
【C++】函式引用
概念:
引用不是新定義一 個變數,而是給已存在變數取了一個別名,編譯器不會為引用變數開闢記憶體空間,它和它引用的變數共用同一塊記憶體空間。
用法:
型別& 引用變數名(物件名) =引用實體;
void Test()
{
int a=10;
int& ra = a;//定義引用型別(相當於ra是a的別名)
printf("%p\n"。&a);
printf("%p\n",&ra);
}注意: 引用型別必須和引用實體是同種型別的
引用特性:
1.引用在定義時必須初始化;
int main()
{
int a = 10;
int& ra ;//不進行初始化,程式碼編譯時出錯2.一個變數可以有多個引用(還可以給別名取別名);
#include <stdio.h> #include <stdlib.h> #include <iostream> int main() { int a = 10; int& ra = a;//定義引用型別(相當於ra是a的別名) int& qa = ra; printf("%p\n",&a); printf("%p\n",&ra); printf("%p\n", &qa); system("pause"); return 0; }
3.引用一旦引用一個實體,再不能引用其它實體。
int main()
{
int a = 10;
int& ra = a;//定義引用型別(相當於ra是a的別名)
int b = 0;
int& ra = b;
printf("%p\n",&a);
printf("%p\n",&ra);
printf("%p\n", &ra);
system("pause");
return 0;
}
//該程式碼編譯時出錯,因為ra既引用了a,又引用了b常引用
void testRef() { const int a = 10; int& ra = a;//該語句編譯時會出錯,a為常量 const int& ra = a;//正確 int b=10;//該語句編譯時會出錯,a為常量 const int& b = 10;////正確 int i = 10; double& rd =i;//該語句編譯時會出錯,型別不同 const double& rd = i;//正確 } int main() { testRef(); system("pause"); return 0; }
其中:
int i = 10;
double& rd =i;//該語句編譯時會出錯,型別不同這個程式碼出錯的真正原因並不是因為型別,而是因為在隱式轉換中,會生成臨時變數,而臨時變數是由編譯器生成的,具有常屬性,不能被修改,而rd也就相當於給這個臨時變數起別名,所以只有加上const時,程式碼才能執行通過。
引用時,對許可權有一個要求:許可權只能縮小,不能放大,比如:
void testRef()
{
const int a = 10;
int& b = a;
}此時這個別名是取不出來的,因為型別匹配不上,a是const int型別,也就是說a是不能被改變的,b變成a的別名,b的型別是int,意味著b可以被修改,相當於a的許可權被擴散化(修改),所以不能這樣。加上const就可以了。
void testRef()
{
const int a = 10;
const int& b = a;
}許可權擴大化不可以,但是縮小又是可以的,如:
void testRef()
{
int c = 20;
const int& d = c;
}這個是正確的,c是可讀可修改,給d後,可讀但不修改。
引用作用:
1.做引數(效率高)
void Swap(int& left, int& right)
{
int tmp = left;
left = right;
right = tmp;
}2.做返回值(相當於少開闢一個空間,效率高)
int& TestRef(int& a)
{
a += 10;
return 0;
}傳值和傳引用的效率比較
以值作為引數或者返回值型別,在傳參和返回期間,函式不會直接傳遞實參或者將變數本身直接返回,而是傳遞實參或者返回變數的一份臨時拷貝,因此用值作為引數或返回值型別,效率是非常低下的,尤其是當引數或者返回值型別非常大時,效率就更低。那指標和引用作為引數和返回值型別的效率呢?
(1)指標和引用作為引數的效能比較
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
#include <time.h>
using std::cout;
using std::endl;
struct A
{
int a[100000];
};
void TestFunc1(A* a)//指標
{
}
void TestFunc2(A& a)//引用
{
}
void TestRefAndPtr()//
{
A a;
//以指標作為函式引數
size_t begin1 = clock();
for (size_t i = 0; i < 100000; i++)
TestFunc1(&a);
size_t end1 = clock();
//以指標作為函式引數
size_t begin2 = clock();
for (size_t i = 0; i < 100000; i++)
TestFunc2(a);
size_t end2 = clock();
//分別計算兩個函式執行結束後的時間
cout << "TestFunc1(int*)-time:" << end1 - begin1 << endl;
cout << "TestFunc2(int&)-time:" << end2 - begin2 << endl;
}
//執行多次,檢測指標和引用在傳參方面的效率差別
int main()
{
for (int i = 0; i < 10; i++)
{
TestRefAndPtr();
}
system("pause");
return 0;
}很明顯,引用要比指標效率更高一些:

(2)指標和引用作為返回值型別的效能比較
//作為返回值型別的效能比較
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
#include <time.h>
using std::cout;
using std::endl;
struct A
{
int a[100000];
};
A a;
A* TestFunc1()//指標
{
return &a;
}
A& TestFunc2()//引用
{
return a;
}
void TestRefAndPtr()//
{
//以指標作為函式引數
size_t begin1 = clock();
for (size_t i = 0; i < 10000000; i++)
TestFunc1();
size_t end1 = clock();
//以指標作為函式引數
size_t begin2 = clock();
for (size_t i = 0; i < 10000000; i++)
TestFunc2();
size_t end2 = clock();
//分別計算兩個函式執行結束後的時間
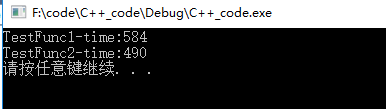
cout << "TestFunc1-time:" << end1 - begin1 << endl;
cout << "TestFunc2-time:" << end2 - begin2 << endl;
}
//執行多次,檢測指標和引用在傳參方面的效率差別
int main()
{
TestRefAndPtr();
system("pause");
return 0;
}顯而易見:依舊是引用的效率高
引用和指標的區別:
在語法概念上,引用就是一個別名,沒有獨立空間,和其引用實體共用一塊空間。(概念上來說,引用是別名,而指標是地址。引用概念上雖然不是存地址,但是在底層,還是用存地址的方式實現的)
引用和指標的不同點:
1.引用在定義時必須初始化,指標沒有要求
2.引用在初始化時引用一個實體後,就不能再引用其他實體,而指標可以在任何時候指向任何一個同類型實體
3.引用沒有NULL引用,但指標有NULL指標
4.在sizeof中含義不同:引用結果為引用型別的大小,但指標始終是地址空間所佔位元組個數(32位平臺下佔4個位元組)
5.引用自加即引用的實體增加1,指標自加即指標向後偏移一個型別的大小6.有多級指標,但是沒有多級引用
7.訪問實體方式不同,指標需要顯式解引用,引用是編譯器自己處理
8.引用比指標使用起來相對更安全
問題:如何定義一個8位元組的指標?
控制一個64位的編譯器即可(把編譯器修改為64位的)。