
爬取珍愛網後用戶資訊展示
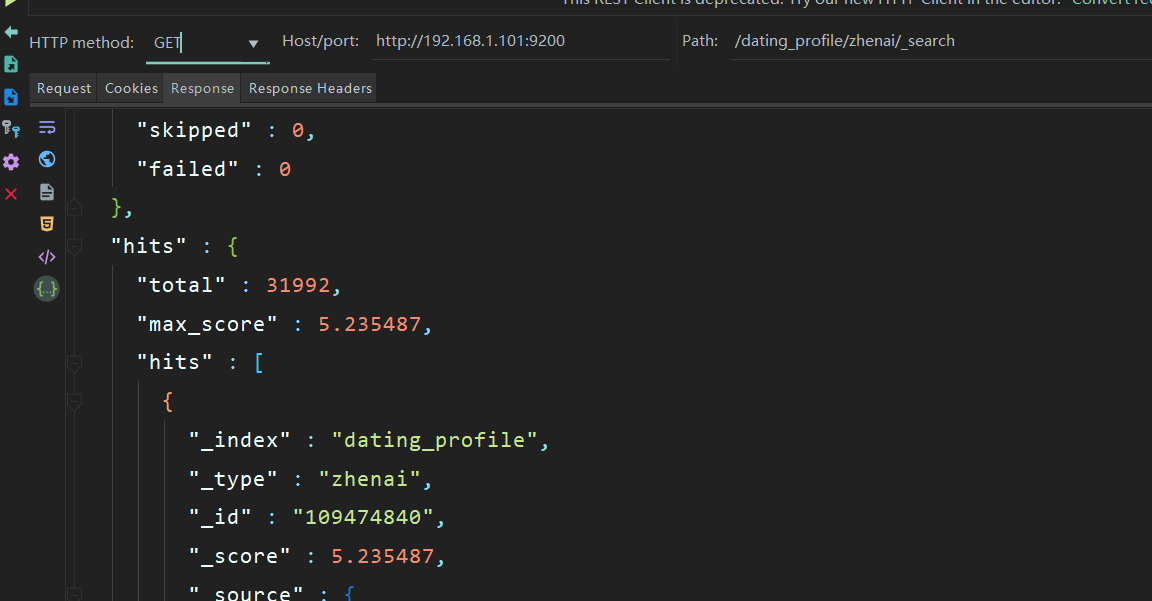
golang爬取珍愛網,爬到了3萬多使用者資訊,並存到了elasticsearch中,如下圖,查詢到了3萬多使用者資訊。
先來看看最終效果:
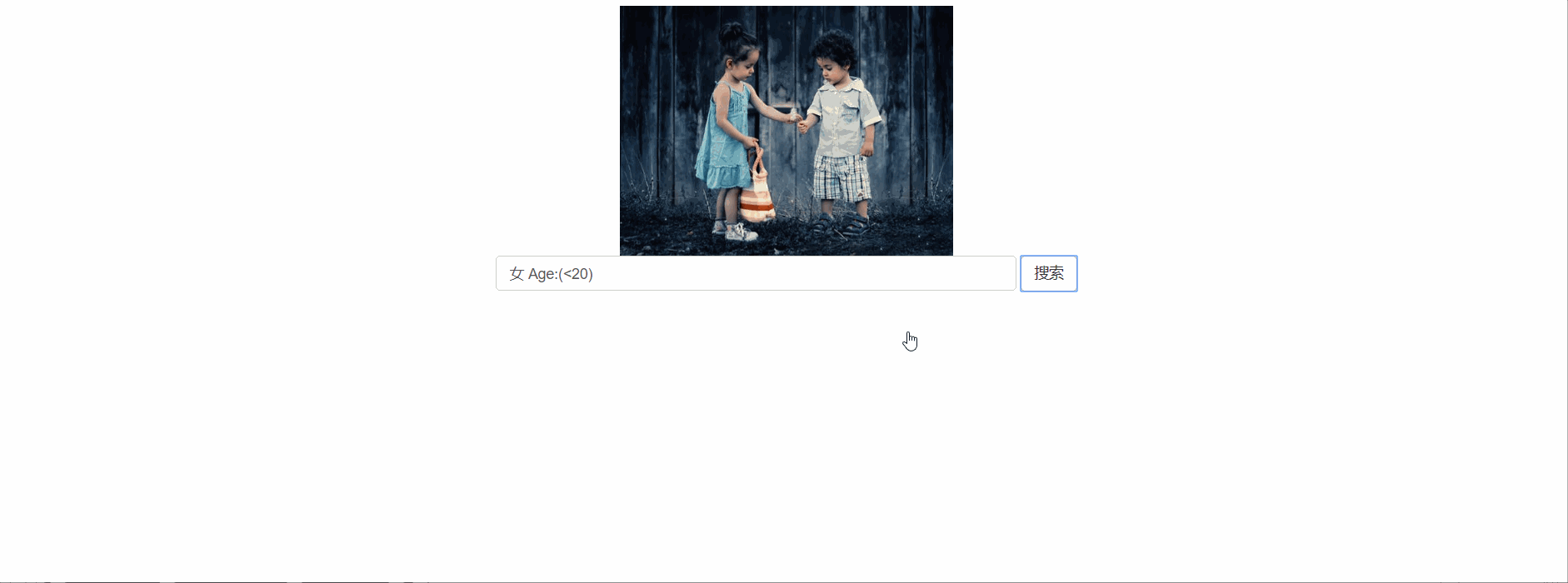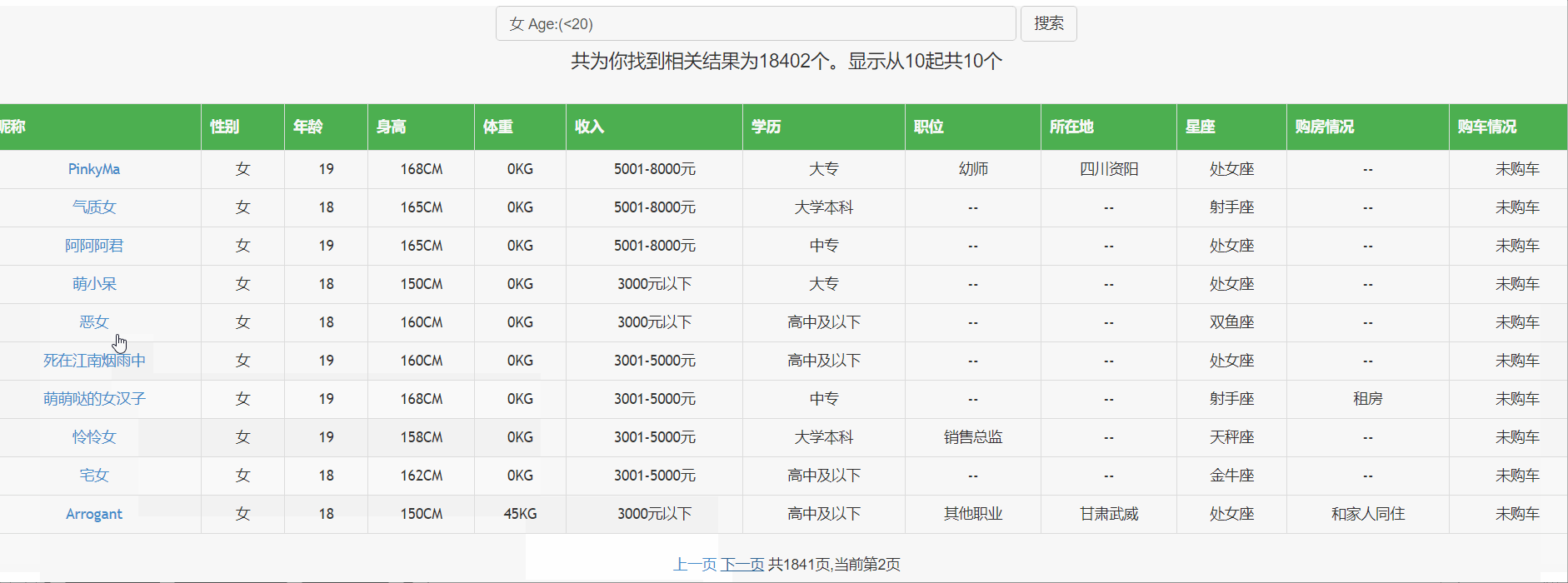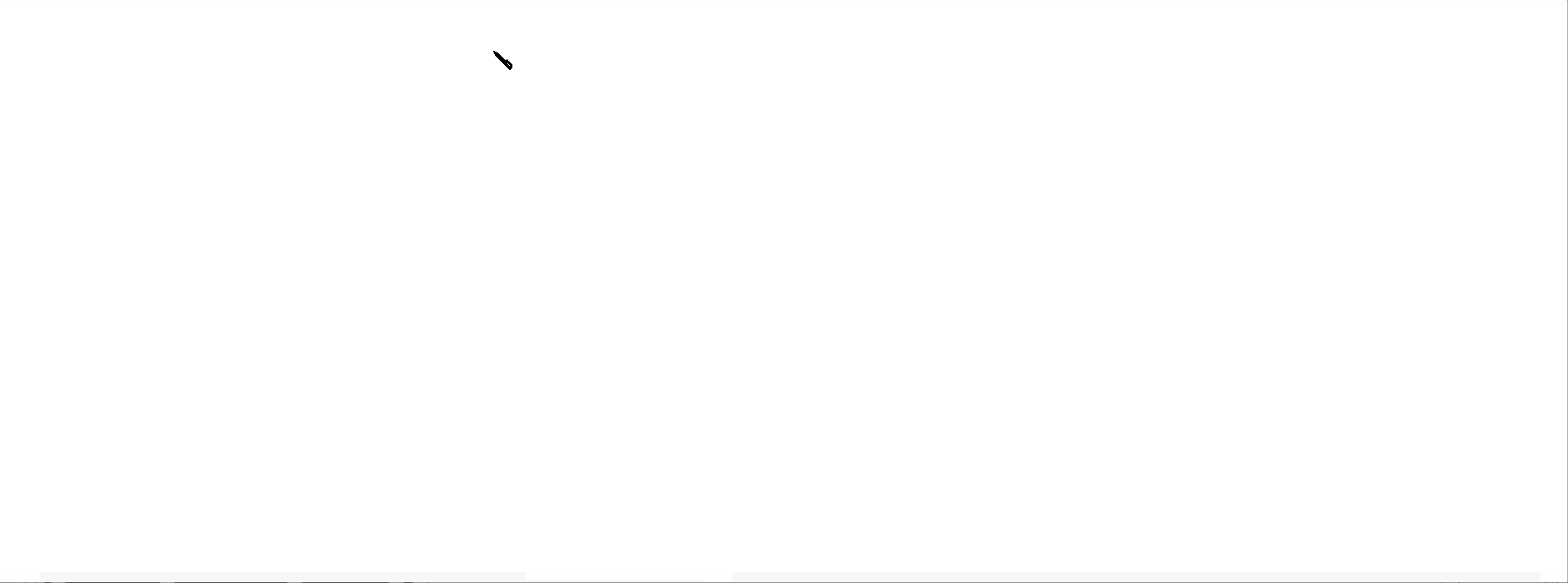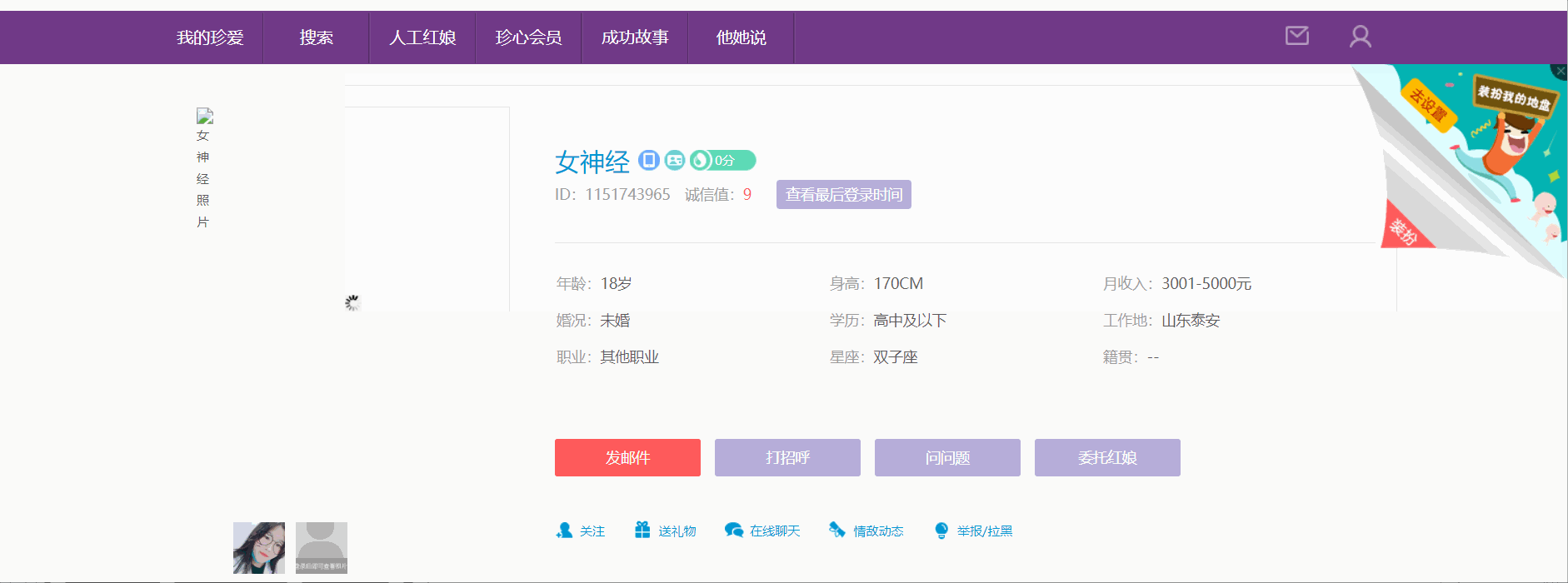
利用到了go語言的html模板庫:
執行模板渲染:
func (s SearchResultView) Render (w io.Writer, data model.SearchResult) error {
return s.template.Execute(w, data)
}model.SearchResult資料結構如下:
type SearchResult struct { Hits int64 Start int Query string PrevFrom int NextFrom int CurrentPage int TotalPage int64 Items []interface{} //Items []engine.Item }
html模板如下:html
<!DOCTYPE html>
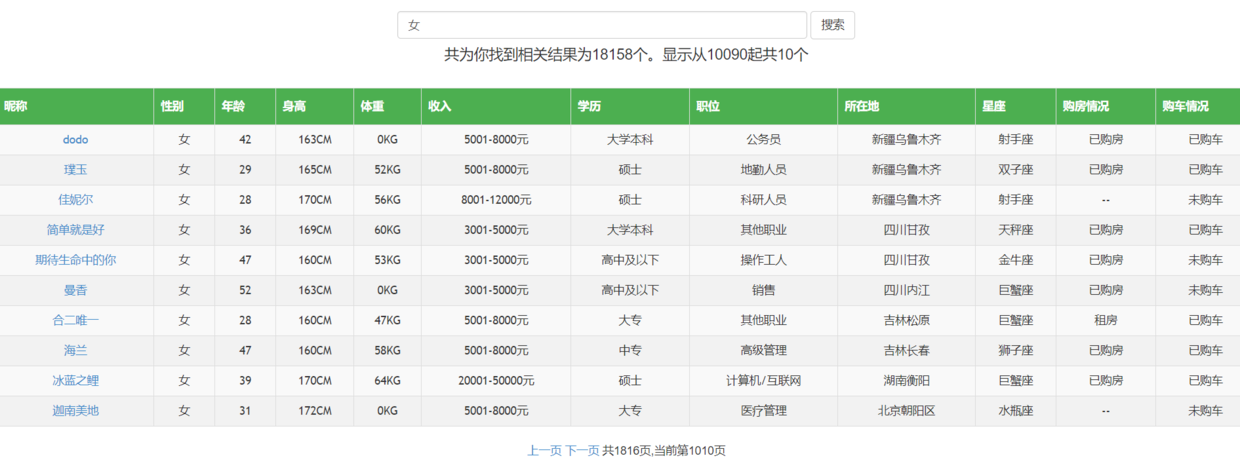
共為你找到相關結果為{{.Hits}}個。顯示從{{.Start}}起共{{len .Items}}個
| 暱稱 | 性別 | 年齡 | 身高 | 體重 | 收入 | 學歷 | 職位 | 所在地 | 星座 | 購房情況 | 購車情況 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| {{.Payload.Name}} | {{with .Payload}}{{.Gender}} | {{.Age}} | {{.Height}}CM | {{.Weight}}KG | {{.Income}} | {{.Education}} | {{.Occupation}} | {{.Hukou}} | {{.Xinzuo}} | {{.House}} | {{.Car}} | {{end}}
| 沒有找到相關使用者 | |||||||||||
```
其中用到了模板語法中的變數、函式、判斷、迴圈;
模板函式的定義:
上面模板程式碼中的上一頁、下一頁的a標籤href裡用到了自定義模板函式Add和Sub分別用於獲取上一頁和下一頁的頁碼,傳到後臺(這裡並沒有用JavaScript去實現)。
html/template包中提供的功能有限,所以很多時候需要使用使用者定義的函式來輔助渲染頁面。下面講講模板函式如何使用。template包建立新的模板的時候,支援.Funcs方法來將自定義的函式集合匯入到該模板中,後續通過該模板渲染的檔案均支援直接呼叫這些函式。
函式宣告
// Funcs adds the elements of the argument map to the template's function map.
// It panics if a value in the map is not a function with appropriate return
// type. However, it is legal to overwrite elements of the map. The return
// value is the template, so calls can be chained.
func (t *Template) Funcs(funcMap FuncMap) *Template {
t.text.Funcs(template.FuncMap(funcMap))
return t
}Funcs方法就是用來建立我們模板函數了,它需要一個FuncMap型別的引數:
// FuncMap is the type of the map defining the mapping from names to
// functions. Each function must have either a single return value, or two
// return values of which the second has type error. In that case, if the
// second (error) argument evaluates to non-nil during execution, execution
// terminates and Execute returns that error. FuncMap has the same base type
// as FuncMap in "text/template", copied here so clients need not import
// "text/template".
type FuncMap map[string]interface{}使用方法:
在go程式碼中定義兩個函式Add和Sub:
//減法,為了在模板裡用減1
func Sub(a, b int) int {
return a - b
}
//加法,為了在模板裡用加1
func Add(a, b int) int {
return a + b
}模板繫結模板函式:
建立一個FuncMap型別的map,key是模板函式的名字,value是剛才定義函式名。
將 FuncMap注入到模板中。
filename := "../view/template_test.html"
template, err := template.New(path.Base(filename)).Funcs(template.FuncMap{"Add": Add, "Sub": Sub}).ParseFiles(filename)
if err != nil {
t.Fatal(err)
}模板中如何使用:
如上面html模板中上一頁處的:
{{Sub .CurrentPage 1}}把渲染後的CurrentPage值加1
注意:
1、函式的注入,必須要在parseFiles之前,因為解析模板的時候,需要先把函式編譯註入。
2、Template object can have multiple templates in it and each one has a name. If you look at the implementation of ParseFiles, you see that it uses the filename as the template name inside of the template object. So, name your file the same as the template object, (probably not generally practical) or else use ExecuteTemplate instead of just Execute.
3、The name of the template is the bare filename of the template, not the complete path。如果模板名字寫錯了,執行的時候會出現:
error: template: “…” is an incomplete or empty template尤其是第三點,我今天就遇到了,模板名要用檔名,不能是帶路徑的名字,看以下程式碼:
func TestTemplate3(t *testing.T) {
//filename := "crawler/frontend/view/template.html"
filename := "../view/template_test.html"
//file, _ := os.Open(filename)
t.Logf("baseName:%s\n", path.Base(filename))
tpl, err := template.New(filename).Funcs(template.FuncMap{"Add": Add, "Sub": Sub}).ParseFiles(filename)
if err != nil {
t.Fatal(err)
}
page := common.SearchResult{}
page.Hits = 123
page.Start = 0
item := engine.Item {
Url: "http://album.zhenai.com/u/107194488",
Type: "zhenai",
Id: "107194488",
Payload: model.Profile{
Name: "霓裳",
Age: 28,
Height: 157,
Marriage: "未婚",
Income: "5001-8000元",
Education: "中專",
Occupation: "程式媛",
Gender: "女",
House: "已購房",
Car: "已購車",
Hukou: "上海徐彙區",
Xinzuo: "水瓶座",
},
}
page.CurrentPage = 1
page.TotalPage = 10
page.Items = append(page.Items, item)
afterHtml, err := os.Create("template_test1.html")
if err != nil {
t.Fatal(err)
}
tpl.Execute(afterHtml, page)
}
這裡在template.New(filename)傳入的是檔名(上面定義時是帶路徑的檔名),導致執行完程式碼後template_test1.html檔案是空的,當然測試類的通過的,但是將此渲染到瀏覽器的時候,就會報:
template: “…” is an incomplete or empty template所以,要使用檔案的baseName,即:
tpl, err := template.New(path.Base(filename)).Funcs(template.FuncMap{"Add": Add, "Sub": Sub}).ParseFiles(filename)這樣執行程式碼後template_test1.html就是被渲染有內容的。
其他語法:變數、判斷、迴圈用法比較簡單,我沒遇到問題;其他語法,如:模板的巢狀,我目前沒用到,在此也不做贅述。
查詢遇到的問題:
因為查詢每頁顯示10條記錄,查詢第1000頁是正常的,當查詢大於等於1001頁的時候,會報如下錯誤:
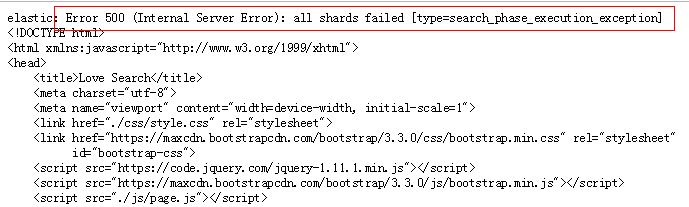
用restclient工具調,錯誤更明顯了:
{
"error" : {
"root_cause" : [
{
"type" : "query_phase_execution_exception",
"reason" : "Result window is too large, from + size must be less than or equal to: [10000] but was [10010]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
],
"type" : "search_phase_execution_exception",
"reason" : "all shards failed",
"phase" : "query",
"grouped" : true,
"failed_shards" : [
{
"shard" : 0,
"index" : "dating_profile",
"node" : "bJhldvT6QeaRTvHmBKHT4Q",
"reason" : {
"type" : "query_phase_execution_exception",
"reason" : "Result window is too large, from + size must be less than or equal to: [10000] but was [10010]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
}
]
},
"status" : 500
}
問了谷哥後發現,是由於ElasticSearch的預設 深度翻頁 機制的限制造成的。ES預設的分頁機制一個不足的地方是,比如有5010條資料,當你僅想取第5000到5010條資料的時候,ES也會將前5000條資料載入到記憶體當中,所以ES為了避免使用者的過大分頁請求造成ES服務所在機器記憶體溢位,預設對深度分頁的條數進行了限制,預設的最大條數是10000條,這是正是問題描述中當獲取第10000條資料的時候報Result window is too large異常的原因。(因為頁面為1001頁的時候後臺1001-1然後乘以10作為from的值取查詢ES,而ES預設需要from+size要小於index.max_result_window: 最大視窗值)。
要解決這個問題,可以使用下面的方式來改變ES預設深度分頁的index.max_result_window 最大視窗值
curl -XPUT http://127.0.0.1:9200/dating_profile/_settings -d '{ "index" : { "max_result_window" : 50000}}'這裡的dating_profile為index。
其中my_index為要修改的index名,50000為要調整的新的視窗數。將該視窗調整後,便可以解決無法獲取到10000條後資料的問題。
注意事項
通過上述的方式解決了我們的問題,但也引入了另一個需要我們注意的問題,視窗值調大了後,雖然請求到分頁的資料條數更多了,但它是用犧牲更多的伺服器的記憶體、CPU資源來換取的。要考慮業務場景中過大的分頁請求,是否會造成叢集服務的OutOfMemory問題。在ES的官方文件中對深度分頁也做了討論
https://www.elastic.co/guide/en/elasticsearch/guide/current/pagination.html
https://www.elastic.co/guide/en/elasticsearch/guide/current/pagination.html
核心的觀點如下:
Depending on the size of your documents, the number of shards, and the hardware you are using, paging 10,000 to 50,000 results (1,000 to 5,000 pages) deep should be perfectly doable. But with big-enough from values, the sorting process can become very heavy indeed, using vast amounts of CPU, memory, and bandwidth. For this reason, we strongly advise against deep paging.
這段觀點表述的意思是:根據文件的大小,分片的數量以及使用的硬體,分頁10,000到50,000個結果(1,000到5,000頁)應該是完全可行的。 但是,從價值觀上來看,使用大量的CPU,記憶體和頻寬,分類過程確實會變得非常重要。 為此,我們強烈建議不要進行深度分頁。
ES作為一個搜尋引擎,更適合的場景是使用它進行搜尋,而不是大規模的結果遍歷。 大部分場景下,沒有必要得到超過10000個結果專案, 例如,只返回前1000個結果。如果的確需要大量資料的遍歷展示,考慮是否可以用其他更合適的儲存。或者根據業務場景看能否用ElasticSearch的 滾動API (類似於迭代器,但有時間視窗概念)來替代。
到此展示的問題就解決了:
專案程式碼見:https://github.com/ll837448792/crawler
本公眾號免費提供csdn下載服務,海量IT學習資源,如果你準備入IT坑,勵志成為優秀的程式猿,那麼這些資源很適合你,包括但不限於java、go、python、springcloud、elk、嵌入式 、大資料、面試資料、前端 等資源。同時我們組建了一個技術交流群,裡面有很多大佬,會不定時分享技術文章,如果你想來一起學習提高,可以公眾號後臺回覆【2】,免費邀請加技術交流群互相學習提高,會不定期分享程式設計IT相關資源。
掃碼關注,精彩內容第一時間推給你

相關推薦
爬取珍愛網後用戶資訊展示
golang爬取珍愛網,爬到了3萬多使用者資訊,並存到了elasticsearch中,如下圖,查詢到了3萬多使用者資訊。 先來看看最終效果: 利用到了go語言的html模板庫: 執行模板渲染: func (s SearchResultView) Render (w io.Writer, data mo
用go語言爬取珍愛網 | 第一回
我們來用go語言爬取“珍愛網”使用者資訊。 首先分析到請求url為: http://www.zhenai.com/zhenghun 接下來用go請求該url,程式碼如下: package main import ( "fmt" "io/ioutil" &
用go語言爬取珍愛網 | 第二回
昨天我們一起爬取珍愛網首頁,拿到了城市列表頁面,接下來在返回體城市列表中提取城市和url,即下圖中的a標籤裡的href的值和innerText值。 提取a標籤,可以通過CSS選擇器來選擇,如下: $('#cityList>dd>a');就可以獲取到470個a標籤: 這裡只提供一個思
用go語言爬取珍愛網 | 第三回
前兩節我們獲取到了城市的URL和城市名,今天我們來解析使用者資訊。 用go語言爬取珍愛網 | 第一回 用go語言爬取珍愛網 | 第二回 爬蟲的演算法: 我們要提取返回體中的城市列表,需要用到城市列表解析器; 需要把每個城市裡的所有使用者解析出來,需要用到城市解析器; 還需要把每個使用者的個人資訊解析出來,
Python爬蟲從入門到放棄(十八)之 Scrapy爬取所有知乎用戶信息(上)
user 說過 -c convert 方式 bsp 配置文件 https 爬蟲 爬取的思路 首先我們應該找到一個賬號,這個賬號被關註的人和關註的人都相對比較多的,就是下圖中金字塔頂端的人,然後通過爬取這個賬號的信息後,再爬取他關註的人和被關註的人的賬號信息,然後爬取被關註人
用scrapy框架爬取映客直播用戶頭像
xpath print main back int open for pri nbsp 1. 創建項目 scrapy startproject yingke cd yingke 2. 創建爬蟲 scrapy genspider live 3. 分析http://www.i
爬取任意兩個用戶在豆瓣上標記的想讀的圖書
ID IT pan com 長度 ide urllib http 數據 爬蟲的步驟:將要爬取的目標用戶想讀的圖書的首頁的url存儲在元組中。通過urllib.request方法構造一個發送請求,在通過urllib.urlopen方法發出請求並取得響應(response)。通
如何爬取了知乎用戶信息,並做了簡單的分析
gem 話題 top href pycha 抓取 一定的 chat 綠色 爬蟲:python27 +requests+json+bs4+time 分析工具: ELK套件 開發工具:pycharm 1.性別分布 0 綠色代表的是男性 ^ . ^ 1 代表的是女性 -1
python之爬蟲的入門05------實戰:爬取貝殼網(用re匹配需要的資料)
# 第二頁:https://hz.zu.ke.com/zufang/pg2 # 第一頁:https://hz.zu.ke.com/zufang/pg1 import urllib.request import random import re def user_ip(): ''
NC65:WebService釋出服務(登陸後用戶資訊的校驗)以及如何製作補丁
NC65:WebService釋出服務(登陸後用戶資訊的校驗) 1、NC65為什麼要WebService? 在這裡我簡單跟大家談談自己的理解,WebService建立的服務,可以由不同的系統之間進行呼叫。例如其它的業務系統釋出了某項服務,NC系統可以對該服務進行呼叫。 (開發人員可以
(55)-- 簡單爬取人人網個人首頁資訊
# 簡單爬取人人網個人首頁資訊from urllib import request base_url = 'http://www.renren.com/964943656' headers = { "Host" : "www.renren.com", "Co
根據搜尋內容爬取招聘網的職位招聘資訊
程式碼:import requests from bs4 import BeautifulSoup import time def getHtml(url,code='gbk'): try: r = requests.get(url)
python 跨知乎app發私信以及Python專欄30萬用戶資訊爬取
import requests class SendMsg: def __init__(self): self.url='https://www.zhihu.com/api/v4/messages' #要傳送的資訊 self.data={'co
[Python爬蟲]爬蟲例項:線上爬取噹噹網暢銷書Top500的圖書資訊
本例項還有另外的離線爬蟲實現,有興趣可點選離線爬取噹噹網暢銷書Top500的圖書資訊 爬蟲說明 1.使用requests和Lxml庫爬取,(用BS4也很簡單,這裡是為了練習Xpath的語法) 2.爬蟲分類為兩種,一種是離線爬蟲,即先將所爬取的網頁儲存到本地,再從本
[Python爬蟲]爬蟲例項:離線爬取噹噹網暢銷書Top500的圖書資訊
本例項還有另外的線上爬蟲實現,有興趣可點選線上爬取噹噹網暢銷書Top500的圖書資訊 爬蟲說明 1.使用requests和Lxml庫爬取,(用BS4也很簡單,這裡是為了練習Xpath的語法) 2.爬蟲分類為兩種,一種是線上爬蟲,即在網站中一邊開啟網頁一邊進行爬取;第
利用xpath爬取招聘網的招聘資訊
爬取招聘網的招聘資訊: import json import random import time import pymongo import re import pandas as pd import requests from lxml import etree impor
利用BeautifulSoup和Xpath爬取趕集網北京二手房房價資訊
利用BeautifulSoup和Xpath爬取趕集網北京二手房房價資訊 文章開始把我喜歡的這句話送個大家:這個世界上還有什麼比自己寫的程式碼執行在一億人的電腦上更酷的事情嗎,如果有那就是讓這個數字再擴大十倍! 1.BeautifulSoup實現 #!/usr/
Python 爬蟲第三步 -- 多執行緒爬蟲爬取噹噹網書籍資訊
XPath 的安裝以及使用 1 . XPath 的介紹 剛學過正則表示式,用的正順手,現在就把正則表示式替換掉,使用 XPath,有人表示這太坑爹了,早知道剛上來就學習 XPath 多省事 啊。其實我個人認為學習一下正則表示式是大有益處的,之所以換成 XPa
python爬蟲——爬取知網體育學刊引證論文資訊
前言 國慶百無聊賴,然後幫一個小姐姐爬取知網資訊,覺得知網算目前處理過的對爬蟲稍微有點防範的網站,遂有了這篇部落格 目標 爬取知網上2003年體育學刊文獻所有論文的引證論文,包括論文名稱、作者、發表時間,也就是下面紅框所指處 點選click處,點選黑框,紅框所
Python爬蟲專案--爬取自如網房源資訊
本次爬取自如網房源資訊所用到的知識點: 1. requests get請求 2. lxml解析html 3. Xpath 4. MongoDB儲存 正文 1.分析目標站點 1. url: http://hz.ziroom.com/z/nl/z3.html?p=2