
深度強化學習及其在自動駕駛中的應用: DRL&ADS系列之(2): 深度強化學習DQN原理
專欄系列文章規劃
上一篇文章《DRL&ADS系列之(1): 強化學習概述》已經講解了利用神經網路近似值函式的方法,即:
理論近似方法已經描述了,那麼具體的工作過程是怎樣實現的? 以及如何從端到端的過程,本文將講解Deep Q Network(DQN, 而這正是由DeepMind於2013年和2015年分別提出的兩篇論文《Playing Atari with Deep Reinforcement Learning》《Human-level Control through Deep Reinforcement Learning:Nature雜誌》
其中DeepMind在第一篇中第一次提出Deep Reinforcement Learning(DRL)這個名稱,並且提出DQN演算法,實現從視訊純影象輸入,完全通過Agent學習來玩Atari遊戲的成果。之後DeepMind在Nature上發表了改進版的DQN文章(Human-level …..), 這將深度學習與RL結合起來實現從Perception感知到Action動作的端到端的一種全新的學習演算法。簡單理解就是和人類一樣,輸入感知資訊比如眼睛看到的東西,然後通過大腦(深度神經網路),直接做出對應的行為(輸出動作)的學習過程。而後DeepMind提出了AlphaZero(完美的運用了DRL+Monte Calo Tree Search)取得了超過人類的水平!下文將詳細介紹DQN:
一、DQN演算法
DQN演算法是一種將Q_learning通過神經網路近似值函式的一種方法,在Atari 2600 遊戲中取得了超越人類水平玩家的成績,下文通過將逐步深入講解:
1.1、 Q_Learning演算法
是Watkins於1989年提出的一種無模型的強化學習技術。它能夠比較可用操作的預期效用(對於給定狀態),而不需要環境模型。同時它可以處理隨機過渡和獎勵問題,而無需進行調整。目前已經被證明,對於任何有限的MDP,Q學習最終會找到一個最優策略,即從當前狀態開始,所有連續步驟的總回報回報的期望值是最大值可以實現的。 學習開始之前,Q被初始化為一個可能的任意固定值(由程式設計師選擇)。然後在每個時間t, Agent選擇一個動作
其中 是學習率,為折扣因子,具體的實現過程見下圖虛擬碼:

首先初始化值函式矩陣,開始episode,然後選擇一個狀態state,同時智慧體根據自身貪婪策略,選擇action, 經過智慧體將動作運用後得到一個獎勵和,計算值函式,繼續迭代下一個流程。
1.1.1、執行過程中有兩個特點:異策略和時間差分
- 異策略:就是指行動策略和評估策略不是同一個策略,行動策略採用了貪心的-策略(第5行),而評估策略採用了貪心策略(第7行)!
- 時間差分:從值函式迭代公式(2)可以看出時間差分, 其中
為了在學習過程中得到最優策略Policy,通常估算每一個狀態下每一種選擇的價值Value有多大。且每一個時間片的和當前得到的Reward以及下一個時間片的有關。通過不斷的學習,最終形成一張矩陣來儲存狀態(state)和動作(action),表示為:
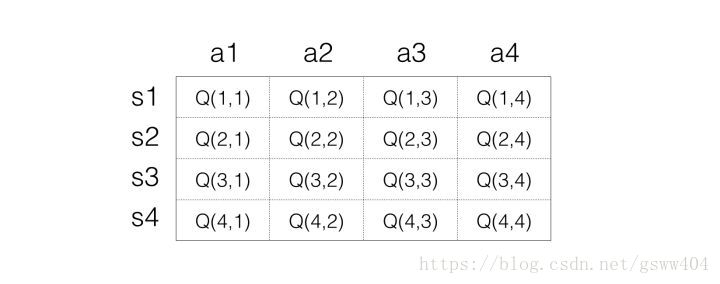
具體過程根據虛擬碼:首先初始化矩陣(所有都為0),第一次隨機並採用貪婪策略選擇action,假如選擇action2後選擇到了狀態2,(),此時得到獎勵1,則