【tensorflow】】模型優化(一)指數衰減學習率
阿新 • • 發佈:2018-11-17
指數衰減學習率是先使用較大的學習率來快速得到一個較優的解,然後隨著迭代的繼續,逐步減小學習率,使得模型在訓練後期更加穩定。在訓練神經網路時,需要設定學習率(learning rate)控制引數的更新速度,學習速率設定過小,會極大降低收斂速度,增加訓練時間;學習率太大,可能導致引數在最優解兩側來回振盪。
函式原型:
tf.train.exponential_decay(
learning_rate,
global_step,
decay_steps,
decay_rate,
staircase
staircase:布林值。如果True以不連續的間隔衰減學習速率,最後曲線就是鋸齒狀
該函式返回衰退的學習速率。它被計算為:
decayed_learning_rate = learning_rate * decay_rate ^ (global_step / decay_steps 指數衰減學習率的各種引數:
# 初始學習率
learning_rate = 0.1
# 衰減係數
decay_rate = 0.9
# decay_steps控制衰減速度
# 如果decay_steps大一些,(global_step / decay_steps)就會增長緩慢一些
# 從而指數衰減學習率decayed_learning_rate就會衰減得慢一些
# 否則學習率很快就會衰減為趨近於0
decay_steps = 50
# 迭代輪數
global_steps = 3000
是初始化的學習率,
是隨著
的遞增而衰減。顯然,當
為初值0時, 有下面等式:
用來控制衰減速度,如果
大一些,
就會增長緩慢一些。從而指數衰減學習率
就會衰減得慢一否則學習率很快就會衰減為趨近於0。
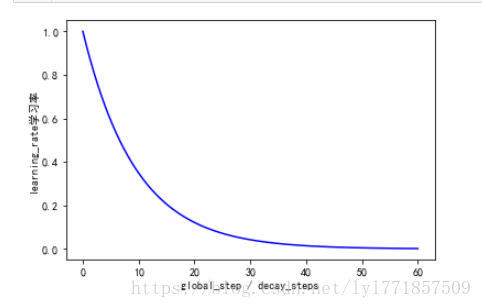
徒手實現指數衰減學習率:
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定預設字型
plt.rcParams['axes.unicode_minus'] = False # 解決儲存影象是負號'-'顯示為方塊的問題
X = []
Y = []
learning_rate=1
global_steps=3000
decay_steps=50
decay_rate=0.9
# 指數學習率衰減過程
for global_step in range(global_steps):
decayed_learning_rate = learning_rate * decay_rate**(global_step / decay_steps)
X.append(global_step / decay_steps)
Y.append(decayed_learning_rate)
#print("global step: %d, learning rate: %f" % (global_step,decayed_learning_rate))
plt.plot(X,Y,'b')
plt.ylabel(u"learning_rate學習率")
plt.xlabel('global_step / decay_steps')
plt.show()