
增強學習在無人駕駛中的應用
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
圖1 增強學習和環境互動的框圖
增強學習存在著很多傳統機器學習所不具備的挑戰。首先,因為在增強學習中沒有確定在每一時刻應該採取哪個行為的資訊,增強學習演算法必須通過探索各種可能的行為才能判斷出最優的行為。如何有效地在可能行為數量較多的情況下有效探索,是增強學習中最重要的問題之一。其次,在增強學習中一個行為不僅可能會影響當前時刻的獎勵,而且還可能會影響之後所有時刻的獎勵。在最壞的情況下,一個好行為不會在當前時刻獲得獎勵,而會在很多步都執行正確後才能得到獎勵。在這種情況下,增強學習需要判斷出獎勵和很多步之前的行為有關非常有難度。
雖然增強學習存在很多挑戰,它也能夠解決很多傳統的機器學習不能解決的問題。首先,由於不需要標註的過程, 增強學習可以更有效地解決環境中所存在著的特殊情況。比如,無人車環境中可能會出現行人和動物亂穿馬路的特殊情況。只要我們的模擬器能夠模擬出這些特殊情況,增強學習就可以學習到怎麼在這些特殊情況中做出正確的行為。其次,增強學習可以把整個系統作為一個整體的系統,從而對其中的一些模組更加魯棒。例如,自動駕駛中的感知模組不可能做到完全可靠。前一段時間,Tesla無人駕駛的事故就是因為在強光環境中感知模組失效導致的。增強學習可以做到,即使在某些模組失效的情況下也能做出穩妥的行為。最後,增強學習可以比較容易學習到一系列行為。自動駕駛中需要執行一系列正確的行為才能成功的駕駛。如果只有標註資料,學習到的模型如果每個時刻偏移了一點,到最後可能就會偏移非常多,產生毀滅性的後果。而增強學習能夠學會自動修正偏移。
綜上所述,增強學習在自動駕駛中有廣闊的前景。本文會介紹增強學習的常用演算法以及其在自動駕駛中的應用。希望能夠激發這個領域的探索性工作。
增強學習演算法
增強學習中的每個時刻t∈{0,1,2,…}中,我們的演算法和環境通過執行行為at進行互動,可以得到觀測st和獎勵rt。一般情況中,我們假設環境是存在馬爾科夫性質的,即環境的變化完全可以通過狀態轉移概率Pass′=Pr{st+1=s′|st=s,at=a}刻畫出來。也就是說,環境的下一時刻觀測只和當前時刻的觀測和行為有關,和之前所有時刻的觀測和行為都沒有關係。而環境在t+1時刻返回的獎勵在當前狀態和行為確定下的期望可以表示為:Ras=E{rt+1|st=s,at=a}. 增強學習演算法在每一個時刻執行行為的策略可以通過概率π(s,a,θ)=Pr{at=a|st=s;θ}來表示。其中θ是需要學習的策略引數。我們需要學習到最優的增強學習策略,也就是學習到能夠取得最高獎勵的策略。
其中γ是增強學習中的折扣係數,用來表示在之後時刻得到的獎勵折扣。同樣的獎勵,獲得的時刻越早,增強學習系統所感受到的獎勵越高。
同時,我們可以按照如下方式定義Q函式。Q函式Qpi(s,a)表示的是在狀態為s,執行行為a之後的時刻都使用策略π選擇行為能夠得到的獎勵。我們能夠學習到準確的Q函式,那麼使Q函式最高的行為就是最優行為。
增強學習的目的,就是在給定的任意環境,通過對環境進行探索學習到最佳的策略函式π最大化rho(π)。下面的章節中我們會簡單介紹常用的增強學習演算法。包括REINFORCE演算法和Deep Q-learning演算法。
REINFORCE
REINFORCE是最簡單的reinforcement learning演算法。其基本思想是通過在環境裡面執行當前的策略直到一個回合結束(比如遊戲結束),根據得到的獎勵可以計算出當前策略的梯度。我們可以用這個梯度更新當前的策略得到新策略。在下面的回合,我們再用新的策略重複這個過程,一直到計算出的梯度足夠小為止。最後得到的策略就是最優策略。
假設我們當前的策略概率是πθ(x)=Pr{at=a|st=s;θ} (θ是策略引數)。每個回合,演算法實際執行的行為at是按照概率π(x)取樣所得到的。演算法在當前回合時刻t獲得的獎勵用rt表示。那麼,策略梯度可以通過以下的公式計算。
其中π(at|st;θ)是策略在觀測到st時選擇at的概率。Rt=∑Tt′=tγt′-trt′是演算法在採取了當前策略之後所獲得的總的折扣後的獎勵。為了減少預測出梯度的方差。我們一般會使用(Rt-bt)來代替Rt。bt一般等於Eπ[Rt],也就是當前t時刻的環境下使用策略π之後能獲得的折扣後獎勵的期望。
計算出方差之後,我們可以使用θ=θ+▽θρ(π)更新引數得到新的策略。
REINFORCE的核心思想是通過從環境中獲得的獎勵判斷執行行為的好壞。如果一個行為執行之後獲得的獎勵比較高,那麼算出的梯度也會比較高,這樣在更新後的策略中該行為被取樣到的概率也會比較高。反之,對於執行之後獲得獎勵比較低的行為,因為計算出的梯度低,更新後的策略中該行為被取樣到的概率也會比較低。通過在這個環境中反覆執行各種行為,REIFORCE可以大致準確地估計出各個行為的正確梯度,從而對策略中各個行為的取樣概率做出相應調整。
作為最簡單的取樣演算法,REINFORCE得到了廣泛應用,例如學習視覺的注意力機制和學習序列模型的預測策略都用到了REINFORCE演算法。事實證明,在模型相對簡單,環境隨機性不強的環境下,REINFORCE演算法可以達到很好的效果。
但是,REINFORCE演算法也存在著它的問題。首先,REINFORCE演算法中,執行了一個行為之後的所有獎勵都被認為是因為這個行為產生的,這顯然不合理。雖然在執行了策略足夠多的次數然後對計算出的梯度進行平均之後,REINFORCE以很大概率計算出正確的梯度。但是在實際實現中,處於效率考慮,同一個策略在更新之前不可能在環境中執行太多次。在這種情況下,REINFORCE計算出的梯度有可能會有比較大的誤差。其次,REINFROCE演算法有可能會收斂到一個區域性最優點。如果我們已經學到了一個策略,這個策略中大部分的行為都以近似1的概率取樣到。那麼,即使這個策略不是最優的,REINFORCE演算法也很難學習到如何改進這個策略。因為我們完全沒有執行其他取樣概率為0的行為,無法知道這些行為的好壞。最後,REINFORCE演算法之後在環境存在回合的概念的時候才能夠使用。如果不存在環境的概念,REINFORCE演算法也無法使用。
最近,DeepMind提出了使用Deep Q-learning演算法學習策略,克服了REINFORCE演算法的缺點,在Atari遊戲學習這樣的複雜的任務中取得了令人驚喜的效果。
Deep Q-learning
Deep Q-learning是一種基於Q函式的增強學習演算法。該演算法對於複雜的每步行為之間存在較強的相關性環境有很好的效果。Deep Q-learning學習演算法的基礎是Bellman公式。我們在前面的章節已經介紹了Q函式的定義,如下所示。
如果我們學習到了最優行為對應的Q函式Q*(s,a),那麼這個函式應該滿足下面的Bellman公式。
另外,如果學習到了最優行為對應的Q函式Q*(s,a),那麼我們在每一時刻得到了觀察st之後,選擇使得Q*(s,a)最高的行為做為執行的行為at。
我們可以用一個神經網路來計算Q函式,用Q(s,a;w)來表示。其中w是神經網路的引數。我們希望學習出來的Q函式滿足Bellman公式。因此可以定義下面的損失函式。這個函式的Bellman公式的L2誤差如下。
其中r是在s的觀測執行行為a後得到的獎勵,s′是執行行為a之後下一個時刻的觀測。這個公式的前半部分r+γmaxa′Q*(s′,a′,w)也被稱為目標函式。我們希望預測出的Q函式能夠和通過這個時刻得到的獎勵及下個時刻狀態得到的目標函式儘可能接近。通過這個損失函式,我們可以計算出如下梯度。
可以通過計算出的梯度,使用梯度下降演算法更新引數w。
使用深度神經網路來逼近Q函式存在很多問題。首先,在一個回合內採集到的各個時刻的資料是存在著相關性的。因此,如果我們使用了一個回合內的全部資料,那麼我們計算出的梯度是有偏的。其次,由於取出使Q函式最大的行為這個操作是離散的,即使Q函式變化很小,我們所得到的行為也可能差別很大。這個問題會導致訓練時策略出現震盪。最後,Q函式的動態範圍有可能會很大,並且我們很難預先知道Q函式的動態範圍。因為,我們對一個環境沒有足夠的瞭解的時候,很難計算出這個環境中可能得到的最大獎勵。這個問題會使Q-learning工程梯度可能會很大,導致訓練不穩定。
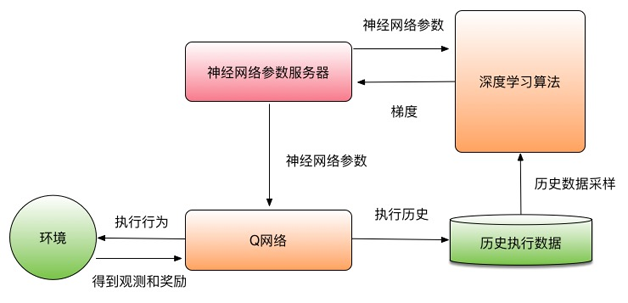
首先,Deep Q-learning演算法使用了經驗回放演算法。其基本思想是記住演算法在這個環境中執行的歷史資訊。這個過程和人類的學習過程類似。人類在學習執行行為的策略時,不會只通過當前執行的策略結果進行學習,而還會利用之前的歷史執行策略經驗進行學習。因此,經驗回放演算法將之前演算法在一個環境中的所有經驗都存放起來。在學習的時候,可以從經驗中取樣出一定數量的跳轉資訊(st,at,rt+1,st+1),也就是當處於環境,然後利用這些資訊計算出梯度學習模型。因為不同的跳轉資訊是從不同回合中取樣出來的,所以它們之間不存在強相關性。這個取樣過程還可以解決同一個回合中的各個時刻的資料相關性問題。
而且,Deep Q-learning演算法使用了目標Q網路來解決學習過程中的震盪問題。我們可以定義一個目標Q網路Q(s,a;w-)。這個網路的結構和用來執行的Q網路結構完全相同,唯一不同就是使用的引數w-。我們的目標函式可以通過目標Q網路計算。
目標Q網路引數在很長時間內保持不變,每當在Q網路學習了一定時間之後,可以Q網路的引數w替換目標Q網路的引數w-。這樣目標函式在很長的時間裡保持穩定。可以解決學習過程中的震盪問題。
最後,為了防止Q函式的值太大導致梯度不穩定。Deep Q-learning的演算法對獎勵設定了最大和最小值(一般設定為[-1, +1])。我們會把所有獎勵縮放到這個範圍。這樣演算法計算出的梯度更加穩定。
Q-learning演算法的框圖如圖2所示。
因為使用了深度神經網路來學習Q函式,Deep Q-learning算可以直接以影象作為輸入學習複雜的策略。其中一個例子是學習Atari遊戲。這是計算機遊戲的早期形式,一般影象比較粗糙,但要玩好需要對影象進行理解,並且執行復雜的策略,例如躲避,發射子彈,走迷宮等。一些Atari遊戲的例子如圖3所示,其中包含了一個簡單的賽車遊戲。
Deep Q-learning演算法在沒有任何額外知識的情況下,完全以影象和獲得的獎勵進行輸入。在大部分Atari遊戲中都大大超過了人類效能。這是深度學習或者增強學習出現前完全不可能完成的任務。Atari遊戲是第一個Deep Q-learning解決了用其他演算法都無法解決的問題,充分顯示了將深度學習和增強學習結合的優越性和前景。
使用增強學習幫助決策
現有的深度增強學習解決的問題中,我們執行的行為一般只對環境有短期影響。例如,在Atari賽車遊戲中,我們只需要控制賽車的方向和速度讓賽車沿著跑道行駛,並且躲避其他賽車就可以獲得最優的策略。但是對於更復雜決策的情景,我們無法只通過短期獎勵得到最優策略。一個典型的例子是走迷宮。在走迷宮這個任務中,判斷一個行為是否是最優無法從短期的獎勵來得到。只有當走到終點時,才能得到獎勵。在這種情況下,直接學習出正確的Q函式非常困難。我們只有把基於搜尋的和基於增強學習的演算法結合,才能有效解決這類問題。
基於搜尋演算法一般是通過搜尋樹來實現的。搜尋樹既可以解決一個玩家在環境中探索的問題(例如走迷宮),也可以解決多個玩家競爭的問題(例如圍棋)。我們以圍棋為例,講解搜尋樹的基本概念。圍棋遊戲有兩個玩家,分別由白子和黑子代表。圍棋棋盤中線的交叉點是可以下子的地方。兩個玩家分別在棋盤下白子和黑子。一旦一片白子或黑子被相反顏色的子包圍,那麼這片子就會被提掉,重新成為空白的區域。遊戲的最後,所有的空白區域都被佔領或是包圍。佔領和包圍區域比較大的一方獲勝。
在圍棋這個遊戲中,我們從環境中得到的觀測st是棋盤的狀態,也就是白子和黑子的分佈。我們執行的行為是所下白子或者黑子的位置。而我們最後得到的獎勵可以根據遊戲是否取勝得到。取勝的一方+1,失敗的一方-1。遊戲程序可以通過如下搜尋樹來表示:搜尋樹中的每個節點對應著一種棋盤狀態,每一條邊對應著一個可能的行為。在如圖4所示的搜尋樹中,黑棋先行,樹的根節點對應著棋盤的初始狀態s0。a1和a2對應著黑棋兩種可能的下子位置(實際的圍棋中,可能的行為遠比兩種多)。每個行為ai對應著一個新的棋盤的狀態si1。接下來該白棋走,白棋同樣有兩種走法b1和b2,對於每個棋盤的狀態si1,兩種不同的走法又會生成兩種不同狀態。如此往復,一直到遊戲結束,我們就可以在葉子節點中獲得遊戲結束時黑棋獲得的獎勵。我們可以通過這些獎勵獲得最佳的狀態。
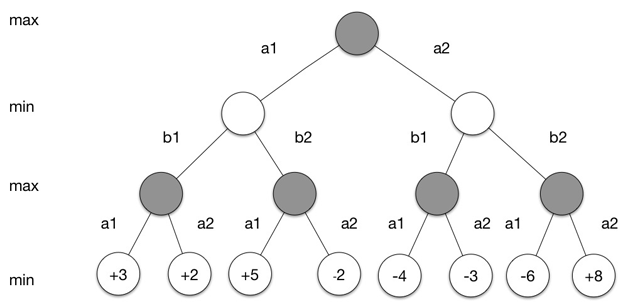
通過這個搜尋樹,如果給定黑棋和白棋的策略π=[π1,π2],我們可以定義黑棋的值函式為黑棋在雙方分別執行策略π1和π2時,最後黑棋能獲得獎勵的期望。
黑棋需要尋找的最優策略需要最優化最壞的情況下,黑棋所能得到的獎勵。我們定義這個值函式為最小最大值函式。黑棋的最優策略就是能夠達到這個值函式的策略π1。
如果我們能夠窮舉搜尋樹的每個節點,那麼我們可以很容易地用遞迴方式計算出最小最大值函式和黑棋的最優策略。但在實際的圍棋中,每一步黑棋和白棋可以採用的行為個數非常多,而搜尋樹的節點數目隨著樹的深度指數增長。因此,我們無法列舉所有節點計算出準確的最小最大值函式,而只能通過學習v(s;w)~v*(s)作為近似最小最大值函式。我們可以通過兩種方法使用這個近似函式。首先,我們可以使用這個近似函式確定搜尋的優先順序。對於一個節點,白棋或者黑棋可能有多種走法,我們應該優先搜尋產生最小最大值函式比較高節點的行為,因為在實際遊戲中,真實玩家一般會選擇這些相對比較好的行為。其次,我們可以使用這個近似函式來估計非葉子節點的最小最大值。如果這些節點的最小最大值非常低,那麼這些節點幾乎不可能對應著最優策略。我們再搜尋的時候也不用考慮這些節點。
因此主要問題是如何學習到近似最小最大值函式v(s;w)。我們可以使用兩個學習到的圍棋演算法自己和自己玩圍棋遊戲。然後通過增強學習演算法更新近似最小最大值函式的引數w。在玩完了一局遊戲之後,我們可以使用類似REINFORCE演算法的更新方式:
在這個式子中Gt表示的是在t時刻之後獲得的獎勵。因為在圍棋這個遊戲中,我們只在最後時刻獲得獎勵。所以Gt對應的是最後獲得的獎勵。我們也可以使用類似Q-learning的方式用TD誤差來更新引數。
因為圍棋這個遊戲中,我們只在最後時刻獲得獎勵。一般使用REINFORCE演算法的更新方式效果比較好。在學習出一個好的近似最小最大值函式之後,可以大大加快搜索效率。這和人學習圍棋的過程類似,人在學習圍棋的過程中,會對特定的棋行形成感覺,能一眼就判斷出棋行的好壞,而不用對棋的發展進行推理。這就是通過學習近似最小最大值函式加速搜尋的過程。
通過學習近似最小最大值函式,Google DeepMind在圍棋領域取得了突飛猛進。在今年三月進行的比賽中,AlphaGo以四比一戰勝了圍棋世界冠軍李世石。AlphaGo的核心演算法就是通過歷史棋局和自己對弈學習近似最小最大值函式。AlphaGo的成功充分的顯示了增強學習和搜尋結合在需要長期規劃問題上的潛力。不過,需要注意的是,現有將增強學習和搜尋結合的演算法只能用於確定性的環境中。確定性的環境中給定一個觀測和一個行為,下一個觀測是確定的,並且這個轉移函式是已知的。在環境非確定,並且轉移函式未知的情況下,如何把增強學習和搜尋結合還是增強學習領域中沒有解決的問題。
自動駕駛的決策介紹
自動駕駛的人工智慧包含了感知、決策和控制三個方面。感知指的是如何通過攝像頭和其他感測器輸入解析出周圍環境的資訊,例如有哪些障礙物,障礙物的速度和距離,道路的寬度和曲率等。這個部分是自動駕駛的基礎,是當前自動駕駛研究的重要方向,在前文我們已經有講解。控制是指當我們有了一個目標,例如右轉30度,如何通過調整汽車的機械引數達到這個目標。這個部分已經有相對比較成熟的演算法能夠解決,不在本文的討論範圍之內。本節,我們著重講解自動駕駛的決策部分。
自動駕駛的決策是指給定感知模組解析出的環境資訊如何控制汽車的行為來達到駕駛目標。例如,汽車加速、減速、左轉、右轉、換道、超車都是決策模組的輸出。決策模組不僅需要考慮到汽車的安全和舒適性,保證儘快到達目標地點,還需要在旁邊車輛惡意駕駛的情況下保證乘客安全。因此,決策模組一方面需要對行車計劃進行長期規劃,另一方面還需要對周圍車輛和行人的行為進行預測。而且,自動駕駛中的決策模組對安全和可靠性有著嚴格要求。現有自動駕駛的決策模組一般根據規則構建,雖然可以應付大部分駕駛情況,對於駕駛中可能出現的各種突發情況,基於規則的決策系統不可能列舉到所有突發情況。我們需要一種自適應系統來應對駕駛環境中出現的各種突發情況。
現有自動駕駛的決策系統大部分基於規則,該系統大部分可以用有限狀態機表示。例如,自動駕駛的高層行為可以分為向左換道、向右換道、跟隨、緊急停車。決策系統根據目標可以決定執行高層行為。根據需要執行的高層行為,決策系統可以用相應的規則生成出底層行為。基於規則決策系統的主要缺點是缺乏靈活性。對於所有的突發情況,都需要寫一個決策。這種方式很難對所有的突發系統面面俱到。
自動駕駛模擬器
自動駕駛的決策過程中,模擬器起著非常重要的作用。決策模擬器負責對環境中常見的場景進行模擬,例如車道情況、路面情況、障礙物分佈和行為、天氣等。同時還可以將真實場景中採集到的資料進行回放。決策模擬器的介面和真車的介面保持一致,這樣可以保證在真車上使用的決策演算法可以直接在模擬器上執行。除了決策模擬器之外,自動駕駛的模擬器還包含了感知模擬器和控制模擬器,用來驗證感知和控制模組。這些模擬器不在本文的討論氛圍之內 (詳細請見CSDN《程式設計師》2016年8月《基於Spark與ROS的分散式無人駕駛模擬平臺》)。
自動駕駛模擬器的第一個重要功能是驗證。在迭代決策演算法的過程中,我們需要比較容易地衡量演算法效能。比如,需要確保新決策演算法在之前能夠正確執行和常見的場景都能夠安全執行。我們還需要根據新決策演算法對常見場景的安全性、快捷性、舒適性打分。我們不可能每次在更新演算法時都在實際場景中測試,這時有一個能可靠反映真實場景的無人駕駛模擬器是非常重要的。
模擬器的另一個重要的功能是進行增強學習。可以模擬出各種突發情況,然後增強學習演算法利用其在這些突發情況中獲得的獎勵,學習如何應對。這樣,只要能夠模擬出足夠的突發情況,增強學習演算法就可以學習到對應的處理方法,而不用每種突發情況都單獨寫規則處理。而且,模擬器也可以根據之前增強學習對於突發情況的處理結果,儘量產生出當前的增強學習演算法無法解決的突發,從而增強學習效率。
綜上所述,自動駕駛模擬器對決策模組的驗證和學習都有著至關重要的作用,是無人駕駛領域的核心技術。如何創建出能夠模擬出真實場景、覆蓋大部分突發情況、並且和真實的汽車介面相容的模擬器,是自動駕駛研發的難點之一。
增強學習在自動駕駛中的應用和展望
增強學習在自動駕駛中很有前景。我們在TORCS模擬器中使用增強學習進行了探索性的工作。TORCS是一個賽車模擬器。玩家的任務是超過其他AI車,以最快速度達到終點。雖然TORCS中的任務和真實的自動駕駛任務還有很大區別。但其中演算法的效能非常容易評估。TORCS模擬器如圖5所示。增強學習演算法一般可以以前方和後方看到的影象作為輸入,也可以環境狀態作為輸入(例如速度,離賽道邊緣的距離和跟其他車的距離)。

我們這裡使用了環境狀態作為輸入。使用Deep Q-learning做為學習演算法學習。環境獎勵定義為在單位時刻車輛沿跑道的前進距離。另外,如果車出了跑道或者和其他的車輛相撞,會得到額外懲罰。環境狀態包括車輛的速度、加速度、離跑道的左右邊緣的距離,以及跑道的切線夾角,在各個方向上最近的車的距離等等。車的行為包括向上換擋、向下換擋、加速、減速、向左打方向盤、向右打方向盤等等。
與普通的Deep Q-learning相比,我們做了以下的改進。首先,使用了多步TD演算法進行更新。多步TD演算法能比單步演算法每次學習時看到更多的執行部數,因此也能更快地收斂。其次,我們使用了Actor-Critic的架構。它把演算法的策略函式和值函式分別使用兩個網路表示。這樣的表示有兩個優點:1. 策略函式可以使用監督學習的方式進行初始化學習。2. 在環境比較複雜的時候,學習值函式非常的困難。把策略函式和值函式分開學習可以降低策略函式學習的難度。
使用了改進後的Deep Q-learning演算法,我們學習到的策略在TORCS中可以實現沿跑到行走,換道,超車等行為。基本達到了TORCS環境中的基本駕駛的需要。Google DeepMind直接使用影象作為輸入,也獲得了很好的效果,但訓練的過程要慢很多。
現有的增強學習演算法在自動駕駛模擬環境中獲得了很有希望的結果。但是可以看到,如果需要增強學習真正能夠在自動駕駛的場景下應用,還需要有很多改進。第一個改進方向是增強學習的自適應能力。現有的增強學習演算法在環境性質發生改變時,需要試錯很多次才能學習到正確的行為。而人在環境發生改變的情況下,只需要很少次試錯就可以學習到正確的行為。如何只用非常少量樣本學習到正確的行為是增強學習能夠實用的重要條件。
第二個重要的改進方向是模型的可解釋性。現在增強學習中的策略函式和值函式都是由深度神經網路表示的,其可解釋性比較差,在實際的使用中出了問題,很難找到原因,也比較難以排查。在自動駕駛這種人命關天的任務中,無法找到原因是完全無法接受的。
第三個重要的改進方向是推理和想象能力。人在學習的過程中很多時候需要有一定的推理和想象能力。比如,在駕駛時,不用親身嘗試,也知道危險的行為會帶來毀滅性的後果。 這是因為人類對這個世界有一個足夠好的模型來推理和想象做出相應行為可能會發生的後果。這種能力不僅對於存在危險行為的環境下下非常重要,在安全的環境中也可以大大加快收斂速度。
只有在這些方向做出了實質突破,增強學習才能真正使用到自動駕駛或是機器人這種重要的任務場景中。希望更多有志之士能投身這項研究,為人工智慧的發展貢獻出自己的力量。
作者簡介
- 王江,百度研究院矽谷深度學習實驗室資深科學家。在復旦大學獲得學士和碩士學位,美國西北大學獲得博士學位。曾在微軟亞洲研究院、Redmond研究院、Google研究院、Google影象搜尋組實習。
- 吳雙,原百度研究院矽谷人工智慧實驗室資深研究科學家,原百度美國研發中心高階架構師。美國南加州大學物理博士,加州大學洛杉磯分校博士後。研究方向包括計算機和生物視覺,網際網路廣告演算法和語音識別。
- 劉少山,PerceptIn聯合創始人。加州大學歐文分校計算機博士,研究方向智慧感知計算、系統軟體、體系結構與異構計算。現在PerceptIn主要專注於SLAM技術及其在智慧硬體上的實現與優化。
給我老師的人工智慧教程打call!http://blog.csdn.net/jiangjunshow
