1. 基礎概念 (統計分佈 抽樣 置信區間 標準差)
目錄
統計分佈
抽樣
置信區間
標準誤
StatQuest(https://statquest.org/)是一個非常好的生物統計學課程,課程簡單明瞭,幾乎涵蓋了目前生信所用到的全部統計學知識,作者不會過於使用複雜難明的式子,清晰簡單的解釋出複雜的統計學術語,非常適合統計學新手由淺入深地瞭解生信工具的內在統計學原理。
But I wanted them to understand that what I do isn’t magic – it’s actually quite simple. It only seems hard because it’s all wrapped up in confusing terminology and typically communicated using equations.
—— Josh Starmer (author of StatQuest)
本週開始,我將和大家一起學習分享StatQuest課程。
作者的所有課程都上傳在YouTube上,有上網條件的可以去學習,課程列表在https://statquest.org/video-index/,整個課程體系是比較完備的,不過我會從中挑選部分內容來進行學習分享。
一.統計分佈
首先從一個場景開始,假設你在參加一個Party,無意中聽到有人在討論統計學,並且正好討論到了統計分佈,那麼什麼是統計分佈呢?(作者舉的這個話題引入的例子看起來真的很直接,這是得多喜歡統計學,連party都不放過)
假設我們在統計測量Party上參會人的身高,身高分別是5.2,5.8,5.6,5.9,5.1,6.3,...(英尺),那麼你可以將他們逐個表示到一個圖形上,如下圖,每個紅球代表一個身高資料,下面的藍框代表身高的範圍。
這樣的長條組合在一起時可以叫做直方圖,可以看到大部分人的身高在5-6英尺。
如果將藍框的範圍減小,那麼可以看到這個直方圖會變得更加平滑和精確,大部分人的身高集中在5.25-5.75之間。
如果繼續增加身高資料和降低藍框的範圍,那麼就可以得到下面的直方圖:
同時,我們還可以在這個直方圖上畫一條平滑曲線,來代表這種資料趨勢(大部分人的身高在5-6之間,少部分在5以下和6以上)。
這個平滑曲線還有很多優點,直方圖右側是有一個空缺的,導致無法知道身高在此區間的概率是多少,但是平滑曲線是可以給出這個答案的,而且它不會受到直方圖的分段大小(圖一中的藍框)的影響。
再比如在我們沒有足夠的財力和精力去測定全部總體資料時,一個基於平均數和標準差的平滑曲線
圖中的直方圖和平滑曲線就是統計分佈,它可以告訴我們測量值的概率是怎麼分佈的,主要集中在哪些範圍,哪些資料出現的概率很低。
除了這個例子中的分佈外,還有很多其他分佈,他們的資料趨勢都可以幫我們理解大量的自然資料。
二. 抽樣
絕大部分情況下,從一個特定的分佈中抽樣,其實就是我們利用計算機生成一個隨機數,且這個隨機數得抽取滿足直方圖或平滑曲線描述的資料趨勢,以上圖的趨勢圖為例,越靠近中間的數值越容易被抽到,而越偏離中間的數值越不容易被抽到。
進一步的,我們將可以抽樣得到的樣本進行t檢驗,就可以探索這其中發生了什麼:
假設下圖的一個分佈,隨機取了兩個樣本,每個樣本3個數值,由於兩個樣本服從同一分佈,因此它們都更傾向於取值在中間區域(如圖),因此t檢驗也會給出較大的p值(p值就是可能性,p越大代表可能性越大,此處就代表兩者來自於同一分佈的可能性越大):
但是如果兩個樣本來自於兩個不同的分佈,那麼由於它們兩個的中間區域不一樣,因此t檢驗就會傾向於給出較小的p值:
三.置信區間
想直觀瞭解置信區間是什麼,要先從bootstrap談起:
假定我們要估計一群雌性小鼠的體重,抽樣12個小鼠,稱重,計算均值如下圖。
然後我們就可以使用bootstrap方法,得出這個樣本的均值的置信區間,如下圖,
-
從這12個樣本資料中隨機抽取12個數據(有放回);
-
計算這個樣本的均值;
-
重複步驟1、2,直到計算到足夠多的均值(如1000次,10000次等)
一般常用的95%置信區間就是覆蓋了中間95%的均值的區間(如下圖黑線所示),這其實就是置信區間了。
置信區間有什麼用?
95%置信區間代表覆蓋了均值95%的範圍,超出這個範圍的數值的出現次數都是<5%的,因此所有超出95%置信區間的數值的p值都是<0.05,都是顯著的。
假如要比較雌性和雄性小鼠的體重,得到如下的置信區間結果,那麼根據兩者置信區間沒有交界,就可以知道兩者差異顯著。
Bootstrap跟傳統的區間估計是有些相似的,但是更有普適性。
無論總體的分佈是什麼樣,我們知道樣本均值是漸進正態分佈的(假設總體均值存在)。利用漸進分佈我們就可以構造樣本均值的置信區間,但是問題是,要多少樣本量才收斂到漸進分佈呢?
如果總體不是常見分佈,我們很難判斷近似程度。並且,有的時候漸進分佈很難寫出來。Bootstrap就提供了一種靈活的,絕大多數情況都有效的方法,去判斷統計量的是否合適。
標準誤
誤差線作為資料波動和可信度的衡量,是必須的科研繪圖元素。
常見的誤差資料有3種:標準差、標準誤以及置信區間。
-
標準差:Standard Deviations,又叫做標準偏差,大部分情況下圖表中使用的都是標準差;
-
標準誤:Standard Errors,標準誤差,它代表樣本均值的分佈情況;
-
置信區間:Confidence Intervals,和標準誤是相關的。
標準差大家都知道,置信區間上面也說過了,那麼什麼是標準誤呢?
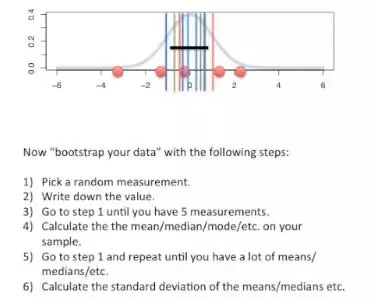
如下圖,假設從一個正態總體中抽樣,共得到3個樣本,每個樣本5個數據,分別用紅、綠、藍色小球表示。
每個樣本都有一個均值和標準差, 如下圖下半部分所示。而對3個平均值繼續求標準差,這個標準差就是均值的標準誤了。當然,如果需要的話,也可以求出標準差的標準誤(下圖3個標準差資料的標準差)、中位數的標準誤等等。
標準誤可以給出抽樣均值的波動程度如何,而不像標準差只是單次抽樣資料的波動,因此它往往更能估計總體均值。
那麼如何計算標準誤呢?
少數情況下,標準誤可以使用特定的公式計算。而任何情況下,你都可以使用bootstrap方法計算標準誤。
此處的bootstrap方法同上面置信區間中的方法相同:
-
如下圖,首先得到一個抽樣樣本,5個紅色小球;
-
隨機抽取一個測量值(紅色小球),並記錄;
-
重複隨機抽取,直到擁有5個測量值(小球是有放回地抽取的);
-
計算均值(或其他統計量,一般情況下我們更關心均值);
-
重複上述4步,直到獲得足夠的均值數,如1000個;
-
計算這個1000個數值的標準差即是標準誤。