
達觀杯比賽總結
目錄
比賽內容
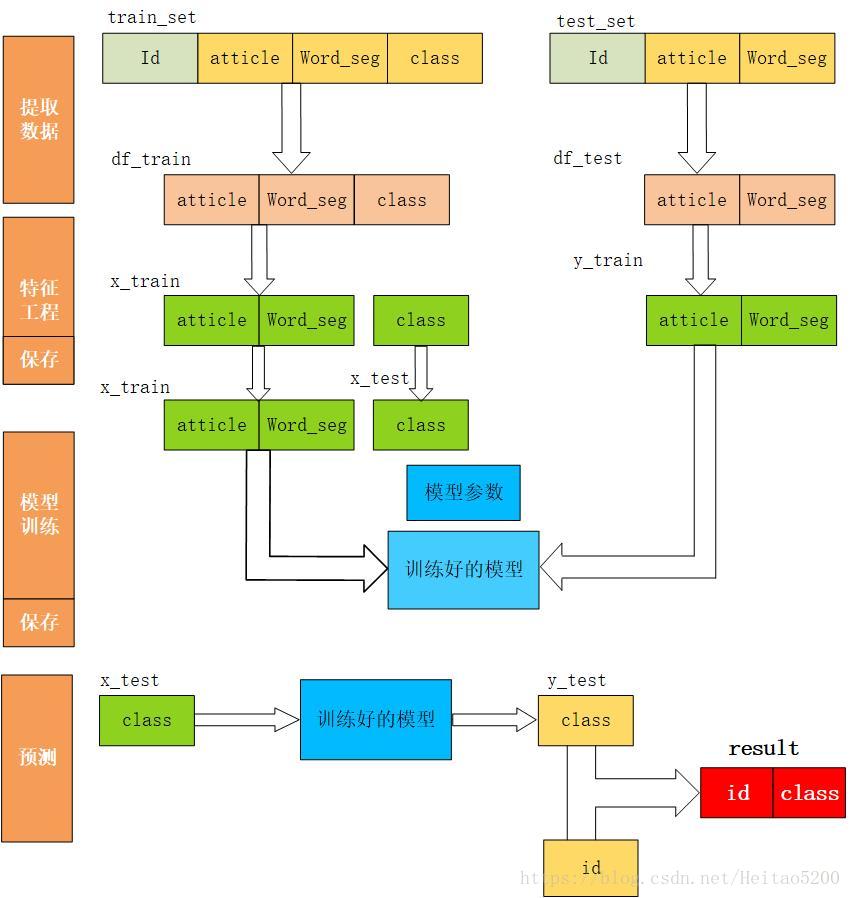
此次比賽,達觀資料提供了一批長文字資料和分類資訊,希望選手動用自己的智慧,結合當下最先進的NLP和人工智慧技術,深入分析文字內在結構和語義資訊,構建文字分類模型,實現精準分類。
評分規則
評分演算法 :binary-classification
評分標準 :採用各個品類F1指標的算術平均值,它是Precision 和 Recall 的調和平均數。
其中,
是表示第
個種類對應的Precision,
是表示第
個種類對應Recall。
資料集
每一行對應一篇文章。文章分別在“字”和“詞”的級別上做了脫敏處理。共有四列:
原始資料大小
訓練集:(102277, 4)
測試集:(102277, 3)
| 資料 | id | article | word_seg | class |
|---|---|---|---|---|
| train_set(訓練模型) | 文章的索引 | 文章正文在“字”級別上的表示,即字元相隔正文 | 在“詞”級別上的表示,即詞語相隔正文 | 這篇文章的標註 |
| test_set(用於測試) | 文章的索引 | 文章正文在“字”級別上的表示,即字元相隔正文 | 在“詞”級別上的表示,即詞語相隔正文 | 待預測 |
資料處理
首先,應該是分析資料得到其中的特徵,但比賽資料是經過脫敏後的資料,所以就沒分析。
問題1:
訓練資料與測試資料有2G多,在pycharm裡執行demo時一直報錯Process finished with exit code -1073740940 (0xC0000374),
解決辦法:
pandas包更新到最新版
pycharm中字尾為vmoptions的配置檔案裡Xms、Xmx的值調大
問題2: 讀取檔案報異常 field larger than field limit (131072)
解決辦法:使用如下程式碼
import sys,csv
maxInt = sys.maxsize
decrement = True
while decrement:
# decrease the maxInt value by factor 10
# as long as the OverflowError occurs.
decrement = False
try:
csv.field_size_limit(maxInt)
except OverflowError:
maxInt = int(maxInt/10)
decrement = True
問題3: 讀取檔案報異常2 OSError:Initializing from file failed
解決辦法:
讀取檔案時加上引數 engine=‘python’
將讀取檔案引擎改為python (預設情況下是c)
問題4: 原始資料的列名可能會出現亂碼
解決辦法:
df_train.columns = ['id','article','word_seg',"class"]
df_test.columns = ['id','article','word_seg']
特徵工程
直接提取了tf(詞頻)、hash(雜湊)、tfidf(term frequency–inverse document frequency)詞頻逆文字頻率、lsa(潛在語義特徵)、Doc2vec等特徵。還有一個特徵是LDA(線性判別式分析),由於要生成這個特徵的時間太長所以放棄了,即使把tf特徵篩選之後生成LDA特徵,時間也是不能接受。
Tfidf特徵代表的是詞的重要程度,直覺上這個特徵一定比tf特徵要好,所以最開始使用的這個特徵。之前常聽Word2vec。所以當時查了一下Word2vec 和Doc2vec的區別(忘了··)---------------------
word2vector
word2vec根據給定上下文,預測上下文的其他單詞。
doc2vector
Doc2Vec 或者叫做 paragraph2vec, sentence embeddings,是一種非監督式演算法,可以獲得 sentences/paragraphs/documents 的向量表達,是 word2vec 的拓展。學出來的向量可以通過計算距離來找 sentences/paragraphs/documents 之間的相似性,可以用於文字聚類,對於有標籤的資料,還可以用監督學習的方法進行文字分類,例如經典的情感分析問題。
hash
tfidf
TF-IDF可以有效評估一字詞對於一個檔案集或一個語料庫中的其中一份檔案的重要程度。因為它綜合表徵了該詞在文件中的重要程度和文件區分度。但在文字分類中單純使用TF-IDF來判斷一個特徵是否有區分度是不夠的。
特徵融合
由於生成多個特徵所以考慮了特徵融合。回頭看資料,資料中把文章分成“詞”表示和“字”表示,之前的實驗都是建立在“詞”表示文章的基礎上,所以接下來也把“字”表示文章加入實驗中。
| 特徵 | 模型 | 驗證集分數 | 耗時(min) | 比賽A榜得分 |
|---|---|---|---|---|
| lsa + vec2vec + tf.idf | SVM | 0.7789 | 173.31 | 0.775902 |
| tfidf + tfidf_article | SVM | 0.7800 | 25.19 | 0.7760 |
| tfidf_article + lsa +vec2vec +tf.idf | SVM | 0.7800 | 363.96 | 0.77***6 |
| Dec2vec+ tfidf | lgb | 0.7698 | 2456.92 | ~~ |
模型訓練
LR、 LG、 RF、SVM、 NB、 XGB、 KNN
調參
調整了SVM 的引數C 。C值越大,擬合非線性的能力越強。
網格搜尋,隨機搜尋,遺傳演算法
| C | 分數 |
|---|---|
| 1 | 0.7800 |
| 2 | 0.7798 |
| ~ | ~ |
| 10 | 0.7780 |
實驗
lsa特徵可以把tfidf特徵降維,可以找到詞在句子中的含義(具體作用有點忘了),因為不用詞在不同句子中的意思也不一樣。降維也可以提高執行速度。下面是lsa特徵在不同模型中的對比。
| 特徵 | 模型 | 分數 | 耗時(min) |
|---|---|---|---|
| lsa | SVM | 0.7227 | 0.88 |
| lsa | lr | 0.7038 | 1.85 |
| lsa | NB | 0.7227 | 52 |
| lsa | rf | 0.6428 | 0.74 |
| lsa | Knn | 0.7227 | 2.7 |
| lsa | xgboost | 0.7026 | 164.88 |
模型融合
概率檔案融合
分類結果融合
總結
實驗很耗時,最好做實驗之前有個良好的規劃,多問為什麼要做這個實驗?接下來要怎麼實驗?並對實驗的結果有序進行記錄。
不熟練理論基礎,有關NLP的知識都是遇到不懂的現查現用,導致很多知識記得不牢固,過段時間就忘記了。
接下來會完善上面不會的知識,弄懂程式碼背後的理論依據才是正確的道路。
展望一下未來的實驗,可能會先學一下多種模型融合,在Top10的PPT展示中幾乎都是多種深度學習和機器學習的模型融合,這可能是未來的一個方向。