
記憶體管理七 SLUB分配器管理記憶體
一、概序
linux記憶體管理的基礎是:夥伴系統(buddy system),但夥伴系統是以頁為單位(4kB)管理和分配記憶體。現實
的需求是以位元組為單位,這樣基於Buddy系統分配最小的一個page會嚴重的浪費記憶體。slab分配器就是為了解決此問
題而出現,專為小記憶體分配而生。slab分配器分配記憶體以Byte為單位。但是slab分配器是基於夥伴系統分配的大記憶體
進一步細分成小記憶體分配,是在buddy系統上封裝了一層演算法實現此功能,後面會介紹slab分配的原理及方法。
另外當前都使用的SLUB分配器,SLUB分配器是基於SLAB分配做的優化,使得可以快速地進行物件的分配和回
收並減少記憶體碎片,發明SLUB分配器的主要目的就是減少slab緩衝區的個數,讓更多的空閒記憶體得到使用。
二、相關結構體
slub分配器來說,就是將這段連續記憶體平均分成若干大小相等的object(物件)進行管理。 slub把記憶體分組管理,
每個組分別包含2^3、2^4、...2^11個位元組,每個分組使用一個struct kmem_cache的結構體來描敘。
/* * Slab cache management. */ struct kmem_cache { struct kmem_cache_cpu __percpu *cpu_slab; int size; /* The size of an object including meta data */ int object_size; /* The size of an object without meta data */ int offset; /* Free pointer offset. */ struct list_head list; /* List of slab caches */ struct kmem_cache_node *node[MAX_NUMNODES]; };
- cpu_slab:一個per cpu變數,對於每個cpu來說,相當於一個本地記憶體快取池;
- size:分配給物件object的記憶體大小(可能大於物件的實際大小);
- object_size:實際的object size,就是建立kmem_cache時候傳遞進來的引數;
- offset:存放空閒物件指標的位移;
- list:系統有一個slab_caches連結串列,所有的slab都會掛入此連結串列;
- node:為每個節點建立的 slab 資訊的資料結構,每個node都有一個struct kmem_cache_node資料結構。
/* * The slab lists for all objects. */ struct kmem_cache_node { spinlock_t list_lock; #ifdef CONFIG_SLUB unsigned long nr_partial; struct list_head partial; #ifdef CONFIG_SLUB_DEBUG atomic_long_t nr_slabs; atomic_long_t total_objects; struct list_head full; #endif #endif };
- list_lock:自旋鎖,保護資料;
- nr_partial:slab節點中slab的數量;
- partial:slab節點的slab partial連結串列,儲存部分使用的連結串列。
struct kmem_cache_cpu {
void **freelist; /* Pointer to next available object */
unsigned long tid; /* Globally unique transaction id */
struct page *page; /* The slab from which we are allocating */
struct page *partial; /* Partially allocated frozen slabs */
#ifdef CONFIG_SLUB_STATS
unsigned stat[NR_SLUB_STAT_ITEMS];
#endif
};- freelist:指向下一個可用的object;
- page:slab記憶體的page指標;
- partial:本地slab partial連結串列,主要是一些部分使用object的slab。
struct kmem_cache *kmalloc_caches[12];
關於上面三個連結串列的關係通俗的理解可以參考文章slub演算法,每個陣列kmalloc_caches元素對應一種大小的記憶體,
可以把一個kmem_cache結構體看做是一個特定大小記憶體的零售商,整個slub系統中共有12個這樣的零售商,每個
“零售商”只“零售”特定大小的記憶體,例如:有的“零售商”只"零售"8Byte大小的記憶體,有的只”零售“16Byte大小的記憶體。
每個零售商(kmem_cache)有兩個“部門”,一個是“倉庫”:kmem_cache_node,一個“營業廳”:kmem_cache_cpu。
“營業廳”裡只保留一個slab,只有在營業廳(kmem_cache_cpu)中沒有空閒記憶體的情況下才會從倉庫中換出其他的slab。
三、SLUB分配及釋放介面
1、建立kmem_cache:
struct kmem_cache *kmem_cache_create(const char *name,
size_t size, size_t align,
unsigned long flags,
void (*ctor)(void *))- name:kmem_cache的名稱;
- size :建立的slab管理物件的大小;
- align:slab分配器分配記憶體的對齊位元組數(以align位元組對齊);
- flags:分配記憶體掩碼;
- ctor :分配物件的構造回撥函式。
2、kmem_cache_destroy和kmem_cache_create相反,銷燬建立的對應的slub的kmem_cache結構。
3、分配object的物件kmem_cache_alloc
void *kmem_cache_alloc(struct kmem_cache *s, gfp_t gfpflags)- struct kmem_cache *s:從指定的緩衝池s中分配物件;
- gfpflags:分配掩碼;
4、kmem_cache_free是kmem_cache_alloc的反操作。
5、例程:
void slab_test(void)
{
//create 16byte kmem_cache kmem_cache_16
struct kmem_cache *kmem_cache_16 = kmem_cache_create("kmem_cache_16", 16, 8, ARCH_KMALLOC_FLAGS, NULL);
//alloc buf points of 16 bytes of memory
char *buf = kmeme_cache_alloc(kmem_cache_16, GFP_KERNEL);
//release the memory after use
kmem_cache_free(kmem_cache_16, buf);
//release kmem_cache
kmem_cache_destroy(kmem_cache_16);
}
四、SLUB分配原理
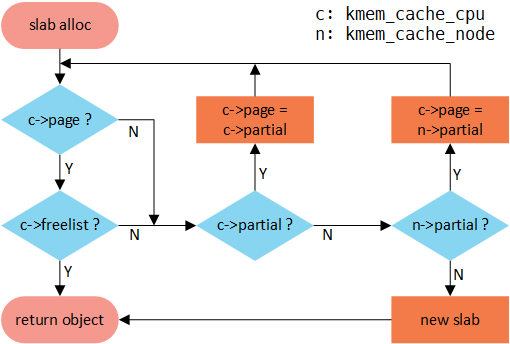
slub的分配原理可以從slub分配器的分配函式看起,kmem_cache_alloc -> slab_alloc -> slab_alloc_node ->
__slab_alloc -> ___slab_alloc ,其中整個分配的流程可以用如下圖清晰的說明。首先從cpu 本地快取池分配,如
果freelist不存在,就會轉向cpu partial分配,如果cpu partial也沒有可用物件,繼續檢視node partial,如果很不幸
也不沒有可用物件的話,就只能從夥伴系統分配一個slab:
五、Kmalloc:
核心中使用的kmalloc函式也是基於slub分配器做的封裝,按照記憶體塊的2^order大小來建立slab描敘符。分配
記憶體的大小可以為16B、32B、64B、128B......32Mb,其對應的分配介面為:kmalloc-16、kmalloc-32、kmalloc-64。
在系統啟動初期會呼叫create_kmalloc_caches ()建立多個管理不同大小物件的slab描敘符kmem_cache(包含16B、
32B、64B、128B......32Mb大小)。
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{
if (__builtin_constant_p(size)) {
if (size > KMALLOC_MAX_CACHE_SIZE)
return kmalloc_large(size, flags);
if (!(flags & GFP_DMA)) {
int index = kmalloc_index(size);
if (!index)
return ZERO_SIZE_PTR;
return kmem_cache_alloc_trace(kmalloc_caches[index],
flags, size);
}
}
return __kmalloc(size, flags);
}根據傳入的對應的size選擇對應的kmem_cahe,系統只能分配2^order大小的slab記憶體,如通過kmalloc(17,
GFP_KERNEL)申請記憶體,系統會從名稱“kmalloc-32”管理的slab快取池中分配一個物件。即使浪費了15Byte:
static __always_inline int kmalloc_index(size_t size)
{
if (!size)
return 0;
if (size <= KMALLOC_MIN_SIZE)
return KMALLOC_SHIFT_LOW;
if (KMALLOC_MIN_SIZE <= 32 && size > 64 && size <= 96)
return 1;
if (KMALLOC_MIN_SIZE <= 64 && size > 128 && size <= 192)
return 2;
if (size <= 8) return 3;
if (size <= 16) return 4;
if (size <= 32) return 5;
......
if (size <= 32 * 1024 * 1024) return 25;
if (size <= 64 * 1024 * 1024) return 26;
BUG();
/* Will never be reached. Needed because the compiler may complain */
return -1;
}
參考博文:
http://www.wowotech.net/memory_management/426.html
https://www.ibm.com/developerworks/cn/linux/l-cn-slub/
https://blog.csdn.net/lukuen/article/details/6935068
作者:frank_zyp
您的支援是對博主最大的鼓勵,感謝您的認真閱讀。
本文無所謂版權,歡迎轉載。