
ORB特徵提取詳解
轉自:https://blog.csdn.net/zouzoupaopao229/article/details/52625678
網上雖然出現了很多講解ORB特徵提取和描述的方法,但都不夠詳盡。為了搞明白到底是怎麼回事,只能結合別人的部落格和原著對ORB的詳細原理做一個研究和學習。哪裡有不對的地方,請多多指教
1、演算法介紹
ORB(Oriented FAST and Rotated BRIEF)是一種快速特徵點提取和描述的演算法。這個演算法是由Ethan Rublee, Vincent Rabaud, Kurt Konolige以及Gary R.Bradski在2011年一篇名為“ORB:An Efficient Alternative to SIFTor SURF”的文章中提出。ORB演算法分為兩部分,分別是特徵點提取和特徵點描述。特徵提取是由FAST(Features from Accelerated Segment Test)演算法發展來的,特徵點描述是根據BRIEF(Binary Robust IndependentElementary Features)特徵描述演算法改進的。ORB特徵是將FAST特徵點的檢測方法與BRIEF特徵描述子結合起來,並在它們原來的基礎上做了改進與優化。據說,ORB演算法的速度是sift的100倍,是surf的10倍。
1、演算法介紹
ORB(Oriented FAST and Rotated BRIEF)是一種快速特徵點提取和描述的演算法。這個演算法是由Ethan Rublee, Vincent Rabaud, Kurt Konolige以及Gary R.Bradski在2011年一篇名為“ORB:An Efficient Alternative to SIFTor SURF”的文章中提出。ORB演算法分為兩部分,分別是特徵點提取和特徵點描述。特徵提取是由FAST(Features from Accelerated Segment Test)演算法發展來的,特徵點描述是根據BRIEF(Binary Robust IndependentElementary Features)特徵描述演算法改進的。ORB特徵是將FAST特徵點的檢測方法與BRIEF特徵描述子結合起來,並在它們原來的基礎上做了改進與優化。據說,ORB演算法的速度是sift的100倍,是surf的10倍。
1.1 Fast特徵提取
ORB演算法的特徵提取是由FAST演算法改進的,這裡成為oFAST(FASTKeypoint Orientation)。也就是說,在使用FAST提取出特徵點之後,給其定義一個特徵點方向,以此來實現特徵點的旋轉不變形。FAST演算法是公認的最快的特徵點提取方法。FAST演算法提取的特徵點非常接近角點型別。oFAST演算法如下:

圖1 FAST特徵點判斷示意圖
步驟一:粗提取。該步能夠提取大量的特徵點,但是有很大一部分的特徵點的質量不高。下面介紹提取方法。從影象中選取一點P,如上圖1。我們判斷該點是不是特徵點的方法是,以P為圓心畫一個半徑為3pixel的圓。圓周上如果有連續n個畫素點的灰度值比P點的灰度值大或者小,則認為P為特徵點。一般n設定為12。為了加快特徵點的提取,快速排出非特徵點,首先檢測1、9、5、13位置上的灰度值,如果P是特徵點,那麼這四個位置上有3個或3個以上的的畫素值都大於或者小於P點的灰度值。如果不滿足,則直接排出此點。
步驟二:機器學習的方法篩選最優特徵點。簡單來說就是使用ID3演算法訓練一個決策樹,將特徵點圓周上的16個畫素輸入決策樹中,以此來篩選出最優的FAST特徵點。
步驟三:非極大值抑制去除區域性較密集特徵點。使用非極大值抑制演算法去除臨近位置多個特徵點的問題。為每一個特徵點計算出其響應大小。計算方式是特徵點P和其周圍16個特徵點偏差的絕對值和。在比較臨近的特徵點中,保留響應值較大的特徵點,刪除其餘的特徵點。
步驟四:特徵點的尺度不變形。建立金字塔,來實現特徵點的多尺度不變性。設定一個比例因子scaleFactor(opencv預設為1.2)和金字塔的層數nlevels(pencv預設為8)。將原影象按比例因子縮小成nlevels幅影象。縮放後的影象為:I’= I/scaleFactork(k=1,2,…, nlevels)。nlevels幅不同比例的影象提取特徵點總和作為這幅影象的oFAST特徵點。
步驟五:特徵點的旋轉不變性。ORB演算法提出使用矩(moment)法來確定FAST特徵點的方向。也就是說通過矩來計算特徵點以r為半徑範圍內的質心,特徵點座標到質心形成一個向量作為該特徵點的方向。矩定義如下:
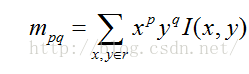
其中,I(x,y)為影象灰度表示式。該矩的質心為:
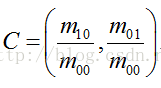
假設角點座標為O,則向量的角度即為該特徵點的方向。計算公式如下:
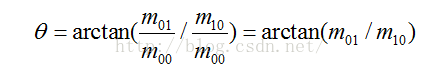
1.2 rBRIEF特徵描述
rBRIEF特徵描述是在BRIEF特徵描述的基礎上加入旋轉因子改進的。下面先介紹BRIEF特徵提取方法,然後說一說是怎麼在此基礎上修改的。
BRIEF演算法描述
BRIEF演算法計算出來的是一個二進位制串的特徵描述符。它是在一個特徵點的鄰域內,選擇n對畫素點pi、qi(i=1,2,…,n)。然後比較每個點對的灰度值的大小。如果I(pi)> I(qi),則生成二進位制串中的1,否則為0。所有的點對都進行比較,則生成長度為n的二進位制串。一般n取128、256或512,opencv預設為256。另外,值得注意的是為了增加特徵描述符的抗噪性,演算法首先需要對影象進行高斯平滑處理。在ORB演算法中,在這個地方進行了改進,在使用高斯函式進行平滑後,又用了其他操作,使其更加的具有抗噪性。具體方法下面將會描述。
關於在特徵點SxS的區域內選取點對的方法,BRIEF論文(附件2)中測試了5種方法:
1)在影象塊內平均取樣;
2)p和q都符合(0,S2/25)的高斯分佈;
3)p符合(0,S2/25)的高斯分佈,而q符合(0,S2/100)的高斯分佈;
4)在空間量化極座標下的離散位置隨機取樣;
5)把p固定為(0,0),q在周圍平均取樣。
五種取樣方法的示意圖如下:

論文指出,第二種方法可以取得較好的匹配結果。在旋轉不是非常厲害的影象裡,用BRIEF生成的描述子的匹配質量非常高,作者測試的大多數情況中都超越了SURF。但在旋轉大於30°後,BRIEF的匹配率快速降到0左右。BRIEF的耗時非常短,在相同情形下計算512個特徵點的描述子時,SURF耗時335ms,BRIEF僅8.18ms;匹配SURF描述子需28.3ms,BRIEF僅需2.19ms。在要求不太高的情形下,BRIEF描述子更容易做到實時。
改進BRIEF演算法—rBRIEF(Rotation-AwareBrief)
(1)steered BRIEF(旋轉不變性改進)
在使用oFast演算法計算出的特徵點中包括了特徵點的方向角度。假設原始的BRIEF演算法在特徵點SxS(一般S取31)鄰域內選取n對點集。
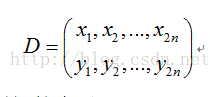
經過旋轉角度θ旋轉,得到新的點對
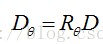
在新的點集位置上比較點對的大小形成二進位制串的描述符。這裡需要注意的是,在使用oFast演算法是在不同的尺度上提取的特徵點。因此,在使用BRIEF特徵描述時,要將影象轉換到相應的尺度影象上,然後在尺度影象上的特徵點處取SxS鄰域,然後選擇點對並旋轉,得到二進位制串描述符。
(2)rBRIEF-改進特徵點描述子的相關性
使用steeredBRIEF方法得到的特徵描述子具有旋轉不變性,但是卻在另外一個性質上不如原始的BRIEF演算法。是什麼性質呢,是描述符的可區分性,或者說是相關性。這個性質對特徵匹配的好壞影響非常大。描述子是特徵點性質的描述。描述子表達了特徵點不同於其他特徵點的區別。我們計算的描述子要儘量的表達特徵點的獨特性。如果不同特徵點的描述子的可區分性比較差,匹配時不容易找到對應的匹配點,引起誤匹配。ORB論文中,作者用不同的方法對100k個特徵點計算二進位制描述符,對這些描述符進行統計,如下表所示:
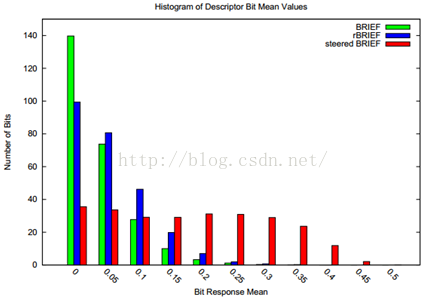
圖2 特徵描述子的均值分佈.X軸代表距離均值0.5的距離,y軸是相應均值下的特徵點數量統計
我們先不看rBRIEF的分佈。對BRIEF和steeredBRIEF兩種演算法的比較可知,BRIEF演算法落在0上的特徵點數較多,因此BRIEF演算法計算的描述符的均值在0.5左右,每個描述符的方差較大,可區分性較強。而steeredBRIEF失去了這個特性。至於為什麼均值在0.5左右,方差較大,可區分性較強的原因,這裡大概分析一下。這裡的描述子是二進位制串,裡面的數值不是0就是1,如果二進位制串的均值在0.5左右的話,那麼這個串有大約相同數目的0和1,那麼方差就較大了。用統計的觀點來分析二進位制串的區分性,如果兩個二進位制串的均值都比0.5大很多,那麼說明這兩個二進位制串中都有較多的1時,在這兩個串的相同位置同時出現1的概率就會很高。那麼這兩個特徵點的描述子就有很大的相似性。這就增大了描述符之間的相關性,減小之案件的可區分性。
下面我們介紹解決上面這個問題的方法:rBRIEF。
原始的BRIEF演算法有5中去點對的方法,原文作者使用了方法2。為了解決描述子的可區分性和相關性的問題,ORB論文中沒有使用5種方法中的任意一種,而是使用統計學習的方法來重新選擇點對集合。
首先建立300k個特徵點測試集。對於測試集中的每個點,考慮其31x31鄰域。這裡不同於原始BRIEF演算法的地方是,這裡在對影象進行高斯平滑之後,使用鄰域中的某個點的5x5鄰域灰度平均值來代替某個點對的值,進而比較點對的大小。這樣特徵值更加具備抗噪性。另外可以使用積分影象加快求取5x5鄰域灰度平均值的速度。
從上面可知,在31x31的鄰域內共有(31-5+1)x(31-5+1)=729個這樣的子視窗,那麼取點對的方法共有M=265356種,我們就要在這M種方法中選取256種取法,選擇的原則是這256種取法之間的相關性最小。怎麼選取呢?
1)在300k特徵點的每個31x31鄰域內按M種方法取點對,比較點對大小,形成一個300kxM的二進位制矩陣Q。矩陣的每一列代表300k個點按某種取法得到的二進位制數。
2)對Q矩陣的每一列求取平均值,按照平均值到0.5的距離大小重新對Q矩陣的列向量排序,形成矩陣T。
3)將T的第一列向量放到R中。
4)取T的下一列向量和R中的所有列向量計算相關性,如果相關係數小於設定的閾值,則將T中的該列向量移至R中。
5)按照4)的方式不斷進行操作,直到R中的向量數量為256。
通過這種方法就選取了這256種取點對的方法。這就是rBRIEF演算法。
2、ORB特徵提取實驗
實驗程式碼用opencv中的
2.1ORB特徵提取和匹配實驗

(1)

(2)

(3)

(4)
2-1 ORB特徵匹配
從上圖(1)(2)(3)可以看出,ORB演算法的特徵匹配效果比較理想,並且具有較穩定的旋轉不變性。但是通過(4)看出,ORB演算法在尺度方面效果較差,在增加演算法的尺度變換的情況下仍然沒有取得較好的結果。
ORB是一種快速的特徵提取和匹配的演算法。它的速度非常快,但是相應的演算法的質量較差。和sift相比,ORB使用二進位制串作為特徵描述,這就造成了高的誤匹配率。