爬蟲入門之爬取靜態網頁表格資料
阿新 • • 發佈:2018-11-16
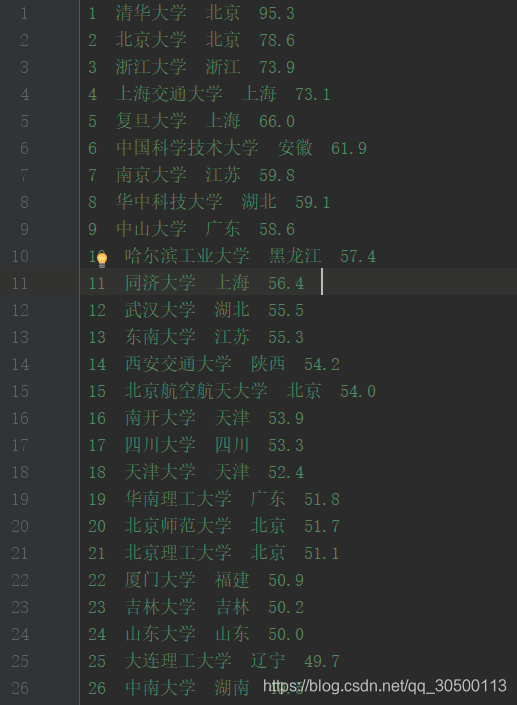
我們的目標就是將這個表格中的資料爬下來儲存成csv檔案
目標連結:http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html

內容解析部分 我更喜歡使用Pyquery 你也可以使用其他的解析方式
#!/usr/bin/env python # -*- coding: utf-8 -*- import requests from pyquery import PyQuery as pq def get_page(url): """發起請求 獲得原始碼""" r = requests.get(url) r.encoding = 'utf8' html = r.text return html def parse(text): """解析資料 寫入檔案""" doc = pq(text) # 獲得每一行的tr標籤 tds = doc('table.table tbody tr.alt').items() for td in tds: rank = td.find('td:first-child').text() # 排名 name = td.find('div').text() # 大學名稱 city = td.find('td:nth-child(3)').text() # 城市 score = td.find('td:nth-child(4)').text() # 總分 with open('college.csv', 'a+', encoding='utf8') as f: f.write(rank + '\t\t') f.write(name + '\t\t') f.write(city + '\t\t') f.write(score + '\t\t\n') print("寫入完成") if __name__ == "__main__": url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html" text = get_page(url) parse(text)
執行程式碼之後檢視檔案