
資料在記憶體中的儲存總結
資料型別介紹:
基本內建型別分別為:
char //字元資料型別
short //短整型
int //整形
long //長整型
long long //更長的整形
float //單精度浮點數
double //雙精度浮點型
//注意: C語言中沒有字串型別型別的意義:
1. 使用這個型別開闢的記憶體空間大小(大小決定了適用範圍)。
2. 如何看待記憶體空間的視角。
在32位平臺下,任何指標型別都只佔4個位元組。
型別的歸類:
整形家族:
char unsigned char signed char short unsigned short [int] signed short [int] int unsigned int signed int long unsigned long [int] signed long [int]
浮點數家族:
float
double構造型別:
> 陣列型別
> 結構體型別 struct
> 列舉型別 enum
> 聯合型別 union指標型別 空型別:
void 表示空型別(無型別)通常應用於函式的返回型別、函式的引數、指標型別。
注意:
1. void 是型別,不能定義變數,空型別對應的大小是0,。所以 void 無法開闢空間,即無法定義變數。
2. 雖然 void 在linux 系統下大小為 1 個位元組,但是系統認定 void 為空型別,同樣無法定義變數。
3. 雖然 void 不能定義變數,但是 void* 可以,在 32 為平臺下,任何指標的大小都是4個位元組,但是不能解引用。
4. C 語言中函式的返回值型別可以省略,但是省略之後預設為 int。
5. void* 可以接收任何型別。
整形在記憶體中的儲存:
一個變數建立是要在記憶體中開闢空間的。空間的大小是根據不同的型別而決定的。
在知道整形怎麼儲存之前,我們先引入
原碼、反碼、補碼。
計算機中的符號數有三種表示方法,即原碼、反碼和補碼。三種方法均有符號位和數值位兩部分,符號位 0 表示正數, 符號位 1 表示負數,而數值位,三種表示方法各不相同。
原碼:直接將二進位制按照正負數的形式翻譯成二進位制就可以了。
反碼:
將原碼的符號位不變,其他位依次按位取反就可以得到了。補碼:反碼 +1 就得到補碼。
正數的原碼、反碼、補碼相同。
對整形來說:資料存放記憶體中其實存放的是補碼。
這樣也是有原因的:
1. 使用補碼,可以將符號位和數值域統一處理;
2. 加法和減法也可以統一處理(CPU只有加法器);
3. 補碼與原碼相互轉換,其運算過程是相同的,不需要額外的硬體電路。
先來看看整形在記憶體中儲存的例子:
我們先定義兩個變數:
int a = 20;
int b = -10;然後看看他們在記憶體中是如何存的。
變數a在記憶體中的儲存:

因為a為正數,所以在儲存的時候先將十進位制數,轉化為二進位制數原碼,並且因為是正數,所以原、反、補碼相同,不用轉化。
變數b在記憶體中的儲存:
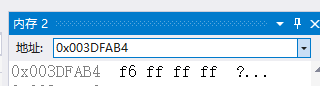
因為b為負數,在進行十進位制轉化為二進位制原碼後,要進行原碼和補碼之間的轉化,轉化過程為符號位不變其他位按位取反,再加一。
可是有沒有覺得怪怪的?為什麼數字是反過來排列的?難道不是應該是 00 00 00 14 和 ff ff ff f6 嗎?
這裡就要引入小端儲存和大端儲存。
資料是有高、低位之分的,記憶體地址是有高、低地址之別的。
小端儲存模式:是指資料的低位儲存在記憶體的低地址中;
上圖就是小端儲存,儲存的方式是
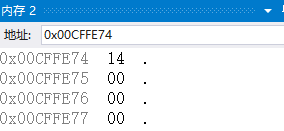

大端儲存模式:是指資料的低位儲存在記憶體的高地址中。
與小端儲存一樣,只是反過來,將低位資料儲存在高地址中,這裡不再贅言。
浮點數在記憶體中的儲存:
我們先看一個列子:
int main(void)
{
int n = 9;
float *pFloat = (float *)&n;
printf("n -> %d\n", n);
printf("pFloat -> %f\n", *pFloat);
*pFloat = 9.0;
printf("n -> %d\n", n);
printf("pFloat -> %f\n", *pFloat);
system("pause");
return 0;
}這個程式的輸出是:
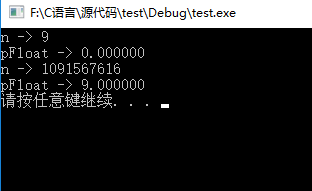
為什麼呢??????
只要我們瞭解了浮點數在記憶體中是如何儲存的,這個問題就很好解決!
1. 根據國際標準IEEE 754,任意一個二進位制浮點數V可以表示成下面的形式:
· (-1)^S * M * 2^E。· (-1)^S 表示符號位,當S == 0, V為正數;當S == 1, V為負數。
· M表示有效數字,大於等於1,小於2、
· 2^E表示指數位。
舉個例子:十進位制的5.0,轉化成二進位制就變成了101.0,用科學計數法表示就是 1.01 * 2^2 。那麼,按照上面V的格式,可以得出S = 0, M = 1.01,E = 2 。
如果是-5.0,S = 1, M = 1.01, E = 2 。
2. IEEE 754規定:對於32位浮點數,最高的1位是符號位S, 接著的8位是指數E,剩下的23位為有效數字M。

E和M的儲存方式也是IEEE 754的規定,記住就好。
對於64位浮點數,最高的1位是符號位S,接著的11位是指數E,剩下的52位為有效數字M。
圖跟上圖32位類似,這裡就不畫了。
E的兩種特殊取值:
1. E全為0:
當E全為0的時候,即2的次方為0 - 127 為2^-127次方,所以,當s = 0時,一個正數的2^-127次方,是一個從數軸的右邊無線趨近於0的數字;而當s = 1時,一個負數的2^-127次方是從數軸左邊無線趨近於0的數字。
所以當E全為0的時候,實際就表示的是+-0,所以浮點數不可以在程式中出現 與0去比較(浮點數 == 0),而是要跟一段範圍去比較。
2. E全為1:
當E全為1的時候(如果M全為0),即2的次方255 - 127 = 128,所以當S = 0時,表示1 * 2^128次方,當s = 1時表示-1*2^128次方。
所以當E全為1時,其實表示的就是這個浮點數的取值範圍。
那麼我們回到上面的例題,
1. n = 9 的儲存方式是
0000 0000 0000 0000 0000 0000 0000 1001
float *pFloat = (float *)&n 將n強制型別轉換為float形
系統就是認為上面的儲存方式是浮點數的儲存方式
即1.00000000000000000001001*2^-127
是一個及其接近0的數字,所以列印0
2. 第二種輸入方法一樣,給指標賦值9.0,指標是浮點型,
所以系統按照浮點數的儲存方式存放這個數字,
n為整形,系統輸出n的時候按照整形的在記憶體中的儲存方式去讀,
所以輸出n為一個非常大的數字。
這裡在普及一下,強制型別轉換,並沒有改變什麼,只是改變了系統讀取這個二進位制數的方式。
END……