
[Python爬蟲]爬蟲例項:離線爬取噹噹網暢銷書Top500的圖書資訊
本例項還有另外的線上爬蟲實現,有興趣可點選線上爬取噹噹網暢銷書Top500的圖書資訊
爬蟲說明
1.使用requests和Lxml庫爬取,(用BS4也很簡單,這裡是為了練習Xpath的語法)
2.爬蟲分類為兩種,一種是線上爬蟲,即在網站中一邊開啟網頁一邊進行爬取;第二種是本例項使用的離線爬蟲,即先將所爬取的網頁儲存到本地,再從本地網頁中爬取資訊
3.離線爬蟲的優點是:可以方便爬蟲的除錯修改,且一次儲存,可以多次爬取,不必擔心網路資源,網路速度以及是否被網站監測.
4.離線爬蟲的缺點是:需要先進行網頁的儲存,如果爬取的網頁比較多,那麼需要儲存到本地佔用的空間就越大,而且文件還涉及到許多不必要的資訊,浪費空間.其次是爬取鏈問題,如果需要在當前網頁中爬取另一個網頁(超連結),那麼該網頁也需要儲存,並且需要指定存放的位置.最後是編碼的問題,涉及了網頁的編碼,檔案的讀取儲存編碼的統一,這裡可能會遇到一些編碼問題需要處理.
爬蟲介紹
本次爬蟲爬取的網頁為:
圖書暢銷榜-10月暢銷書排行榜-噹噹暢銷圖書排行榜
爬取的資訊包括圖書的排名,書名,作者,好評率,購買頁面以及ISBN
如圖:
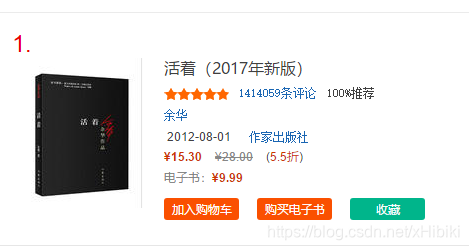
其中,ISBN需要在購買頁面連結中繼續爬取,找到ISBN

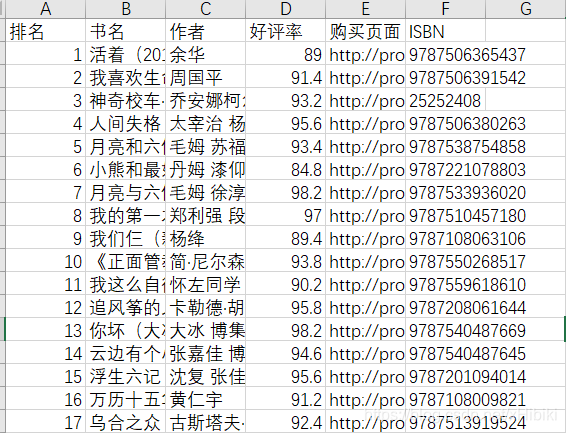
爬取之後的結果整理好存放到csv檔案中.
最終成果如圖:
爬蟲程式碼
觀察需要爬取的第一頁和最後一頁:
http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-month-2018-10-1-1
http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-month-2018-10-1-25
發現只有最後一個數字改了,且每頁顯示20本圖書,所以25*20=500,搞定.
這裡自己了一個spider.py
import requests
import re
def get_encoding(url, headers=None): # 一般每個網站自己的網頁編碼都是一致的,所以只需要搜尋一次主頁確定
'To get website\'s encoding from tag<meta content=\'charset=\'UTF-8\'>'#從<meta>標籤中獲取
res = requests.get(url, headers=headers)
charset = 在dangdang_best_selling_offline.py中,程式碼如下:
import spider
import csv
import os
import requests
import time
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/'
'537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36'
} # 設定headers
encoding = spider.get_encoding('http://www.dangdang.com', headers) # 獲取網站編碼
urls = ['http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-month-2018-10-1-{}'.format(i) for i in
range(1, 26)] #構造網頁
# 儲存書單頁面與詳細頁面(離線儲存)
for i in range(25):
dirpath = 'd:/dangdang/2018-10-{}/'.format(i + 1) #先手動確保d:/dangdang 資料夾存在
if not os.path.exists(dirpath): # 子資料夾不存在則建立資料夾
os.mkdir(dirpath)
filepath = dirpath + 'list.html'
if not os.path.exists(filepath):
res = requests.get(urls[i], headers)
spider.savepage(res, filepath, encoding) # 儲存當前書單頁面
time.sleep(0.5) # 緩衝0.5秒,防止請求頻率過快
pattern = '//ul[@class="bang_list clearfix bang_list_mode"]/li/div[2]/a/@href'
detail_url = etree.HTML(res.text).xpath(pattern) # 獲取每一本書的詳細頁面
for id, url in enumerate(detail_url): # 儲存每本書的頁面
filepath = dirpath + '{}.html'.format(id + 1)
res = requests.get(detail_url[id], headers)
spider.savepage(res, filepath, encoding)
time.sleep(0.5)
執行完上面的程式碼後(等待一段時間),就得到以下結果:

上述的是每一個頁面對應一個資料夾,共25個
開啟資料夾:
每個資料夾都有一個list.html,這是儲存了當前頁面的html,還有20個按序號排列的html,每一個html代表著一本書的單獨頁面用來獲取ISBN,(除此以外還能夠爬取很多資訊,自己玩去)
下面是爬取和儲存的程式碼:
# 儲存所有頁面後,進行離線爬蟲的準備
if __name__ == '__main__':
output = open('d:/dangdang/result.csv', 'w', newline='') # 將資訊匯出到csv,設定newline=""去除寫一行空一行的影響
writer = csv.writer(output) # csv writer
writer.writerow(('排名', '書名', '作者', '好評率', '購買頁面', 'ISBN'))
for page in range(25):
dirpath = 'd:/dangdang/2018-10-{}/'.format(page + 1)
with open(dirpath + 'list.html') as f:
text = ''.join(f.readlines())
selector = etree.HTML(text)
booklist = selector.xpath('//ul[@class="bang_list clearfix bang_list_mode"]/li')
book = [book for book in booklist]
for i in range(len(book)):
with open(dirpath + '{}.html'.format(i + 1)) as df: # 開啟儲存書籍的詳細頁面
d_text = ''.join(df.readlines())
d_selector = etree.HTML(d_text)
# text()是選出<a>xxx</a>中間的值,而@href 是選出href屬性的值
rank = book[i].xpath('div[1]/text()')[0] # 排名
site = book[i].xpath('div[2]/a/@href')[0] # 購買/詳細頁面
name = book[i].xpath('div[3]/a/text()')[0] # 名字
star = book[i].xpath('div[4]/span/span/@style') # 以星星寬度決定好評
author = book[i].xpath('div[5]/a/text()') # 作者名
ISBN = d_selector.xpath('//ul[@class="key clearfix"]/li[5]/text()')[0] # 從詳細頁面中獲取isbn
# 資料的規格化,這裡為了方便修改,分開未修改和已修改兩部分
rank = rank.replace('.', '')
site = site
name = name
star = ''.join([x for x in star[0] if x.isdigit() or x == '.'])
author = ' '.join(author)
ISBN = ISBN.replace('國際標準書號ISBN:', '') + '\t' #去除在Excel中科學計數法的影響
print(rank, name, author, star, site, ISBN)
writer.writerow((rank, name, author, star, site, ISBN)) # 儲存到csv
不多贅述,有興趣可以copy下來慢慢玩,最好就是開啟暢銷書的網頁,然後對照審查元素慢慢研究lxml. 另外要注意的細節都以註釋形式儲存了.
寫在最後
爬蟲挺好玩的,所有的原始碼,離線網頁和輸出的csv檔案都放在網盤裡面了.
百度網盤
這裡了,感興趣就點選下載多多支援吧~
最終感謝沒有限制我讓我爬這麼多網頁的噹噹網的大力支援.
感謝提出要爬這個榜單資料用於工作的朱老闆.