
Hive (資料倉庫)簡介
一:什麼是Hive(資料倉庫)?
1、Hive 由 Facebook 實現並開源
2、是基於 Hadoop 的一個數據倉庫工具
3、可以將結構化的資料對映為一張資料庫表
4、並提供 HQL(Hive SQL)查詢功能
5、底層資料是儲存在 HDFS 上
6、Hive的本質是將 SQL 語句轉換為 MapReduce 任務執行
7、使不熟悉 MapReduce 的使用者很方便地利用 HQL 處理和計算 HDFS 上的結構化的資料,適用於離線的批量資料計算。
8、底層支援多種不同的執行引擎(Hive on MapReduce、Hive on Tez、Hive on Spark)支
9、持多種不同的壓縮格式、儲存格式以及自定義函式(壓縮:GZIP、LZO、Snappy、BZIP2.. ; 儲存:TextFile、SequenceFile、RCFile、ORC、Parquet ; UDF:自定義函式)
所以說 Hive 是基於 Hadoop 的一個數據倉庫工具,實質就是一款基於 HDFS 的 MapReduce 計算框架,對儲存在 HDFS 中的資料進行分析和管理
二:為什麼使用 Hive以及Hive的優點
直接使用 MapReduce 所面臨的問題:
1、人員學習成本太高
2、專案週期要求太短
3、MapReduce實現複雜查詢邏輯開發難度太大
為什麼要使用 Hive:
1、更友好的介面:操作介面採用類 SQL 的語法,提供快速開發的能力
2、更低的學習成本:避免了寫 MapReduce,減少開發人員的學習成本
3、更好的擴充套件性:可自由擴充套件叢集規模而無需重啟服務,還支援使用者自定義函式
(1)簡單容易上手:提供了類SQL查詢語言HQL
(2)可擴充套件:為超大資料集設計了計算/擴充套件能力(MR作為計算引擎,HDFS作為儲存系統)一般情
況下不需要重啟服務Hive可以自由的擴充套件叢集的規模。
(3)提供統一的元資料管理
(4)延展性:Hive支援使用者自定義函式,使用者可以根據自己的需求來實現自己的函式
三:Hive 的應用場景
Hive 的最佳使用場合是大資料集的批處理作業,例如,網路日誌分析。
(1)日誌分析:大部分網際網路公司使用hive進行日誌分析,文字分析 包括百度、淘寶等。
1)統計網站一個時間段內的pv、uv
2)多維度資料分析
(2)海量結構化資料離線分析
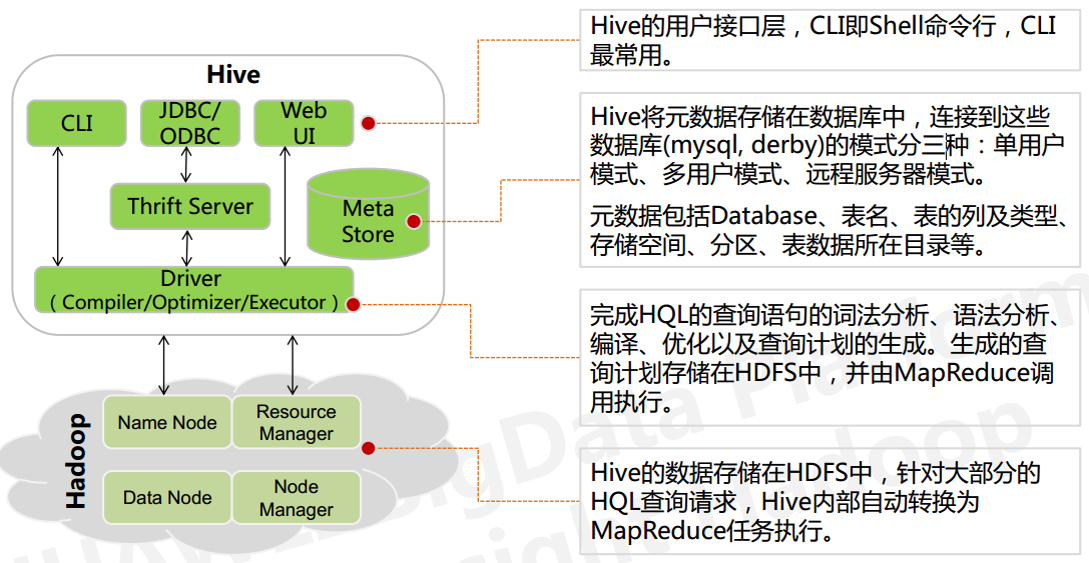

1、使用者介面: shell/CLI, jdbc/odbc, webui Command Line Interface
CLI,Shell 終端命令列(Command Line Interface),採用互動形式使用 Hive 命令列與 Hive 進行互動,最常用(學習,除錯,生產)
JDBC/ODBC,是 Hive 的基於 JDBC 操作提供的客戶端,使用者(開發員,運維人員)通過 這連線至 Hive server 服務
Web UI,通過瀏覽器訪問 Hive
2、跨語言服務 : thrift server 提供了一種能力,讓使用者可以使用多種不同的語言來操縱hive
Thrift 是 Facebook 開發的一個軟體框架,可以用來進行可擴充套件且跨語言的服務的開發, Hive 集成了該服務,能讓不同的程式語言呼叫 Hive 的介面
3、底層的Driver: 驅動器Driver,編譯器Compiler,優化器Optimizer,執行器Executor
Driver 元件完成 HQL 查詢語句從詞法分析,語法分析,編譯,優化,以及生成邏輯執行 計劃的生成。生成的邏輯執行計劃儲存在 HDFS 中,並隨後由
MapReduce 呼叫執行
Hive 的核心是驅動引擎, 驅動引擎由四部分組成:
(1) 直譯器:直譯器的作用是將 HiveSQL 語句轉換為抽象語法樹(AST)
(2) 編譯器:編譯器是將語法樹編譯為邏輯執行計劃
(3) 優化器:優化器是對邏輯執行計劃進行優化
(4) 執行器:執行器是呼叫底層的執行框架執行邏輯執行計劃
4、元資料儲存系統 : RDBMS MySQL
元資料,通俗的講,就是儲存在 Hive 中的資料的描述資訊。
Hive 中的元資料通常包括:表的名字,表的列和分割槽及其屬性,表的屬性(內部表和 外部表),表的資料所在目錄
Metastore 預設存在自帶的 Derby 資料庫中。缺點就是不適合多使用者操作,並且資料存 儲目錄不固定。資料庫跟著 Hive 走,極度不方便管理
解決方案:通常存我們自己建立的 MySQL 庫(本地 或 遠端)
Hive 和 MySQL 之間通過 MetaStore 服務互動
執行流程
HiveQL 通過命令列或者客戶端提交,經過 Compiler 編譯器,運用 MetaStore 中的元數 據進行型別檢測和語法分析,生成一個邏輯方案(Logical Plan),然後
通過的優化處理,產生 一個 MapReduce 任務。
五:Hive工作原理
1 Execute Query
Hive介面,如命令列或Web UI傳送查詢驅動程式(任何資料庫驅動程式,如JDBC,ODBC等)來執行。
2 Get Plan
在驅動程式幫助下查詢編譯器,分析查詢檢查語法和查詢計劃或查詢的要求。
3 Get Metadata
編譯器傳送元資料請求到Metastore(任何資料庫)。
4 Send Metadata
Metastore傳送元資料,以編譯器的響應。
5 Send Plan
編譯器檢查要求,並重新發送計劃給驅動程式。到此為止,查詢解析和編譯完成。
6 Execute Plan
驅動程式傳送的執行計劃到執行引擎。
7 Execute Job
在內部,執行作業的過程是一個MapReduce工作。執行引擎傳送作業給JobTracker,
在名稱節點並把它分配作業到TaskTracker,這是在資料節點。在這裡,查詢執行MapReduce工作。
7.1 Metadata Ops
與此同時,在執行時,執行引擎可以通過Metastore執行元資料操作。
8 Fetch Result
執行引擎接收來自資料節點的結果。
9 Send Results
執行引擎傳送這些結果值給驅動程式。
10 Send Results
驅動程式將結果傳送給Hive介面。
六:Hive(資料倉庫)和資料庫的異同
(1)查詢語言。由於 SQL 被廣泛的應用在資料倉庫中,因此專門針對Hive的特性設計了類SQL的查詢語言HQL。熟悉SQL開發的開發者可以很方便的使用Hive進行開發。
(2)資料儲存位置。Hive是建立在Hadoop之上的,所有Hive的資料都是儲存在HDFS中的。而資料庫則可以將資料儲存在塊裝置或者本地檔案系統中。
(3)資料格式。Hive中沒有定義專門的資料格式,資料格式可以由使用者指定,使用者定義資料格式需要指定三個屬性:列分隔符(通常為空格、”\t”、”\x001″)、行分隔符(”\n”)以及讀取檔案資料的方法(Hive中預設有三個檔案格式TextFile,SequenceFile以及RCFile)。由於在載入資料的過程中,不需要從使用者資料格式到Hive定義的資料格式的轉換,因此,
Hive在載入的過程中不會對資料本身進行任何修改,而只是將資料內容複製或者移動到相應的HDFS目錄中。
而在資料庫中,不同的資料庫有不同的儲存引擎,定義了自己的資料格式。所有資料都會按照一定的組織儲存,因此,資料庫載入資料的過程會比較耗時。
(4)資料更新。由於Hive是針對資料倉庫應用設計的,而資料倉庫的內容是讀多寫少的。因此,Hive中不支援對資料的改寫和新增,所有的資料都是在載入的時候中確定好的。而資料庫中的資料通常是需要經常進行修改的,因此可以使用INSERT INTO ... VALUES新增資料,使用UPDATE ... SET修改資料。
(5)索引。之前已經說過,Hive在載入資料的過程中不會對資料進行任何處理,甚至不會對資料進行掃描,因此也沒有對資料中的某些Key建立索引。Hive要訪問資料中滿足條件的特定值時,需要暴力掃描整個資料,因此訪問延遲較高。由於MapReduce的引入, Hive可以並行訪問資料,因此即使沒有索引,對於大資料量的訪問,Hive仍然可以體現出優勢。資料庫中,通常會針對一個或者幾個列建立索引,因此對於少量的特定條件的資料的訪問,資料庫可以有很高的效率,較低的延遲。由於資料的訪問延遲較高,決定了Hive不適合線上資料查詢。
(6)執行。Hive中大多數查詢的執行是通過Hadoop提供的MapReduce來實現的(類似select * from tbl的查詢不需要MapReduce)。而資料庫通常有自己的執行引擎。
(7)執行延遲。之前提到,Hive在查詢資料的時候,由於沒有索引,需要掃描整個表,因此延遲較高。另外一個導致Hive執行延遲高的因素是MapReduce框架。由於MapReduce本身具有較高的延遲,因此在利用MapReduce執行Hive查詢時,也會有較高的延遲。相對的,資料庫的執行延遲較低。當然,這個低是有條件的,即資料規模較小,當資料規模大到超過資料庫的處理能力的時候,Hive的平行計算顯然能體現出優勢。
(8)可擴充套件性。由於Hive是建立在Hadoop之上的,因此Hive的可擴充套件性是和Hadoop的可擴充套件性是一致的(世界上最大的Hadoop叢集在Yahoo!,2009年的規模在4000臺節點左右)。而資料庫由於ACID語義的嚴格限制,擴充套件行非常有限。目前最先進的並行資料庫Oracle在理論上的擴充套件能力也只有100臺左右。
(9)資料規模。由於Hive建立在叢集上並可以利用MapReduce進行平行計算,因此可以支援很大規模的資料;對應的,資料庫可以支援的資料規模較小。
七:Hive的資料型別及檔案格式
Hive 提供了基本資料型別和複雜資料型別
基本資料型別:
整型
TINYINT — 微整型,只佔用1個位元組,只能儲存0-255的整數。
SMALLINT– 小整型,佔用2個位元組,儲存範圍–32768 到 32767。
INT– 整型,佔用4個位元組,儲存範圍-2147483648到2147483647。
BIGINT– 長整型,佔用8個位元組,儲存範圍-2^63到2^63-1。
布林型
BOOLEAN — TRUE/FALSE
浮點型
FLOAT– 單精度浮點數。
DOUBLE– 雙精度浮點數。
字串型
STRING– 不設定長度。
複雜資料型別
Structs:一組由任意資料型別組成的結構。比如,定義一個欄位C的型別為STRUCT {a INT; b STRING},則可以使用a和C.b來獲取其中的元素值;
Maps:和Java中的Map相同,即儲存K-V對的。
Arrays:陣列。
hive的檔案格式
TEXTFILE //文字,預設值
SEQUENCEFILE // 二進位制序列檔案
RCFILE //列式儲存格式檔案 Hive0.6以後開始支援
ORC //列式儲存格式檔案,比RCFILE有更高的壓縮比和讀寫效率,Hive0.11以後開始支援
PARQUET //列出儲存格式檔案,Hive0.13以後開始支援
八: Hive的資料組織
1、Hive 的儲存結構包括資料庫、表、檢視、分割槽和表資料等。資料庫,表,分割槽等等都對 應 HDFS
上的一個目錄。表資料對應 HDFS 對應目錄下的檔案。
2、Hive 中所有的資料都儲存在 HDFS 中,沒有專門的資料儲存格式,因為 Hive 是讀模式 (Schema
On Read),可支援 TextFile,SequenceFile,RCFile 或者自定義格式等
3、 只需要在建立表的時候告訴 Hive 資料中的列分隔符和行分隔符,Hive 就可以解析資料
Hive 的預設列分隔符:控制符 Ctrl + A,\x01 Hive 的
Hive 的預設行分隔符:換行符 \n
4、Hive 中包含以下資料模型:
database:在 HDFS 中表現為${hive.metastore.warehouse.dir}目錄下一個資料夾
table:在 HDFS 中表現所屬 database 目錄下一個資料夾
external table:與 table 類似,不過其資料存放位置可以指定任意 HDFS 目錄路徑
partition:在 HDFS 中表現為 table 目錄下的子目錄
bucket:在 HDFS 中表現為同一個表目錄或者分割槽目錄下根據某個欄位的值進行 hash 散 列之後的
多個檔案
view:與傳統資料庫類似,只讀,基於基本表建立
5、Hive 的元資料儲存在 RDBMS 中,除元資料外的其它所有資料都基於 HDFS 儲存。預設情
況下,Hive 元資料儲存在內嵌的 Derby 資料庫中,只能允許一個會話連線,只適合簡單的
測試。實際生產環境中不適用,為了支援多使用者會話,則需要一個獨立的元資料庫,使用 MySQL 作
為元資料庫,Hive 內部對 MySQL 提供了很好的支援。
6、Hive 中的表分為內部表、外部表、分割槽表和 Bucket 表
內部表和外部表的區別:
刪除內部表,刪除表元資料和資料
刪除外部表,刪除元資料,不刪除資料
內部表和外部表的使用選擇:
大多數情況,他們的區別不明顯,如果資料的所有處理都在 Hive 中進行,那麼傾向於 選擇內部表,但是如果
Hive 和其他工具要針對相同的資料集進行處理,外部表更合適。
使用外部表訪問儲存在 HDFS 上的初始資料,然後通過 Hive 轉換資料並存到內部表中
使用外部表的場景是針對一個數據集有多個不同的 Schema
通過外部表和內部表的區別和使用選擇的對比可以看出來,hive 其實僅僅只是對儲存在 HDFS 上的資料提供了
一種新的抽象。而不是管理儲存在 HDFS 上的資料。所以不管建立內部 表還是外部表,都可以對 hive 表的資料存
儲目錄中的資料進行增刪操作。
分割槽表和分桶表的區別:
Hive 資料表可以根據某些欄位進行分割槽操作,細化資料管理,可以讓部分查詢更快。同 時表和分割槽也可以進
一步被劃分為 Buckets,分桶表的原理和 MapReduce 程式設計中的 HashPartitioner 的原理類似。
分割槽和分桶都是細化資料管理,但是分割槽表是手動新增區分,由於 Hive 是讀模式,所 以對新增進分割槽的資料
不做模式校驗,分桶表中的資料是按照某些分桶欄位進行 hash 雜湊 形成的多個檔案,所以資料的準確性也高很多
講了這麼多都是它的好處,那它的缺點呢?
九:Hive的缺點
1、data shuffle時網路瓶頸,Reduce要等Map結束才能開始,不能高效利用網路頻寬
2、一般一個SQL都會解析成多個MR job,Hadoop每次Job輸出都直接寫HDFS,效能差
3、每次執行Job都要啟動Task,花費很多時間,無法做到實時
4、由於把SQL轉化成MapReduce job時,map,shuffle和reduce所負責執行的SQL功能不
同。那麼就有Map->MapReduce或者MapReduce->Reduce這樣的需求。。
這樣可以降低寫HDFS的次數,從而提高效能。很明顯,由於架構上的天然涉及,Hive只適合批處理