內容,羅列一下相關的配置流程。
- 首先在/etc/krb5.conf檔案中進行伺服器跟驗證策略的配置;
- 然後在Kerberos服務端生成一個使用者檔案傳至本機;
- 最後進行Kerberos客戶端的許可權認證並設定定時任務。
大資料場景下基於分散式Tensorflow的深度學習示例
一、進行資料格式的轉換
本文的示例是做的MNIST資料的識別模型,為了更好的讀取資料更好的利用記憶體,我們將本地GZ檔案轉換成Tensorflow的內定標準格式TFRecord,然後再將轉換後的檔案上傳到HDFS儲存。在實際應用中,我們實際利用Spark做了大規模格式轉換的處理程式。我們對本地資料處理的相應的轉換程式碼為:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import os
import tensorflow as tf
from tensorflow.contrib.learn.python.learn.datasets import mnist
SOURCE_URL = 'http://yann.lecun.com/exdb/mnist/'
TRAIN_IMAGES = 'train-images-idx3-ubyte.gz' # MNIST filenames
TRAIN_LABELS = 'train-labels-idx1-ubyte.gz'
TEST_IMAGES = 't10k-images-idx3-ubyte.gz'
TEST_LABELS = 't10k-labels-idx1-ubyte.gz'
FLAGS = None
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def convert_to(data_set, name):
images = data_set.images
labels = data_set.labels
num_examples = data_set.num_examples
if images.shape[0] != num_examples:
raise ValueError('Images size %d does not match label size %d.' %
(images.shape[0], num_examples))
rows = images.shape[1]
cols = images.shape[2]
depth = images.shape[3]
filename = os.path.join(FLAGS.directory, name + '.tfrecords')
print('Writing', filename)
writer = tf.python_io.TFRecordWriter(filename)
for index in range(num_examples):
image_raw = images[index].tostring()
example = tf.train.Example(features=tf.train.Features(feature={
'height': _int64_feature(rows),
'width': _int64_feature(cols),
'depth': _int64_feature(depth),
'label': _int64_feature(int(labels[index])),
'image_raw': _bytes_feature(image_raw)}))
writer.write(example.SerializeToString())
writer.close()
def main(argv):
# Get the data.
data_sets = mnist.read_data_sets(FLAGS.directory,
dtype=tf.uint8,
reshape=False,
validation_size=FLAGS.validation_size)
# Convert to Examples and write the result to TFRecords.
convert_to(data_sets.train, 'train')
convert_to(data_sets.validation, 'validation')
convert_to(data_sets.test, 'test')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument(
'--directory',
type=str,
default='/tmp/data',
help='Directory to download data files and write the converted result'
)
parser.add_argument(
'--validation_size',
type=int,
default=5000,
help="""\
Number of examples to separate from the training data for the validation
set.\
"""
)
FLAGS = parser.parse_args()
tf.app.run()二、Tensorflow讀取HDFS資料的設定
文中前面內容介紹了HDFS的配置以及將資料轉換後儲存到HDFS,Tensorflow讀取HDFS時只需要簡單的兩步,首先執行專案時需要加入環境字首:
CLASSPATH=$($HADOOP_HDFS_HOME/bin/hadoop classpath --glob) python example.py其次讀取資料時,需要在資料的路徑前面加入HDFS字首,比如:
hdfs://default/user/data/example.txt三、分散式模型的示例程式碼
該示例程式碼是讀取HDFS上的MNIST資料,建立相應的server與work叢集構建出一個三層的深度網路,包含兩層卷積層以及一層SoftMax層。程式碼如下:
from __future__ import print_function
import math
import os
import tensorflow as tf
flags = tf.app.flags
# Flags for configuring the task
flags.DEFINE_string("job_name", None, "job name: worker or ps")
flags.DEFINE_integer("task_index", 0,
"Worker task index, should be >= 0. task_index=0 is "
"the chief worker task the performs the variable "
"initialization")
flags.DEFINE_string("ps_hosts", "",
"Comma-separated list of hostname:port pairs")
flags.DEFINE_string("worker_hosts", "",
"Comma-separated list of hostname:port pairs")
# Training related flags
flags.DEFINE_string("data_dir", None,
"Directory where the mnist data is stored")
flags.DEFINE_string("train_dir", None,
"Directory for storing the checkpoints")
flags.DEFINE_integer("hidden1", 128,
"Number of units in the 1st hidden layer of the NN")
flags.DEFINE_integer("hidden2", 128,
"Number of units in the 2nd hidden layer of the NN")
flags.DEFINE_integer("batch_size", 100, "Training batch size")
flags.DEFINE_float("learning_rate", 0.01, "Learning rate")
FLAGS = flags.FLAGS
TRAIN_FILE = "train.tfrecords"
NUM_CLASSES = 10
IMAGE_SIZE = 28
IMAGE_PIXELS = IMAGE_SIZE * IMAGE_SIZE
def inference(images, hidden1_units, hidden2_units):
with tf.name_scope('hidden1'):
weights = tf.Variable(
tf.truncated_normal([IMAGE_PIXELS, hidden1_units],
stddev=1.0 / math.sqrt(float(IMAGE_PIXELS))),name='weights')
biases = tf.Variable(tf.zeros([hidden1_units]),name='biases')
hidden1 = tf.nn.relu(tf.matmul(images, weights) + biases)
with tf.name_scope('hidden2'):
weights = tf.Variable(
tf.truncated_normal([hidden1_units, hidden2_units],
stddev=1.0 / math.sqrt(float(hidden1_units))),
name='weights')
biases = tf.Variable(tf.zeros([hidden2_units]),
name='biases')
hidden2 = tf.nn.relu(tf.matmul(hidden1, weights) + biases)
with tf.name_scope('softmax_linear'):
weights = tf.Variable(
tf.truncated_normal([hidden2_units, NUM_CLASSES],
stddev=1.0 / math.sqrt(float(hidden2_units))),name='weights')
biases = tf.Variable(tf.zeros([NUM_CLASSES]),name='biases')
logits = tf.matmul(hidden2, weights) + biases
return logits
def lossFunction(logits, labels):
labels = tf.to_int64(labels)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
logits, labels, name='xentropy')
loss = tf.reduce_mean(cross_entropy, name='xentropy_mean')
return loss
def training(loss, learning_rate):
tf.summary.scalar(loss.op.name, loss)
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
global_step = tf.Variable(0, name='global_step', trainable=False)
train_op = optimizer.minimize(loss, global_step=global_step)
return train_op
def read_and_decode(filename_queue):
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
serialized_example,
# Defaults are not specified since both keys are required.
features={
'image_raw': tf.FixedLenFeature([], tf.string),
'label': tf.FixedLenFeature([], tf.int64),
})
# Convert from a scalar string tensor (whose single string has
# length mnist.IMAGE_PIXELS) to a uint8 tensor with shape
# [mnist.IMAGE_PIXELS].
image = tf.decode_raw(features['image_raw'], tf.uint8)
image.set_shape([IMAGE_PIXELS])
image = tf.cast(image, tf.float32) * (1. / 255) - 0.5
# Convert label from a scalar uint8 tensor to an int32 scalar.
label = tf.cast(features['label'], tf.int32)
return image, label
def inputs(batch_size):
"""Reads input data.
Args:
batch_size: Number of examples per returned batch.
Returns:
A tuple (images, labels), where:
* images is a float tensor with shape [batch_size, mnist.IMAGE_PIXELS]
in the range [-0.5, 0.5].
* labels is an int32 tensor with shape [batch_size] with the true label,
a number in the range [0, mnist.NUM_CLASSES).
"""
filename = os.path.join(FLAGS.data_dir, TRAIN_FILE)
with tf.name_scope('input'):
filename_queue = tf.train.string_input_producer([filename])
# Even when reading in multiple threads, share the filename
# queue.
image, label = read_and_decode(filename_queue)
# Shuffle the examples and collect them into batch_size batches.
# (Internally uses a RandomShuffleQueue.)
# We run this in two threads to avoid being a bottleneck.
images, sparse_labels = tf.train.shuffle_batch(
[image, label], batch_size=batch_size, num_threads=2,
capacity=1000 + 3 * batch_size,
# Ensures a minimum amount of shuffling of examples.
min_after_dequeue=1000)
return images, sparse_labels
def device_and_target():
# If FLAGS.job_name is not set, we're running single-machine TensorFlow.
# Don't set a device.
if FLAGS.job_name is None:
raise ValueError("Must specify an explicit `job_name`")
# Otherwise we're running distributed TensorFlow.
print("Running distributed training")
if FLAGS.task_index is None or FLAGS.task_index == "":
raise ValueError("Must specify an explicit `task_index`")
if FLAGS.ps_hosts is None or FLAGS.ps_hosts == "":
raise ValueError("Must specify an explicit `ps_hosts`")
if FLAGS.worker_hosts is None or FLAGS.worker_hosts == "":
raise ValueError("Must specify an explicit `worker_hosts`")
cluster_spec = tf.train.ClusterSpec({
"ps": FLAGS.ps_hosts.split(","),
"worker": FLAGS.worker_hosts.split(","),
})
server = tf.train.Server(
cluster_spec, job_name=FLAGS.job_name, task_index=FLAGS.task_index)
return (
cluster_spec,
server,
)
def main(unused_argv):
if FLAGS.data_dir is None or FLAGS.data_dir == "":
raise ValueError("Must specify an explicit `data_dir`")
if FLAGS.train_dir is None or FLAGS.train_dir == "":
raise ValueError("Must specify an explicit `train_dir`")
cluster_spec, server = device_and_target()
if FLAGS.job_name == "ps":
server.join()
elif FLAGS.job_name == "worker":
with tf.device(tf.train.replica_device_setter(worker_device = "/job:worker/task:{}".format(FLAGS.task_index), cluster=cluster_spec)):
images, labels = inputs(FLAGS.batch_size)
logits = inference(images, FLAGS.hidden1, FLAGS.hidden2)
loss = lossFunction(logits, labels)
train_op = training(loss, FLAGS.learning_rate)
with tf.train.MonitoredTrainingSession(
master=server.target,
is_chief=(FLAGS.task_index == 0),
checkpoint_dir=FLAGS.train_dir) as sess:
while not sess.should_stop():
sess.run(train_op)
if __name__ == "__main__":
tf.app.run()四、分散式模型的啟動
首先關閉防火牆
sudo iptable –F然後在不同的機器上面啟動服務
#在246.1機器上面執行引數伺服器,命令:
CLASSPATH=$($HADOOP_HDFS_HOME/bin/hadoop classpath --glob) python /home/bdusr01/tine/Distributed_Tensorflow_MNIST_Model_Used_NN_Read_TFRecords_On_HDFS_Support_Kerberos.py --ps_hosts=10.142.246.1:1120 --worker_hosts=10.142.78.41:1121,10.142.78.45:1122 --data_dir=hdfs://default/user/bdusr01/asy/MNIST_data --train_dir=/home/bdusr01/checkpoint/ --job_name=ps --task_index=0
#在78.41機器上面執行worker0,命令:
CLASSPATH=$($HADOOP_HDFS_HOME/bin/hadoop classpath --glob) python /home/bdusr01/tine/Distributed_Tensorflow_MNIST_Model_Used_NN_Read_TFRecords_On_HDFS_Support_Kerberos.py --ps_hosts=10.142.246.1:1120 --worker_hosts=10.142.78.41:1121,10.142.78.45:1122 --data_dir=hdfs://default/user/bdusr01/asy/MNIST_data --train_dir=/home/bdusr01/checkpoint/ --job_name=worker --task_index=0
#在78.45機器上面執行worker1,命令:
CLASSPATH=$($HADOOP_HDFS_HOME/bin/hadoop classpath --glob) python /home/bdusr01/tine/Distributed_Tensorflow_MNIST_Model_Used_NN_Read_TFRecords_On_HDFS_Support_Kerberos.py--ps_hosts=10.142.246.1:1120 --worker_hosts=10.142.78.41:1121,10.142.78.45:1122 --data_dir=hdfs://default/user/bdusr01/asy/MNIST_data --train_dir=/home/bdusr01/checkpoint/ --job_name=worker --task_index=1
#在78.41機器上面執行監控,命令:
tensorboard --logdir=/home/bdusr01/checkpoint/五、模型監控
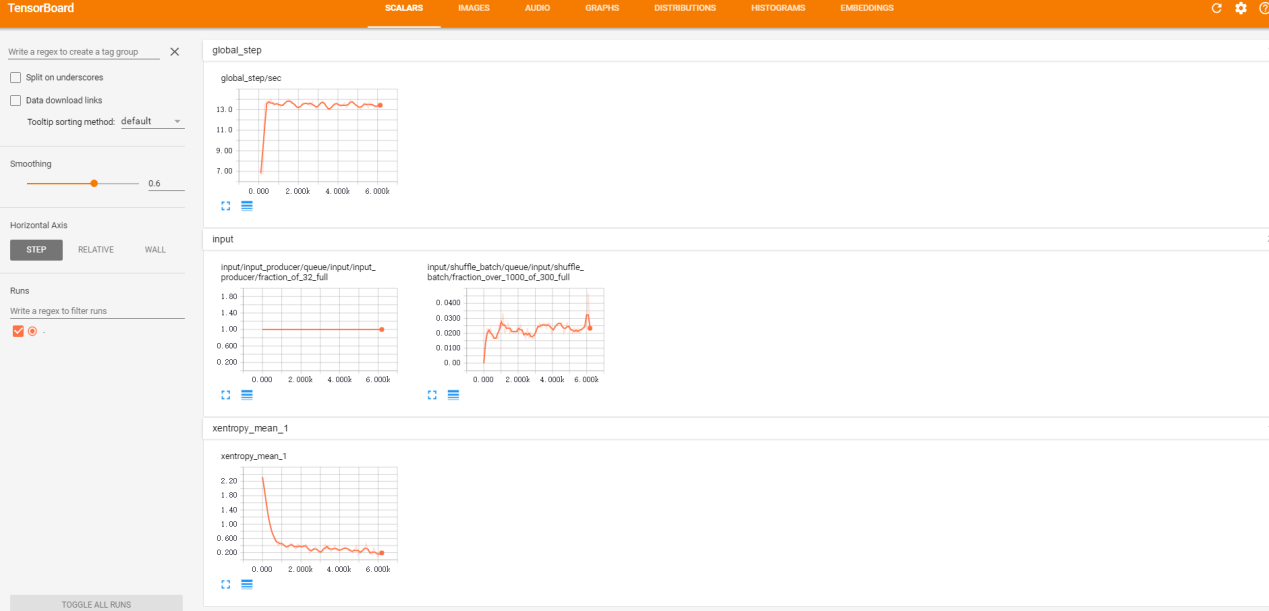
我們在剛剛的41機器上面啟動了TensorBoard,可以通過地址http://10.142.78.41:6006/進行模型的監控。模型訓練過程中引數可以動態的進行觀測,示例如下:
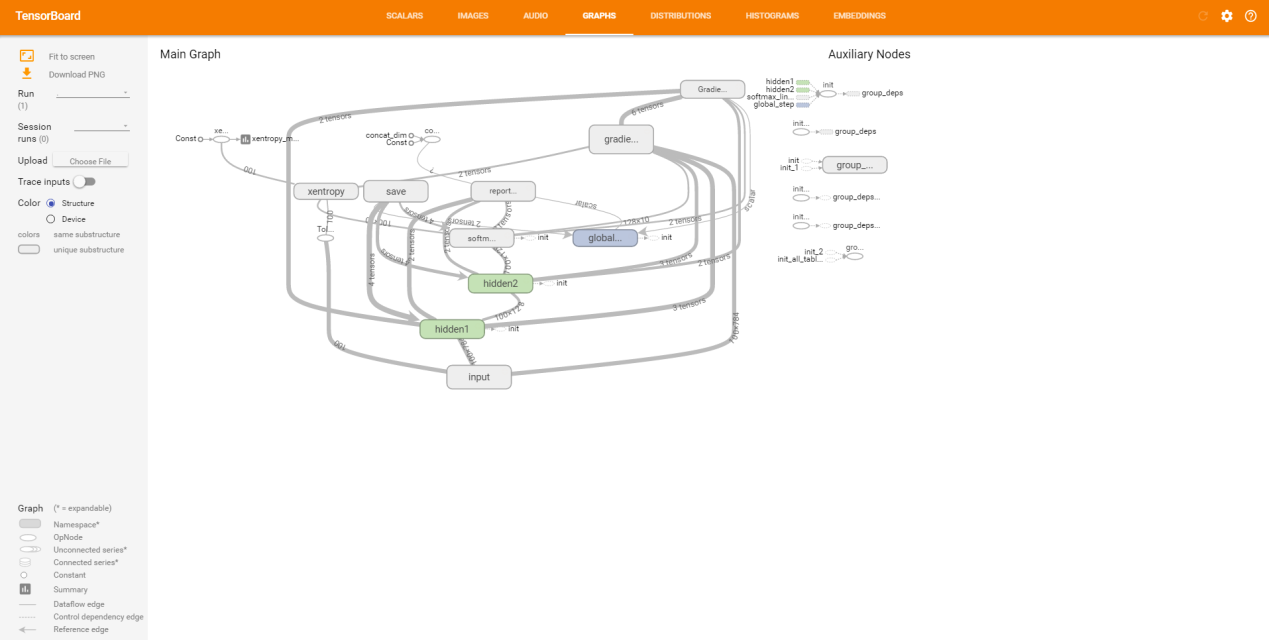
模型的網路結構可以詳細的參看每個細節,示例如下:
當我們利用分散式的Tensorflow對大資料進行訓練完成後,可以利用Bazel構建一個靈活高可用的服務–TensorFlow Serving,能夠很方便的將深度學習生產化,解決了模型無法提供服務的弊端。到此為止,本文就將自己專案中的一個基礎模組的示例介紹完了,本專案更有含金量的是模型建立、工程開發、業務邏輯部分,如有機會再進行更詳細的交流。