
Android 建立與解析XML(五)—— Dom4j方式
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
1、Dom4j概述
dom4j is an easy to use, open source library for working with XML, XPath and XSLT on the Java platform using the Java Collections Framework and with full support for DOM, SAX and JAXP.
dom4j官方網址:dom4j
dom4j原始碼下載:dom4j download
本示例中,需要匯入dom4j.jar包,才能引用dom4j相關類,dom4j原始碼和jar包,請見本示例【原始碼下載】或訪問 dom4j
org.dom4j包,不僅包含建立xml的構建器類DocumentHelper、Element,而且還包含解析xml的解析器SAXReader、Element,包含類如下:
org.dom4j
org.dom4j.DocumentHelper;
org.dom4j.Element;
org.dom4j.io.SAXReader;
org.dom4j.io.XMLWriter;
org.dom4j.DocumentException;
sdk原始碼檢視路徑(google code)
建立和解析xml的效果圖:
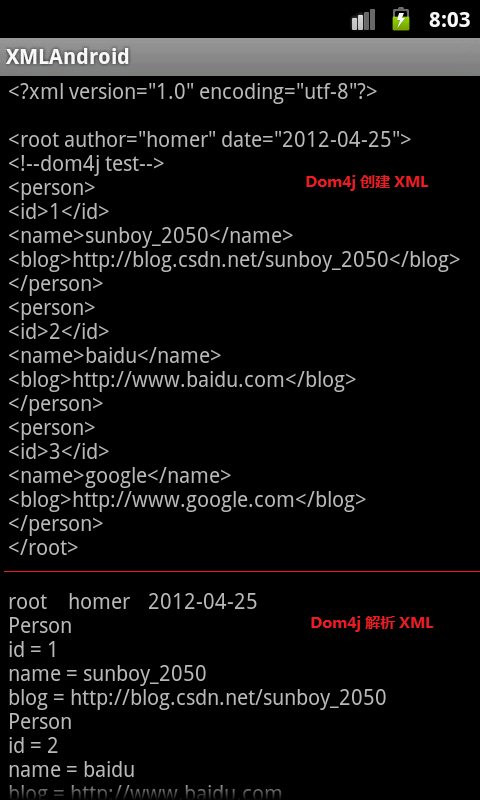
2、Dom4j 建立 XML
Dom4j,建立xml主要用到了org.dom4j.DocumentHelper、org.dom4j.Document、org.dom4j.io.OutputFormat、org.dom4j.io.XMLWriter
首先,DocumentHelper.createDocument(),建立 org.dom4j.Document 的例項 doc
接著,通過doc,設定xml屬性doc.setXMLEncoding("utf-8")、doc.addElement("root")根節點,以及子節點等
然後,定義xml格式並輸出,new XMLWriter(xmlWriter, outputFormat)
Code
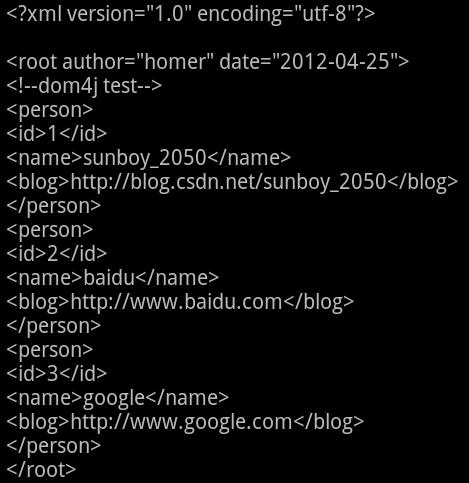
/** Dom4j方式,建立 XML */ public String dom4jXMLCreate(){ StringWriter xmlWriter = new StringWriter(); Person []persons = new Person[3]; // 建立節點Person物件 persons[0] = new Person(1, "sunboy_2050", "http://blog.csdn.net/sunboy_2050"); persons[1] = new Person(2, "baidu", "http://www.baidu.com"); persons[2] = new Person(3, "google", "http://www.google.com"); try { org.dom4j.Document doc = DocumentHelper.createDocument(); doc.setXMLEncoding("utf-8"); org.dom4j.Element eleRoot = doc.addElement("root"); eleRoot.addAttribute("author", "homer"); eleRoot.addAttribute("date", "2012-04-25"); eleRoot.addComment("dom4j test"); int personsLen = persons.length; for(int i=0; i<personsLen; i++){ Element elePerson = eleRoot.addElement("person"); // 建立person節點,引用類為 org.dom4j.Element Element eleId = elePerson.addElement("id"); eleId.addText(persons[i].getId()+""); Element eleName = elePerson.addElement("name"); eleName.addText(persons[i].getName()); Element eleBlog = elePerson.addElement("blog"); eleBlog.addText(persons[i].getBlog()); } org.dom4j.io.OutputFormat outputFormat = new org.dom4j.io.OutputFormat(); // 設定xml輸出格式 outputFormat.setEncoding("utf-8"); outputFormat.setIndent(false); outputFormat.setNewlines(true); outputFormat.setTrimText(true); org.dom4j.io.XMLWriter output = new XMLWriter(xmlWriter, outputFormat); // 儲存xml output.write(doc); output.close(); } catch (Exception e) { e.printStackTrace(); } savedXML(fileName, xmlWriter.toString()); return xmlWriter.toString(); }執行結果:
3、Dom4j 解析 XML
Dom4j,解析xml主要用到了org.dom4j.io.SAXReader、org.dom4j.Document、doc.getRootElement(),以及ele.getName()、ele.getText()等
首先,建立SAXReader的例項reader,讀入xml位元組流 reader.read(is)
接著,通過doc.getRootElement()得到root根節點,利用迭代器取得root下一級的子節點eleRoot.elementIterator()等
然後,得到解析的xml內容xmlWriter.append(xmlHeader)、xmlWriter.append(personsList.get(i).toString())
解析一:標準解析(Iterator 迭代)
Code
/** Dom4j方式,解析 XML */ public String dom4jXMLResolve(){ StringWriter xmlWriter = new StringWriter(); InputStream is = readXML(fileName); try { SAXReader reader = new SAXReader(); org.dom4j.Document doc = reader.read(is); List<Person> personsList = null; Person person = null; StringBuffer xmlHeader = new StringBuffer(); Element eleRoot = doc.getRootElement(); // 獲得root根節點,引用類為 org.dom4j.Element String attrAuthor = eleRoot.attributeValue("author"); String attrDate = eleRoot.attributeValue("date"); xmlHeader.append("root").append("\t\t"); xmlHeader.append(attrAuthor).append("\t"); xmlHeader.append(attrDate).append("\n"); personsList = new ArrayList<Person>(); // 獲取root子節點,即person Iterator<Element> iter = eleRoot.elementIterator(); for(; iter.hasNext(); ) { Element elePerson = (Element)iter.next(); if("person".equals(elePerson.getName())){ person = new Person(); // 獲取person子節點,即id、name、blog Iterator<Element> innerIter = elePerson.elementIterator(); for(; innerIter.hasNext();) { Element ele = (Element)innerIter.next(); if("id".equals(ele.getName())) { String id = ele.getText(); person.setId(Integer.parseInt(id)); } else if("name".equals(ele.getName())) { String name = ele.getText(); person.setName(name); } else if("blog".equals(ele.getName())) { String blog = ele.getText(); person.setBlog(blog); } } personsList.add(person); person = null; } } xmlWriter.append(xmlHeader); int personsLen = personsList.size(); for(int i=0; i<personsLen; i++) { xmlWriter.append(personsList.get(i).toString()); } } catch (DocumentException e) { e.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } return xmlWriter.toString(); }執行結果:

解析二:選擇性解析(XPath路徑)
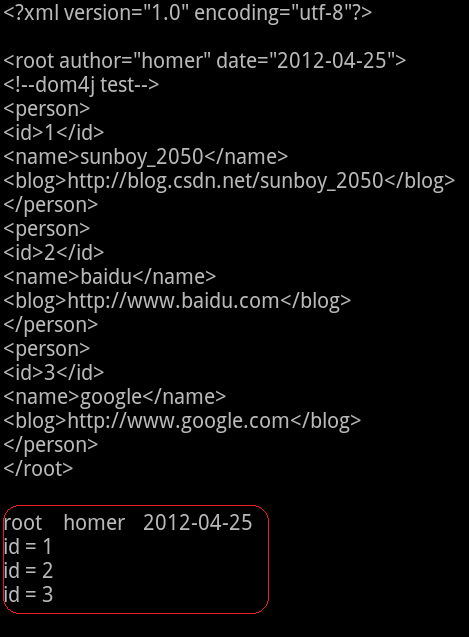
Dom4j+XPath,選擇性只解析id,doc.selectNodes("//root//person//id")
Code
/** Dom4j方式,解析 XML(方式二) */ public String dom4jXMLResolve2(){ StringWriter xmlWriter = new StringWriter(); InputStream is = readXML(fileName); try { org.dom4j.io.SAXReader reader = new org.dom4j.io.SAXReader(); org.dom4j.Document doc = reader.read(is); List<Person> personsList = null; Person person = null; StringBuffer xmlHeader = new StringBuffer(); Element eleRoot = doc.getRootElement(); // 獲得root根節點,引用類為 org.dom4j.Element String attrAuthor = eleRoot.attributeValue("author"); String attrDate = eleRoot.attributeValue("date"); xmlHeader.append("root").append("\t\t"); xmlHeader.append(attrAuthor).append("\t"); xmlHeader.append(attrDate).append("\n"); personsList = new ArrayList<Person>(); @SuppressWarnings("unchecked") List<Element> idList = (List<Element>) doc.selectNodes("//root//person//id"); // 選擇性獲取全部id Iterator<Element> idIter = idList.iterator(); while(idIter.hasNext()){ person = new Person(); Element idEle = (Element)idIter.next(); String id = idEle.getText(); person.setId(Integer.parseInt(id)); personsList.add(person); } xmlWriter.append(xmlHeader); int personsLen = personsList.size(); for(int i=0; i<personsLen; i++) { xmlWriter.append("id = ").append(personsList.get(i).getId()+"").append("\n"); } } catch (DocumentException e) { e.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } return xmlWriter.toString(); }注:藉助 XPath 解析 XML 時,需要匯入 jaxen;本示例需要匯入的是最新的jaxen包jaxen-1.1.3.jar,可以下載本示例下面【原始碼下載】或 訪問 jaxen jar
Jaxen is an open source XPath library written in Java. It is adaptable to many different object models, including DOM, XOM, dom4j, and JDOM. Is it also possible to write adapters that treat non-XML trees such as compiled Java byte code or Java beans as XML, thus enabling you to query these trees with XPath too.
jaxen 官方網址:jaxen
jaxen下載jar包:jaxen jar 或 jaxen jar
jaxen原始碼檢視:jaxen src 或 jaxen trunk
執行結果:
4、Person類
請參見前面部落格 Android 建立與解析XML(二)—— Dom方式 【4、Person類】
參考推薦:
dom4j(官方網站)
dom4j src(原始碼下載)
dom4j src and jar(google code)
jaxen(jaxen 官方網址)
jaxen jar(jaxen jar包下載)
jaxen src(jaxen線上原始碼)
dom4j 解析 XML(IBM)
給我老師的人工智慧教程打call!http://blog.csdn.net/jiangjunshow
 你好! 這是你第一次使用 **Markdown編輯器** 所展示的歡迎頁。如果你想學習如何使用Markdown編輯器, 可以仔細閱讀這篇文章,瞭解一下Markdown的基本語法知識。
你好! 這是你第一次使用 **Markdown編輯器** 所展示的歡迎頁。如果你想學習如何使用Markdown編輯器, 可以仔細閱讀這篇文章,瞭解一下Markdown的基本語法知識。
新的改變
我們對Markdown編輯器進行了一些功能拓展與語法支援,除了標準的Markdown編輯器功能,我們增加了如下幾點新功能,幫助你用它寫部落格:
- 全新的介面設計 ,將會帶來全新的寫作體驗;
- 在創作中心設定你喜愛的程式碼高亮樣式,Markdown 將程式碼片顯示選擇的高亮樣式 進行展示;
- 增加了 圖片拖拽 功能,你可以將本地的圖片直接拖拽到編輯區域直接展示;
- 全新的 KaTeX數學公式 語法;
- 增加了支援甘特圖的mermaid語法1 功能;
- 增加了 多螢幕編輯 Markdown文章功能;
- 增加了 焦點寫作模式、預覽模式、簡潔寫作模式、左右區域同步滾輪設定 等功能,功能按鈕位於編輯區域與預覽區域中間;
- 增加了 檢查列表 功能。
功能快捷鍵
撤銷:Ctrl/Command + Z
重做:Ctrl/Command + Y
加粗:Ctrl/Command + B
斜體:Ctrl/Command + I
標題:Ctrl/Command + Shift + H
無序列表:Ctrl/Command + Shift + U
有序列表:Ctrl/Command + Shift + O
檢查列表:Ctrl/Command + Shift + C
插入程式碼:Ctrl/Command + Shift + K
插入連結:Ctrl/Command + Shift + L
插入圖片:Ctrl/Command + Shift + G
合理的建立標題,有助於目錄的生成
直接輸入1次#,並按下space後,將生成1級標題。
輸入2次#,並按下space後,將生成2級標題。
以此類推,我們支援6級標題。有助於使用TOC語法後生成一個完美的目錄。
如何改變文字的樣式
強調文字 強調文字
加粗文字 加粗文字
標記文字
刪除文字
引用文字
H2O is是液體。
210 運算結果是 1024.
插入連結與圖片
連結: link.
圖片: 
帶尺寸的圖片: ![]()
當然,我們為了讓使用者更加便捷,我們增加了圖片拖拽功能。
如何插入一段漂亮的程式碼片
去部落格設定頁面,選擇一款你喜歡的程式碼片高亮樣式,下面展示同樣高亮的 程式碼片.
// An highlighted block var foo = 'bar'; 生成一個適合你的列表
- 專案
- 專案
- 專案
- 專案
- 專案1
- 專案2
- 專案3
- 計劃任務
- 完成任務
建立一個表格
一個簡單的表格是這麼建立的:
| 專案 | Value |
|---|---|
| 電腦 | $1600 |
| 手機 | $12 |
| 導管 | $1 |
設定內容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文字居中 | 第二列文字居右 | 第三列文字居左 |
SmartyPants
SmartyPants將ASCII標點字元轉換為“智慧”印刷標點HTML實體。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' |
‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" |
“Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash |
– is en-dash, — is em-dash |
建立一個自定義列表
- Markdown
- Text-to- HTML conversion tool
- Authors
- John
- Luke
如何建立一個註腳
一個具有註腳的文字。2
註釋也是必不可少的
Markdown將文字轉換為 HTML。
KaTeX數學公式
您可以使用渲染LaTeX數學表示式 KaTeX:
Gamma公式展示 是通過尤拉積分
你可以找到更多關於的資訊 LaTeX 數學表示式here.
新的甘特圖功能,豐富你的文章
gantt
dateFormat YYYY-MM-DD
title Adding GANTT diagram functionality to mermaid
section 現有任務
已完成 :done, des1, 2014-01-06,2014-01-08
進行中 :active, des2, 2014-01-09, 3d
計劃一 : des3, after des2, 5d
計劃二 : des4, after des3, 5d
- 關於 甘特圖 語法,參考 這兒,
UML 圖表
可以使用UML圖表進行渲染。 Mermaid. 例如下面產生的一個序列圖::
這將產生一個流程圖。:
- 關於 Mermaid 語法,參考 這兒,
FLowchart流程圖
我們依舊會支援flowchart的流程圖:
- 關於 Flowchart流程圖 語法,參考 這兒.
匯出與匯入
匯出
如果你想嘗試使用此編輯器, 你可以在此篇文章任意編輯。當你完成了一篇文章的寫作, 在上方工具欄找到 文章匯出 ,生成一個.md檔案或者.html檔案進行本地儲存。
匯入
如果你想載入一篇你寫過的.md檔案或者.html檔案,在上方工具欄可以選擇匯入功能進行對應副檔名的檔案匯入,
繼續你的創作。
註腳的解釋 ↩︎