
文字編碼解釋
一張圖解釋字符集
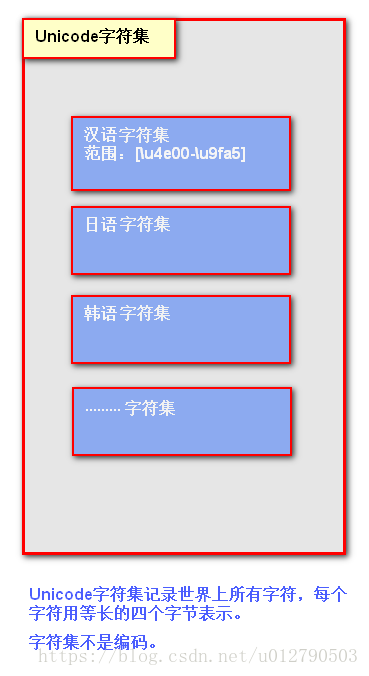
舉例說明什麼是編碼:
UTF-8編碼
等長編碼對於英文來說浪費空間,所以出現了變長編碼UTF系列,如UTF8,UTF16,UTF32。
UTF8的編碼物件是整個Unicode字符集,所以可以表示所有國家的語言而不會亂碼,所以叫“萬國碼”。所以網路傳輸文字一般使用UTF-8編碼,如網頁,這樣可以在不同的電腦上看到相同的文字而不亂碼。
GB2312編碼
但是UTF8還是對於英文來說,還是單個位元組,但是對於其他語言編碼還是多個位元組,佔用空間仍然較大。
如果只針對中文進行編碼,被編碼文字只有幾萬字,那麼會節省很多空間。常用的簡體中文編碼有GBK/GB2312,GB表示國家標準。雖然節省的儲存空間,但是前提是需要知道文字的語言是什麼。所以只在中文環境下使用。
- 完
相關推薦
文字編碼解釋
一張圖解釋字符集 舉例說明什麼是編碼: UTF-8編碼 等長編碼對於英文來說浪費空間,所以出現了變長編碼UTF系列,如UTF8,UTF16,UTF32。 UTF8的編碼物件是整個Unicode字符集,所以可以表示所有國家的語言而不會亂碼,所以叫“萬國碼”。所以網路傳輸
文字編碼和Unicode
his class blog .html 編碼 com 說明 hive html 文字編碼和Unicode 說明文字: https://blog.csdn.net/fengzhishang2019/article/details/7859064 Java 程序: https
Mac電腦使用:解決Mac上“文字編碼Unicode(UTF-8)不適用”、文字編碼“中文 (GB 18030)不適用“的問題
在Mac電腦上面開啟txt檔案,有些時候由於格式不一樣或者其他原因,會打不開txt檔案,這樣就需要我們對文字編輯的偏好設定裡面進行修改即可。這裡我只說兩種打不開的情況,這兩種情況就是標題說的這兩種情況。 一、先介紹第一種情況:未能開啟文稿“docs(1).txt”。文字編碼“Unicode(
判斷中文文字編碼格式是gbk還是utf-8的一種簡單方式
import java.io.*; public class charsetTest { public static String charsetType(String fileName) throws IOException { BufferedReader reader =
Android識別文字編碼
Android識別文字編碼 一、使用方式Usage 二、 程式碼解析 三、參考資料 一、使用方式Usage 下載andnext_utils模組 下載地址:https://github.com/
linux修改文字編碼centos7
centos7系統i18n檔案變成了/etc/locale.conf vi /etc/locale.conf 新增文字 LANG=zh_CN.UTF-8 輸入locale 結果如下 [[email protected] etc]# locale LANG
python自動識別文字編碼格式
#!/usr/bin/python3 # -*- coding: utf-8 -*- import codecs import os import chardet def detectCode(path): with open(path, 'rb') as file:
qt 文字編碼
qt中QString採用的是兩位元組UCS-2編碼, 而qt工程檔案中, 預設情況下采用的是utf8編碼。所以如果預設是utf8編碼,而從別的地方拷貝一個unicode編碼(windows下一般採用UCS-2編碼)的檔案過來時,會有一堆問題,最簡單的方法先將檔案編碼轉換成utf8編碼再加入。(理解u
【中文編碼】使用Python處理中文時的文字編碼問題
0x00 正文 最近,在處理中文編碼的資料的時候,遇到了一些還是令人頭疼的問題。 亂碼! 亂碼!! 亂碼!!! 稍微整理一下處理過程,順帶著記錄一下解決方案啥的…… 0x01 文字轉碼 最初,拿到很多GB2312(Simplify)編碼的HTM
NSStringEncoding關於文字編碼問題的解決方法
今天看見一個很棒的部落格,只是無法粉絲之,就轉載一下幾篇很好用的博文吧 轉載:http://www.cnblogs.com/zhwl/archive/2012/12/31/2840746.html 今天在嘗試抓取起點中文網首頁的時候遇到了一個問題 — 如果編碼沒有用對的話是沒辦法讀取任何東西
ubuntu修改文字編碼 .
sudo vi /var/lib/locales/supported.d/local 在此檔案中,新增一行 zh_CN.GBK GBK 2、 sudo locale-gen 會看到系統下載幾個檔案。 3、修改/etc/environment PATH="/usr/local
Eclipse中的文字編碼設定
如果要使外掛開發應用能有更好的國際化支援,能夠最大程度的支援中文輸出,則最好使 Java檔案使用UTF-8編碼。然而,Eclipse工作空間(workspace)的預設字元編碼是作業系統預設的編碼,簡體中文作業系統 (Windows XP、Windows 2000簡體中文)
C# 文字編碼轉換
1. C#的編碼轉換預設由System.Text.Encoding進行操控轉換. 引用為: using System.Text; 2. C# Encoding類自帶編碼有:UTF7/UTF8/UTF32/Unicode/ASCII, Encoding類有一個子
將.txt檔案用Mac開啟報文字編碼“Unicode(UTF-8)”不適用的解決辦法
蘋果電腦 Mac OS X 系統上雙擊 txt 檔案(尤其是 PC 傳過來的),會彈出「未能開啟文稿XXX,編碼"Unicode(UTF-8)不適用」的警告。一個純文字檔案,就是打不開
【Eclipse】Eclipse設定文字編碼為UTF-8
在eclipse中,js檔案的預設編碼是ISO-8859-1,每次新增一個js檔案,就必須手動的將js檔案的編碼格式改為UTF-8,由於這種針對每個檔案的編碼設定儲存在專案的.settings/org.eclipse.core.resources.prefs檔案中,
跨平臺的文字編碼轉換方法--ICU
最近在做一套跨平臺的簡訊收發開發程式,遇到了一個問題,那就是文字編碼轉換。在windowsg下的轉換有庫函式 MultiByteToWideChar WideCharToMultiByte,這二個,但是我要的是在linux機器下也可以正常使用,所以google了
如何將TXT文字編碼變為GB2312
如果你用記事本,另存為選擇ansi就是gb2312。 另外,如果你不確認檔案是什麼編碼,推薦用Replace Pioneer: 首先用Replace Pioneer檢測出一個檔案是什麼編碼: 1. 選擇Tools->Encoding Detection 2. 在
Python: 轉換文字編碼
最近在做週報的時候,需要把csv文字中的資料提取出來製作表格後生產圖表。 在獲取csv文字內容的時候,基本上都是用with open(filename, encoding ='UTF-8') as f:來開啟csv文字,但是實際使用過程中發現有些csv文字並不是utf-8格式,從而導致程式在run的過程中報錯
一文說清文字編碼那些事
一直以來,編碼問題像幽靈一般,不少開發人員都受過它的困擾。 試想你請求一個數據,卻得到一堆亂碼,丈二和尚摸不著頭腦。有同事質疑你的資料是亂碼,雖然你很確定傳了 *UTF-8* ,卻也無法自證清白,更別說幫同事 *debug* 了。 有時,靠著百度和一手瞎調的手藝,亂碼也能解決。儘管如此,還是很羨慕那些骨灰
刨根究底字符編碼之一——關鍵術語解釋(上)
基本上 傳輸 區分 pan 文章 表示 dig str 一位 聲明:本系列文章參考了網上的大量資料,除了少部分資料由於未作大量修改(但基本上也有少量修改,因為網上文章隨意性較大,很多明顯的筆誤或前後矛盾之處,如若不改反而讓人迷糊)而標明了原作者和出處之外,其余由於基本上