
關於GreenPlum的一些整理
本人菜鳥一隻,如果有什麼說錯的地方還請大家批評指出!!
這篇文章用來整理下gp的一些東西,不是概念搭建七七八八的東西,就是單純的一些sql和使用。
1、gp是分散式的資料庫,跟hadoop有點類似,也是有master和slave的架構關係
摘抄作者的話:Greenplum所有的並行任務都是在Segment資料節點上完成後,Master只負責生成和優化查詢計劃、派發任務、協調資料節點進行平行計算,Master上的資源消耗很少有超過20%情況發生,因為Segment才是計算和載入發生的場所(當然,在HA方面,Greenplum提供Standby Master機制進行保證)。
缺陷:他和hadoop一樣不支援多併發,也就是說sql不多的時候,執行速度會很快,但是如果有多個sql一起執行,就會奇慢無比!
2、索引和壓縮:
索引:GreenPlum是有索引的(但是實際上,我並沒有多GP的索引有多少的測試),大概如下:
-1.如果是從超大結果集合中返回非常小的結果集(不超過5%),建議使用BTREE索引(非典型資料倉庫操作)
-2.表記錄的儲存順序最好與索引一致,可以進一步減少IO(好的index cluster)
-3.where條件中的列用or的方式進行join,可以考慮使用索引
-4.鍵值大量重複時,比較適合使用bitmap索引
壓縮:其實壓縮也是為了加快查詢速度,概念如下:
-1.不需要對錶進行更新和刪除操作
-2.訪問表的時候基本上是全表掃描,不需要建立索引
-3.不能經常對錶新增欄位或者修改欄位型別
實際測試:
CREATE TABLE "資料庫"."表" (
"欄位1" varchar(20),
"欄位2" int4,
"欄位3" int8,
"欄位4" numeric,
....
)
WITH (APPENDONLY=true, COMPRESSLEVEL=1, ORIENTATION=column, COMPRESSTYPE=rle_type)
DISTRIBUTED randomly;在我們的叢集環境下,如下建立一張排名表,效能會比建立索引好很多(查詢8s優化到1.5s),原因是因為伺服器上磁碟IO經常跑滿,但是cpu挺空閒的,所以把壓力推到cpu讓它去壓縮和解壓縮,緩解磁碟io的壓力
3、分佈鍵
個人覺得分佈鍵是一個挺重要的東西,因為分佈不均勻就會導致實現不了並行,從而影響查詢的速度。
CREATE TABLE "資料庫"."表" (
"欄位1" varchar(50),
"欄位2" varchar(500),
"欄位3" varchar(500),
....
"時間" timestamp(6) DEFAULT now()
)
distributed by(欄位1,欄位2)
;
-1.distributed by(欄位1, 欄位2)
括號裡面可以是一個欄位,也可以是多個欄位,一般來說都是通過使用者id,裝置mac,這種很隨機的值來給定分佈鍵。
如果在建表的時候不給定分佈鍵,那麼分佈鍵就會是這張表的主鍵,或者是第一個欄位。
也可以給定隨機分佈,把distributed by(欄位1, 欄位2)替換成DISTRIBUTED randomly
-2.修改分佈鍵:alter table "資料庫"."表名" set distributed randomly;
-3.檢視分佈情況:
select gp_segment_id,count(*) from "資料庫"."表名" group by gp_segment_id;-4.舉個例子,如果你設定一個分佈鍵叫做flag,然後這個欄位只有兩個值0和1,你有一個20臺機器組成的GreenPlum,那這張表只會分佈到兩臺機器上,在計算的時候,也只會動用這兩臺機器運算能力,其他18臺在圍觀,所以分佈鍵要合理分配!
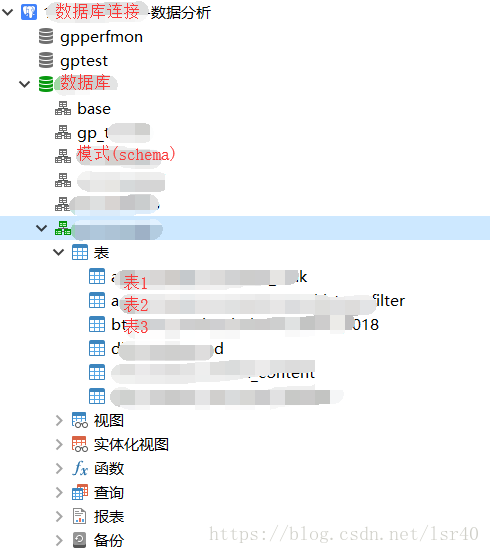
4、層級關係
-1.資料庫連線
-2.建立資料庫
-3.建立模式(也叫schema)
-4.建立表
所以它多了一層叫做模式的東西,如下圖:
5、關於sql
-1.視窗函式很好用!
row_number() over(partition by XXX order by XXX desc)
max() over(partition by XXX order by XXX)
avg() over(partition by XXX order by XXX)
....
-2.行列互轉
--列轉行(GP)
SELECT uid,String_agg(DISTINCT tag) as tag FROM (SELECT uid,tag FROM 資料庫.表
WHERE create_time BETWEEN '20180601' AND '20180701') tagtb GROUP BY uid;
--列轉行(pg postgresql)
SELECT string_agg(name,',') from test;
--行轉列(pg postgresql)
SELECT regexp_split_to_table(name,',') from test;
--行轉列的去重(實際運用)
SELECT * FROM (SELECT
regexp_split_to_table(tag_name,',') as tag
FROM
表A )tb
WHERE
tag IS NOT NULL
GROUP BY
tag
ORDER BY
1 ASC;
使用的時候注意下,不同的sql行列互轉的函式傳參甚至名稱可能不太一樣,然後如果把列轉成行最好要有個分隔符,方便後面的分詞查詢!
-3.update(b表計算出的某一個欄位設定的想要更新欄位的表中,通過uid來關聯)
update 資料庫.想要更新欄位的表 tb set 想要更新的欄位=b.另一張表的相同欄位
from (SELECT uid,String_agg(DISTINCT tag) as tag
FROM (SELECT uid,tag FROM 資料庫.另一張表 WHERE 條件) tagtb
GROUP BY uid) b
where tb.uid=b.uid;
--1、更新表中前10條資料(更新為固定值):
update BranchAccount
set AccountNumber = '10010'
from (select top 10 *from BranchAccountorder by ID)as t1
where BranchAccount.ID = t1.ID
--2、用一個表的欄位值更新另一個表的某欄位值:
update BranchAccount
set BranchAccount.AccountNumber = t1.AccountNumber
from TEMPBranchAccount as t1
where BranchAccount.ID = t1.ID
--3、更新表前10條資料(更新為另一個表的資料):
update BranchAccount
set BranchAccount.AccountNumber = t1.AccountNumber
from (select top 10 *from TEMPBranchAccount)as t1
where BranchAccount.ID = t1.ID
暫時寫到這吧,感覺還沒寫完,如果以後想到什麼再加進來吧,或者大家如果有什麼想問的,可以給我留言!希望我能夠幫上忙~
============================================================================
補充一:
記錄幾個關於日期的處理sql
--注:gmt_modified 這個欄位是 default now()
--求當前5天的資料
select * from 庫名.表明 WHERE gmt_modified >= (SELECT now() - interval '5 D')
--第二段是這樣的,表A和表C中對應天的資料計算結束之後,並且確定表B中沒有計算當天的資料之後,就返回要計算的日期,主要想說的是可以通過這種方式給定日期的範圍to_char((SELECT now() - interval '5 D'),'yyyyMMdd') ,date_id是int型別
select *from (
select rc.date_id::VARCHAR as date_id,'${date_type}' as date_type from (
select date_id,status_flag from 表A where date_id>='${date_id}' and status_flag='Completed' ORDER BY date_id desc
limit 9999 ) rc
where not EXISTS (select date_id from 表B b where rc.date_id=b.date_id and rc.status_flag=b.status_flag)
and EXISTS (select date_id from 表C b where rc.date_id=b.date_id)
) tb
where tb.date_id <=(to_char((SELECT now() - interval '5 D'),'yyyyMMdd'))
ORDER BY date_id;
--第三段是求資料庫中的最新日期的前幾天
select count(1),gmt_modified,next_gmt_modified from (
select to_char(freshtime,'yyyyMMdd') as gmt_modified,(to_char(((select max(freshtime) from 表A) - interval '3 D'),'yyyyMMdd')) as next_gmt_modified from 表A
where freshtime is not null
) tb
where gmt_modified >= next_gmt_modified
GROUP BY gmt_modified,next_gmt_modified ORDER BY 2 desc;
--但是第三段有個缺點,缺點是gmt_modified更新時間一般來說不會做索引什麼的,如果要求這個欄位的最大值,很有可能查詢速度奇慢無比,因此就需要用到其他方式來解決這個問題
--例如,如果該表有自增的主鍵id,那麼我只要拿到id最大的那條資料的更新時間,就是最新的時間,而且實際執行,第三段sql在資料多的情況下,需要查詢半小時。。。但是如下sql只需要不到1秒鐘!!
select * from 表A where
freshtime >=
(
select next_gmt_modified::TIMESTAMP from (
select to_char(freshtime,'yyyyMMdd'),to_char((freshtime - interval '3 D'),'yyyyMMdd') as next_gmt_modified from 表A where 主鍵 in (select max(主鍵)from 表A )
) tb ) 補充二:
pg上的相關的元資料sql
--查詢表佔用空間大小
select pg_size_pretty(pg_relation_size('表名'));
--查詢某張表,在某個schema上是否存在
select * from pg_class where relname='表名'::name and relkind='r' ) a INNER JOIN
pg_namespace b on a.relnamespace = b.oid
WHERE nspname = 'schema名'
--殺掉某個sql
select pg_terminate_backend(傳入sqlid);
--查詢當前正在執行的sql情況(可做成檢視)
SELECT (( 'select pg_cancel_backend(' :: TEXT || pg_stat_activity.procpid ) || ');' :: TEXT
),
( now() - pg_stat_activity.query_start ) AS cost_time,
pg_stat_activity.datid,
pg_stat_activity.datname,
pg_stat_activity.procpid,
pg_stat_activity.sess_id,
pg_stat_activity.usesysid,
pg_stat_activity.usename,
pg_stat_activity.current_query,
pg_stat_activity.waiting,
pg_stat_activity.query_start,
pg_stat_activity.backend_start,
pg_stat_activity.client_addr,
pg_stat_activity.client_port,
pg_stat_activity.application_name,
pg_stat_activity.xact_start,
pg_stat_activity.waiting_reason,
pg_stat_activity.rsgid,
pg_stat_activity.rsgname,
pg_stat_activity.rsgqueueduration
FROM
pg_stat_activity
WHERE
(
pg_stat_activity.current_query <> ALL ( ARRAY [ '<IDLE>' :: TEXT, '<insufficient privilege>' :: TEXT ] ))
ORDER BY
( now() - pg_stat_activity.query_start ) DESC推薦的部落格:https://blog.csdn.net/u010256965/article/details/50515954(關於gp的數值處理函式,作者:u010256965)