
CNN網路優化學習總結——從MobileNet到ShuffleNet
CNN網路優化學習總結——從MobileNet到ShuffleNet
摘要
最近出了一篇曠視科技的孫劍團隊出了一篇關於利用Channel Shuffle實現的卷積網路優化——ShuffleNet。我關注了一下,原理相當簡單。它只是為了解決分組卷積時,不同feature maps分組之間的channels資訊互動問題,而提出Channel Shuffle操作為不同分組提供channels資訊的通訊的渠道。然而,當我讀到ShuffleNet Unit和Network Architecture的章節,考慮如何復現作者的實驗網路時,總感覺看透這個網路的實現,尤其是我驗算Table 1的結果時,總出現各種不對。因此我將作者引用的最近幾個比較火的網路優化結構(MobileNet,Xception,ResNeXt)學習了一下,終於在ResNeXt的引導下,把作者的整個實現搞清楚了。順帶著,我也把這項技術的發展情況屢了一下,產生了一些個人看法,就寫下這篇學習筆記。
關鍵詞
MobileNet,Xception,ResNeXt,ShuffleNet, MobileID
前言
自從2016年3月,谷歌用一場圍棋比賽把人工智慧(AI, Artificial Intelligence)正式推上了風口。深度學習突然間成為了整個IT行業的必備知識,不掌握也需要去了解。然而,在2014年我剛畢業的時候,這項技術並沒有現在那麼火。當時概念大家都還是比較模糊,我也只是在實習聽報告時,聽邵嶺博士提了一下,卻沒想到現在已經成為模式識別界的一枚巨星。儘管我後悔當時沒在這塊狠下功夫,但慶幸還能趕上末班船的站票。
CNN的提出其實很早,在1985年Hinton就提出了BP(反向傳播演算法),1998年LeCun就基於這項工作發表了LeNet用於解決手寫郵政編碼的識別問題。之後這項技術很少人去接觸,有觀點認為當時並沒有資源能承擔CNN的計算消耗。而它的轉折點卻是十多年後,在ImageNet比賽中,Alex在Nvidia的兩GPU上跑他設計的AlexNet架構,成功在眾人面前秀了一把CNN的平行計算操作並一舉奪冠,吸引了少量學者眼球。兩年過去,VGG和GoogLeNet在ImageNet上展開冠軍爭奪戰,標誌著深度學習正式起跑,業界開始關注並嘗試利用CNN解決一些過去的難題,比如目標跟蹤,目標檢測,人臉識別等,它這些領域也得到了不少突破。
然而,CNN的這些突破大多都是在計算代價巨大的條件下產生的,比方說令人目瞪狗呆的千層網路—ResNet。其實這並不利於深度學習在消費類產業的推廣,畢竟消費類產品很多是嵌入式的終端產品,而且嵌入式晶片的計算效能並不很強。即使我們考慮雲端計算,也需要消耗大量的頻寬資源和計算資源。因此,CNN的優化已成為深度學習產品能否在消費市場落腳生根的一個重要課題之一。所以,有不少學者著手研究CNN的網路優化,如韓鬆的SqueezeNet,Deep Compression,LeCun的SVD,Google的MobileNet以及這個孫劍的ShuffleNet等。
其實,網路壓縮優化的方法有兩個發展方向,一個是遷移學習,另一個是網路稀疏。遷移學習是指一種學習對另一種學習的影響,好比我們常說的舉一反三行為,以減少模型對資料量的依賴。不過,它也可以通過知識蒸餾實現大模型到小模型的遷移,這方面的工作有港中文湯曉鷗組的
MobileNet
MobileNet的主要工作是用depthwise sparable convolutions替代過去的standard convolutions來解決卷積網路的計算效率和引數量的問題。它預設一個假設,就是常規卷積核在feature maps的channels維度對映中,存在一種類似線性組合的分解特性。我們用K表示一個常規卷積核,則
K=M⋅Λ(b)(1)(1)K=M⋅Λ(b) 用一些數學方法進行如SVD分解的操作,進一步分解這個矩陣,或者是做一些矩陣低秩化的操作。我覺著這些思路可以使得網路結構的壓縮調整,有一定的自適應能力。MobileNet的Sparable Convolutions結構,除了上面提到的核分解壓縮引數量,減少計算量的優點以外,它還有另一個很好的亮點就是,這種分離結構對現在絕大多數移動終端的CPU指令加速硬體,是非常友善的。這也是現在移動端的深度學習平臺都必須要支援MobileNet(可分離卷積操作)的重要原因。
我大致分析一下這個點,我們先要了解SIMD硬體加速指令的概念。百度百科的概述是,“SIMD全稱Single Instruction Multiple Data,單指令多資料流,能夠複製多個運算元,並把它們打包在大型暫存器的一組指令集”,它的硬體是一個大型暫存器,我原來晶片公司的SIMD向量暫存器是128位,也就是一條指令譯碼後幾個執行部件同時訪問記憶體,一次性獲得128位運算元進行運算,比如它能在一個cycle內完成16個8bit型別(128=16×8128=16×8)運算元加法運算。現在大部分ARM的移動終端產品都一套NEON指令集,這是基於ARM的128\256位SIMD暫存器整合的,最近它們還開源了名為ARM ComputeLirary的深度學習計算平臺,裡面的各種運算元大量使用NEON指令和OpenCL庫。這似乎意味著,影象處理這種資料密集型運算很適合利用SIMD指令加速來得到很高的效率,然而對於卷積神經網路而言結果並不那麼理想。問題的主要原因在於讀取記憶體,樸素的卷積運算是需要跨行取數的。
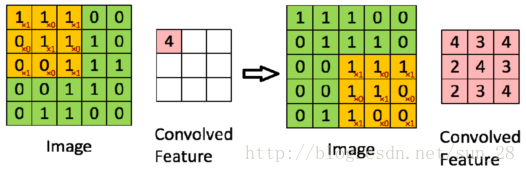
如上圖所示,若我想得到Convolved Feature中的4,我需要從Image那裡把黃色部分的[1,1,1,0,1,1,0,0,1]取出,並與卷積核[1,0,1,0,1,0,1,0,1]做內積(inner product)才能的到結果4。而Image的儲存方式大多是行連續儲存的,即Image=[1,1,1,0,0,0,1,1,…,0,0],然後我們就會發現當要取出[0,1,1]時,這個向量在記憶體上並不是緊接在[1,1,1]後面。我一條指令取出的8個數(假設16bit型別),其中就需要扔掉兩個,這個例子是Image比較小的情況,實踐中除前3個數以外,後面所有數都要丟棄。這種資料頻寬的利用率很低,並且很容易引發Cache Miss問題,畢竟CPU都會做Cache資料預取控制,不連續的記憶體訪問會影響這種控制的效果。CPU也會經常空閒,不會被有效利用。雖然也有不少人在卷積運算元實現上下功夫緩解這個問題,但是也無非只是時間與空間上的妥協,難以真正克服這一矛盾。
MobileNet的可分離卷積結構對這個矛盾很有效果。

上圖右邊是一個可分離卷積模組,左邊是常規卷積模組。如果它們的Input Channels數是nn Conv在實現當中僅是一個數乘向量運算,這相當適合SIMD的大資料訪存機制,使得頻寬和CPU能被有效利用。
簡言之,正因為MobileNet的可分離卷積模組在壓縮引數同時還壓縮了計算量,還能充分發揮現代CPU計算能力與資料讀取效率,再加上這些優化還不影響準確率,所以它被移動終端領域廣泛應用。從下面的資料對比,我們可以看到引數和準確率差不多的情況下,MobileNet的計算量遠小於SqueezeNet。而且SqueezeNet的Fire module實際上只是bottle neck module的變形與InceptionV1模組區別不大,只是少做了幾種尺度的卷積而已。

Xception
Xception的主要工作是解釋常規卷積(regular convolution
)如何從Inception模組過渡到可分離卷積(depthwise separable convolution)。它認為Inception模組背後有一個基本假設,就是輸入通道間的相關性和空間相關性是可以退耦合的,即使不把它倆連線起來對映,也能達到很好的效果。它的提出背景是把一個卷積層看作三維空間的濾波器(2維平面空間+1維feature map通道),其中一個卷積核需要同時對通道間的相關性和空間相關性聯合做對映。
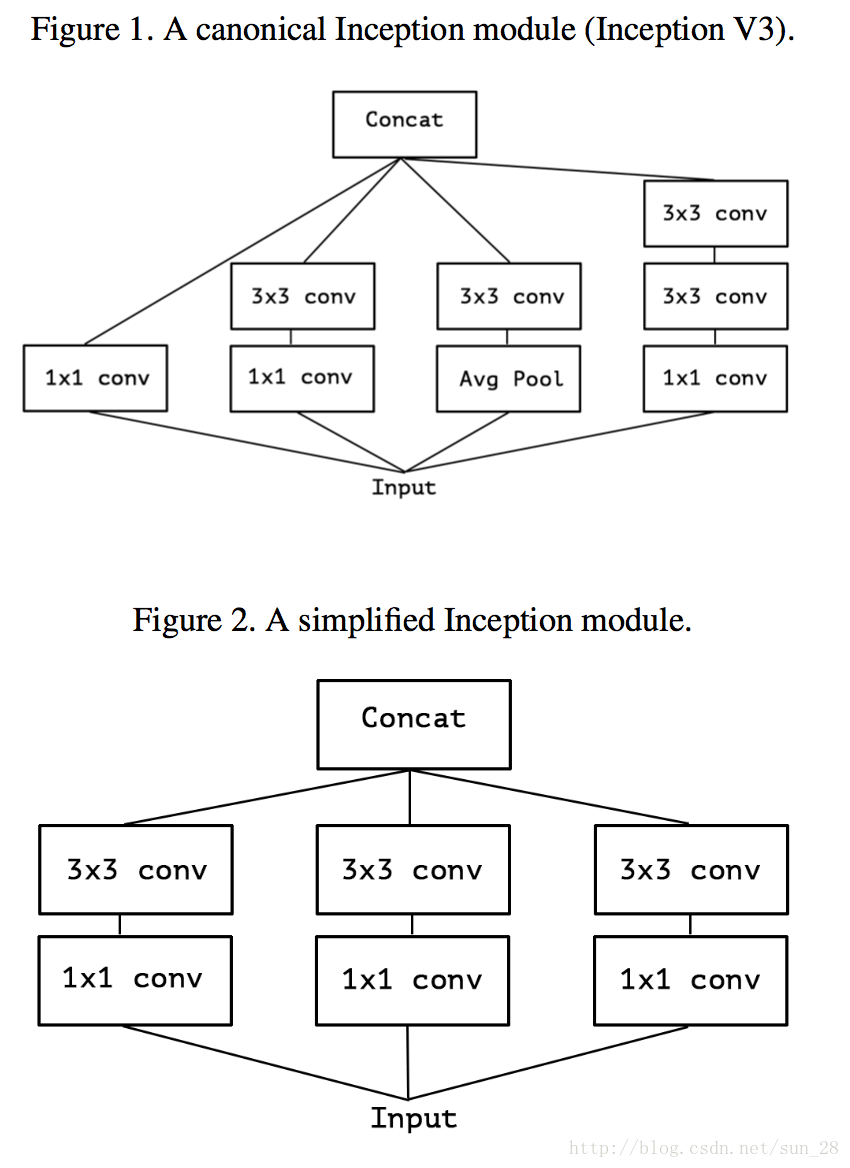
我們可以看到上圖Figure 1是典型的Inception模組,它先在通道相關性上利用一些 1×11×1卷積核的等效。
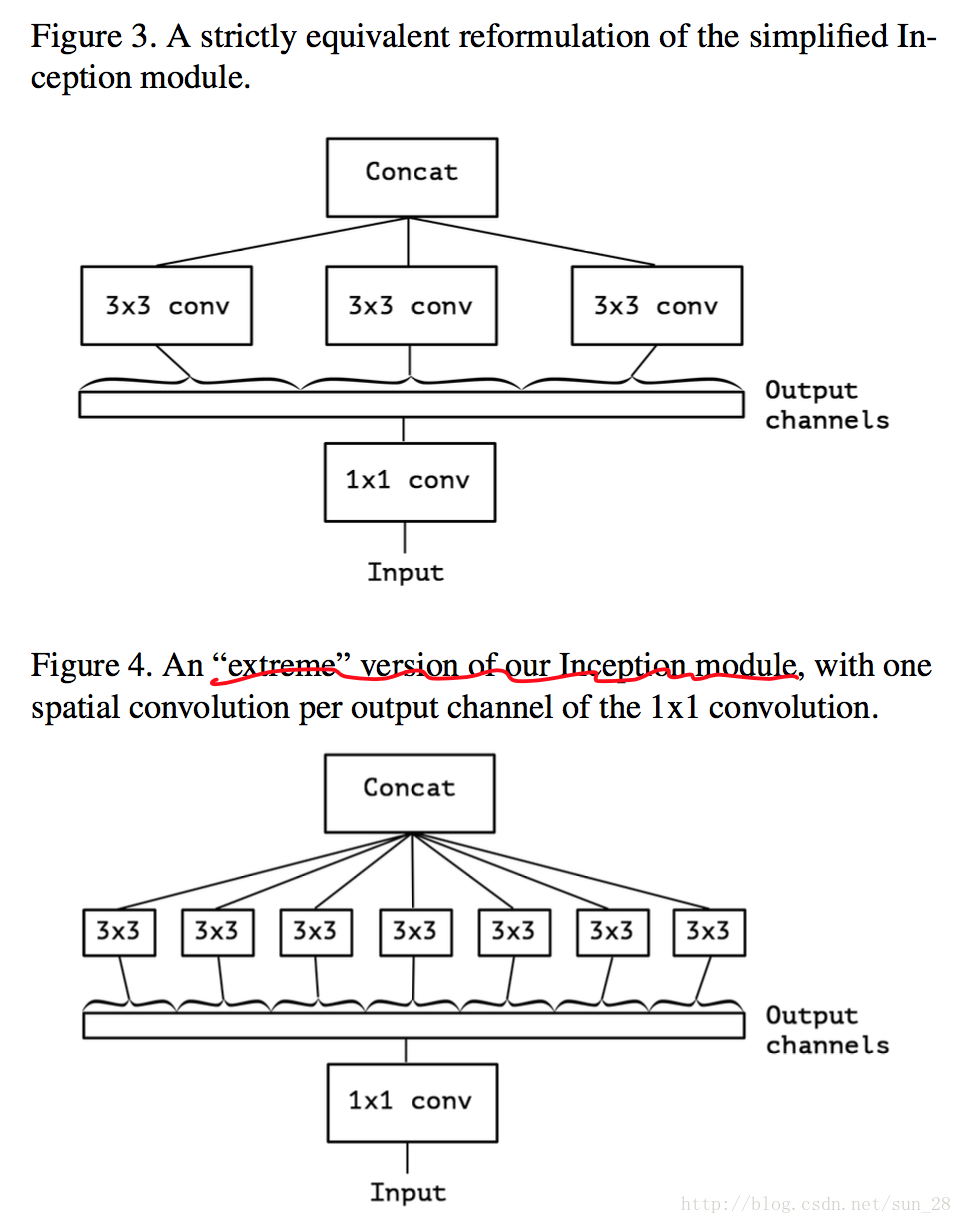
然後,考慮一下Inception簡化情形,將所有分支統一到最簡瓶頸模組的形式(圖Figure 2)。基於Inception的簡化情形,可以將所有1×11×1的通道相關對映,在分別對應每個channel的Feature Map做空間相關對映,可以等同於前面MobileNet章節所題到depthwise separable convolution,因此可分離卷積(MobileNet類網路)可以完全代替過去的常規卷積網路,Inception是這個替代過渡的重要橋樑。
可是,Xception發現這個“極限”Inception模組與可分離卷積模組有兩大區別:
1、可分離卷積模組是先做3×33×3之間會有ReLU非線性啟用,而可分離卷積沒有。
對於區別1,前文已經介紹 Xception 認為兩者是可以相互認同的,它當然不會自相矛盾,因此Xception認為區別1並不重要。所以Xception的後續論證與實驗部分基本都是在討論非線性啟用、殘差連線等因素非但不會影響可分離卷積模組的發揮,而且在模型引數大小相當時,可分離卷積的效果還比Inception好。以此可以論證出Inception基本進入歷史,以可分離卷積為基礎的Xception開始接班。
雖然Xception認為它的工作是解釋可分離卷積如何從Inception發展過來的,但是我認為它的貢獻只是在實驗資料上驗證了可分離卷積模組的有效性,這是我從MobileNet的角度看所得到的結論,我甚至還認為Xception只是補充了MobileNet論文的一些在效果方面的實驗。因為Xception論文只是在文中提到了MobileNet,而並沒有跟它做直接對比,畢竟二者太相近,所以我猜可能是有意規避的。下面我想從兩個方面簡單討論一下Xception的理論問題,一個方面是“極限”Inception模組與可分離卷積模組區別1的重要性,另一方面是MobileNet與Xception的區別,其實也就只是“極限”Inception模組與可分離卷積的區別2。
我先討論MobileNet與Xception的區別。這個區別是MobileNet的 3×33×3 的 point-wise 之間會有ReLU非線性啟用與Batch Normalization計算。我認為Batch Normalization是可以忽略的,因為這在Inference階段只是一個線性運算,可以優化到weights和biases當中,我也驗證過這個結論。至於ReLU非線性,Xception的4.7實驗表示在訓練階段中間沒有任何啟用函式比有啟用函式要好,但我認為在inference階段沒有太大貢獻。所以Xception與MobileNet相比可能在訓練效果上,會有更好的收斂,因此在MobileNet優化上可以考慮去掉中間的一些冗餘的ReLU啟用。
而“極限”Inception模組與可分離卷積模組是否相互認同,我認為這件事情需要滿足某個條件。這條件我用式(11能滿足式(