
記憶體管理第一談:段式管理和頁式管理
一:記憶體定址(段式管理) 1.邏輯地址、線性地址、實體地址 很長一段時間,我都搞不懂這三個地址到底是怎麼回事,因為中間牽扯著地址轉換,各種暫存器,各種描述符,描述表,每次看書看著看著就徹底暈菜了。 實體地址:最容易理解的,它就是實實在在實體記憶體上的地址,你PC上有1G記憶體,那最大地址就是0x40000000,0x800就是代表1KB的地址。 線性地址:這是APP用的地址,也就是我們程式設計師寫程式碼用的地址,它是一個虛擬地址,最終會被轉化到實體地址。 邏輯地址:這是最麻煩的一個地址了,它是針對x86的架構形成的地址,你可以先不用理會,明白上面兩個就行了 從線性地址說起,早期的x86的CPU內部有20根地址線,能定址2^20個地址(這些就是全部的線性地址),也就是1MB,但是其中的暫存器只有16位,只能定址 2^16個地址,也就是64KB,這就是帶來個問題,怎麼利用暫存器的16位來定址1MB呢?於是intel想出了一個辦法,把定址分為兩部分,基地址和偏移地址,這也我們以前經常接觸的程式碼段、資料段的由來,實際上就是帶表的基地址。那麼,CPU要訪問一個20位地址,比如這個地址是程式碼段地址,那麼首先CPU要到CS(程式碼段暫存器)中取出基地址,然後再到IP暫存器中取出指令偏移量,組合成一個20位地址(這就是線性地址)然後定址。 這就又帶來一個問題,你說暫存器都是16位的,那麼相加能表示的最大地址就是 0xffff+0xffff=128KB,還是不夠1MB啊,怎麼辦呢?為了解決這個問題,cs暫存器中的數字不再代表實際基地址,而是基地址一個索引。我們把1MB的記憶體分成29個64KB(偏移暫存器的最大訪問量),然後在cs暫存器中存放1-29這30個數字,這樣就能訪問到任意一個1MB內的地址了。現在的 線性地址 = cs*64KB + IP 舉個例子:假如cs存的索引值是5,IP存的是0x556,那麼實際CPU得到的線性地址就是 5*0x10000+0x556 = 0x50556 = 321.333KB,就這麼簡單 理解了上面問題,那麼邏輯地址就很容易理解了,其實就是cs:ip的一種組合地址,你可以理解為一個cpu用的中間地址,它就是段暫存器和偏移暫存器的一個組合,在沒有經過上述處理前沒有任何意義。下圖說明這種關係:
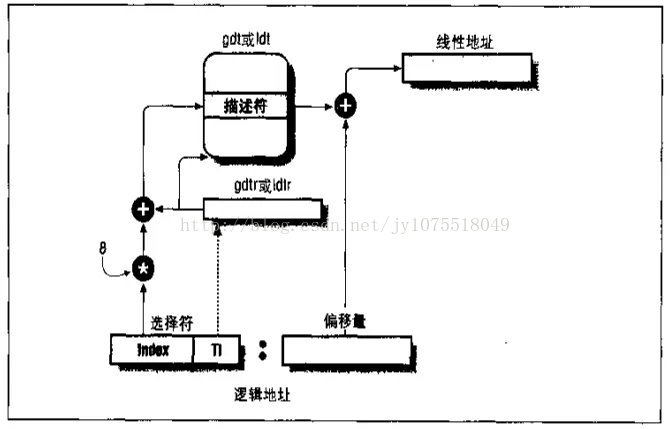
圖上又多了一些標誌,這是現在作業系統(32位)的一種轉換方式,選擇符就是對應上面的CS暫存器,偏移量就是對應上面的IP暫存器,只是它嫌32位的暫存器能表達資訊太少了,於是不再直接由上面方式得出線性地址,而是先把段基址存到一塊記憶體,每個段基址佔8位元組,這8位元組不僅有段基址,還有很多描述段的資訊。所有描述符會把index欄位*8得到某個段的描述符的地址,然後跑到那個地址取出裡邊的段基址再加上IP暫存器的偏移量就得到線性地址了。gdtr這個地方跳過就行。如今段式管理不理解也無所謂,本質還是上面說的東西。 那麼有人就問了,線性地址和實體地址又存在什麼關係呢?你可以想象這麼一種場景,還是這20位的cpu,上面執行著qq,現在你發了一條訊息,但這條訊息的指令在 0x50556 地址處,上面講了,這時候cs=5,ip=0x556,好了,cpu知道要去 0x50556地址取東西了,結果呢,你計算機只有 64KB 的實體記憶體,CPU一看根本沒有這個地址,程式就完蛋了。解決這個問題有兩種方案,第一,浪費CPU的4跟地址線,規定系統支援最大記憶體就是64KB。第二,想其它辦法。 很明顯,第一種完全不可取,為了解決這個問題,就有了記憶體管理中的分頁管理機制,用來確定線性地址和實體地址之間的關係。 二:頁式管理機制 如果做linux下核心開發,對於上述的x86的段式管理可以完全不用理會,因為linux根本沒有用intel弄出來的這個段式管理,而是以頁式管理完成了所有的記憶體管理工作。在說這塊內容之前先做一個小實驗來引入頁式管理機制。 試驗內容:同一個程式,執行兩次(產生兩個程序),然後觀察程序執行空間 這是程式原始碼,很簡單,為了不至於瞬間結束,睡眠100s
/* test.c */ #include <stdio.h> int main() { int i = 0; i = i + 1; sleep(100); }
編譯:gcc -o test test.c 在後臺執行兩次: [email protected]:/ceshi/app/test$ ./test& [1] 18368 [email protected]:/ceshi/app/test$ ./test& [2] 18369 用PS命令檢視程序號: [email protected]:/ceshi/app/test$ ps PID TTY TIME CMD 17751 pts/2 00:00:00 bash 18368 pts/2 00:00:00 test 18369 pts/2 00:00:00 test 18370 pts/2 00:00:00 ps 可以看到兩個程序的程序號分別是 18368 和 18369,然後到proc檔案系統檢視程序地址空間

圖上線性地址就是經過第一部分段式管理轉換得到的地址,如果你跳過上面第一部分的話,完全可以理解為就是我們平時程式執行的地址,這些地址是你能通過某些命令獲得的,真正的實體地址核心是不會讓你看到的,否則人人不都能變成黑客了。言歸正傳,現在CPU知道了這個32位的線性地址,那麼如何到真正的實體記憶體取出需要的資料呢?
看下圖,這幅圖是我畫的,所以比較醜,湊合看吧
 首先,這32位的線性地址會被分成3個部分,10位頁目錄,10位頁表,12位頁偏移。好了,又回來了,頁目錄和頁表,你可以理解為記憶體中儲存的一張張的擁有1024個表項的二維表,頁目錄每一項存放的是某個頁表的地址,而頁表中每一項存放的是某個頁的地址。你可以理解為C語言裡的指標,每個表項存的都是一個指標,指向某個記憶體地址。這個內容是必須要理解的,我給大家舉個具體的例子:
假如線性地址是 0x00401001 ,表示為二進位制是 0000000001 0000000001 000000000001 ,對應上面三個名詞,那麼頁目錄值、頁表值和頁內偏移值都是1,也就說要想找到真正的實體地址,首先應該到頁目錄(擁有1024個頁目錄項)的第一項中定址,這個項中存的是頁表的地址,假如是1000,CPU就會跑到1000的實體地址(注意,真的是實體地址)上找到某個頁表,這個頁表又擁有1024項的頁表項。然後拿到第二個10位地址(還是1),也就說到第一個頁表上的第一項,到這裡,其實就已經能找到實體記憶體塊了。想一下,每個頁表項代表4KB,每個頁表又1024個頁表項,而頁目錄項總共有1024個頁目錄項(=1024張頁表),所以能表示的總大小正好是
首先,這32位的線性地址會被分成3個部分,10位頁目錄,10位頁表,12位頁偏移。好了,又回來了,頁目錄和頁表,你可以理解為記憶體中儲存的一張張的擁有1024個表項的二維表,頁目錄每一項存放的是某個頁表的地址,而頁表中每一項存放的是某個頁的地址。你可以理解為C語言裡的指標,每個表項存的都是一個指標,指向某個記憶體地址。這個內容是必須要理解的,我給大家舉個具體的例子:
假如線性地址是 0x00401001 ,表示為二進位制是 0000000001 0000000001 000000000001 ,對應上面三個名詞,那麼頁目錄值、頁表值和頁內偏移值都是1,也就說要想找到真正的實體地址,首先應該到頁目錄(擁有1024個頁目錄項)的第一項中定址,這個項中存的是頁表的地址,假如是1000,CPU就會跑到1000的實體地址(注意,真的是實體地址)上找到某個頁表,這個頁表又擁有1024項的頁表項。然後拿到第二個10位地址(還是1),也就說到第一個頁表上的第一項,到這裡,其實就已經能找到實體記憶體塊了。想一下,每個頁表項代表4KB,每個頁表又1024個頁表項,而頁目錄項總共有1024個頁目錄項(=1024張頁表),所以能表示的總大小正好是4kb*1024*1024=4GB。而上面所說最終找到的這個頁表項裡邊存的就是一個指標(你可以這麼想象,其實不是),它指向一塊真實實體記憶體的邊界。並不是每一個頁表項都有實體記憶體相對應的,核心只為程序用到的那些線性地址實時的分配實體記憶體頁,這種叫寫時複製機制,這裡簡單一提,等到後邊再介紹。好了,通過兩張表的查詢,終於通過線性地址的高20位找到了對應的4KB實體記憶體,那麼怎麼找到某個位元組呢,相信都想到了,就是最後的12位作用了,找到了這4KB的實體記憶體邊界,再加上12位的偏移值即可。12能表示多大呢?2^12=4096,正好是4KB,所以就能精確找到4KB區域內的任意一個位元組,設計的巧妙吧。
圖中藍線就是上面定址過程。頁管理機制吧,說實話挺抽象的,需要多看幾遍,自己畫畫圖才能真正理解,上面說的這些可能也有不當地方,畢竟細節處我也沒有去追蹤程式碼,不過大部分還是對的。想要真正徹底搞懂,還是看原始碼吧,《linux核心完全註釋》這一塊講的還是蠻不錯的,想深入瞭解的可以先看下這本書。
記憶體管理其他部分,請期待第二談...
相關推薦
記憶體管理第一談:段式管理和頁式管理
對於記憶體管理這個作業系統中龐大的體系,實在是容易讓人望而止步,市面上介紹這塊知識的書籍其實很多,但是由於書面語言的緣故,總感覺有些東西晦澀難懂,先後看過的書籍有《作業系統基本原理》、《linux核心完全註釋》、《深入理解linux核心》、《linux核心原始碼情景分析》
linux記憶體管理-段式和頁式管理
該博文參考國嵌視訊和http://www.cnblogs.com/image-eye/archive/2011/07/13/2105765.html,在此感謝作者。 一、地址型別 實體地址:CPU通過地址匯流排的定址,找到真實的實體記憶體對應地址。 邏輯地址:程式
作業系統記憶體管理——分割槽、頁式、段式、段頁式管理
1. 記憶體管理方法 記憶體管理主要包括虛地址、地址變換、記憶體分配和回收、記憶體擴充、記憶體共享和保護等功能。 2. 連續分配儲存管理方式 連續分配是指為一個使用者程式分配連續的記憶體空間。連續分配有單一連續儲存管理和分割槽式儲管理兩種方式。 2
YII框架分析筆記2:組件和事件行為管理
reac 設置 有變 相關 article class ces col cal Yii是一個基於組件、用於開發大型 Web 應用的高性能 PHP 框架。CComponent幾乎是所有類的基類,它控制著組件與事件的管理,其方法與屬性如下,私有變量$_e數據存放事件(evnet
段式和頁式儲存管理試題及答案(整理)
1、段式和頁式儲存管理的地址結構很類似,但是它們有實質上的不同,以下錯誤的是(D) A.頁式的邏輯地址是連續的,段式的邏輯地址可以不連續 B.頁式的地址是一維的,段式的地址是二維的 C.分頁是作業系統進行的,分段是使用者確定的 D.頁式採用靜態重定位方式,段式
第一篇:版本控制git之倉庫管理
分支 最終 場景 ret linux cbe 每次 ref 命令執行 ---恢復內容開始--- 再開始這個話題之前,讓我想起了一件很痛苦的事情,在我大學寫畢業論文的時候,我當時的文件是這樣保存的 畢業論文_初稿.doc 畢業論文_修改1.doc 畢業論文_修改2
第一節:神經網絡和深度學習
進化 alt 自然 這就是 eve 人類 網絡應用 快照 函數 修正現行單元單神經元網絡在監督學習當中,你輸入一個x,習得一個函數,映射到輸出y 例如房屋價格預測例子當中,輸入房屋的一些特征,就能輸出或者是預測價格y,在現今,深度學習神經網絡效果拔群,最主要的就是在線廣告,
第一章:程序設計和C語言
統一 c程序 集合 out 包含 有一個 機器 文件名 部分 一、什麽是計算機程序? 所謂程序就是一組計算機能識別和執行的指令。計算機的一切操作都是由程序控制的,本質是程序的機器,程序和指令是計算機系統最基本的概念。 二、什麽是計算機語言? 人和計算機交流信息要
易學筆記-系統分析師考試-第3章 作業系統基本原理/3.3 記憶體管理/3.3.3 段頁式管理
分頁式儲存管理 概念:為了避免分割槽式管理產生儲存碎片和管理複雜的問題,分頁式管理把作業的邏輯地址劃分成若干個相等的區域(稱為頁),記憶體空間也劃分成若干個與頁長度相等的區域(也稱為頁幀或塊),然後把頁裝載到頁幀中 特點 頁幀可以是連續的,也可以是不連續的
電子學第一課:logic family 和 pull-up 等
當學過了電路基本的知識之後,我覺得接下來需要掌握的重要的知識有:(待續) 1. logic family :掌握元器件的編號規則,以及半導體設計中”代“的概念,這樣你就知道如何在模擬和之際製作中選擇元件了。走過了很多彎路,終於知道了4000系列(例如cd4069)和HC系列(74HC14)的區別了——功能一
初夏小談:函式 strchr 和 strcmp 詳解
實現和strchr(查詢字元首次出現的位置) #include<Aventador_SQ.h> int Strchr(char arr[], char Char,int* location) { int i = 0; int ArrLen = strlen(arr); int
Scrapy基礎 第一節:Scrapy介紹和安裝配置
Scrapy第一季:Scrapy框架基礎介紹 前置知識: 掌握Python的基礎知識 對爬蟲基礎有一定了解 說明: 執行環境 Win10,Python3 64位 目錄: 第一節:Scrapy介紹和安裝配置 第二節:Scrapy版的Hello World
《計算機網路-自頂向下方法原書第六版》~~~~~第一章:計算機網路和因特網
1.1 什麼是因特網 1.1.1 具體構成描述 1. 端系統(主機):資料的傳送或接受的終端。 2. 通訊鏈路:資料傳輸的媒介。 3. 分組:資料在鏈路中傳輸的一種封裝格式。 4. 路由器:負責轉發資料,用於網路核心中。 5. 鏈路層交換機:負責轉發資料,用於接入
儲存管理之頁式、段式、段頁式儲存
首先看一下“基本的儲存分配方式”種類: 1. 離散分配方式的出現 由於連續分配方式會形成許多記憶體碎片,雖可通過“緊湊”功能將碎片合併,但會付出很大開銷。於是出現離散分配方式
作業系統儲存管理之分段式與段頁式虛擬儲存系統
分段式虛擬儲存系統 分段式虛擬儲存系統把作業的所有分段的副本都存放在輔助儲存器中,當作業被排程投入執行時,首先把當前需要的一段或幾段裝入主存,在執行過程中訪問到不在主存的段時再把它們裝入。因此,在段表中必須說明哪些段已在主存,存放在什麼位置,段長是多少。哪些段
Android Sprd省電管理(四)自啟動和關聯啟動管理
自啟動和管理啟動管理介紹 自啟動管理用於管理應用的開機自啟動/後臺自啟動/關聯自啟動。應用自啟動的管理,以包名(應 用名)進行限制,不區分 user(使用者)。 (1)自啟動 指開機自啟動和後臺自啟動。應用可以監聽系統的一些開機廣播,從而在系統開機後自動進行啟動。 同時應用也可以監聽系統的任
linux核心--段頁式管理記憶體的方法
一、概念 實體地址(physical address) 用於記憶體晶片級的單元定址,與處理器和CPU連線的地址匯流排相對應。 ——這個概念應該是這幾個概念中最好理解的一個,但是值得一提的是,雖然可以直接把實體地址理解成插在機器上那根記憶體本身,把記憶體看成一 個從0位元組一
【學習日記】吳恩達深度學習工程師微專業第一課:神經網路和深度學習
以下內容是我聽吳恩達深度學習微專業第一課做的學習筆記,主要是按自己的理解回答一些問題,並非全部出自課程內容。1. 什麼是神經網路?神經網路是諸多機器學習方法中的一種,受人類大腦工作方式的啟發而發明的。人類大腦的一個神經元通過多個樹突來接收來自不同神經元的訊號,接著細胞核處理訊
儲存管理之頁式、段式、段頁式儲存 以及 優缺點
記憶體管理方式主要分為:頁式管理、段式管理和段頁式管理。 頁式管理的基本原理是將各程序的虛擬空間劃分為若干個長度相等的頁。把記憶體空間按頁的大小劃分為片或者頁面,然後把頁式虛擬地址與記憶體地址建立一一對應的頁表,並用相應的硬體地址轉換機構來解決離散地址變換問題。頁式管理採用
Python人工智慧第一篇:語音合成和語音識別
Python人工智慧第一篇:語音合成和語音識別 此篇是人工智慧應用的重點,只用現成的技術不做底層演算法,也是讓初級程式設計師快速進入人工智慧行業的捷徑。目前市面上主流的AI技術提供公司有很多,比如百度,阿里,騰訊,主做語音的科大訊飛,做只能問答的圖靈機器人等等。這些公司投入了很大一部分財力物力人力將底層封