
論文筆記 — MatchNet: Unifying Feature and Metric Learning for Patch-Based Matching
論文:https://github.com/ei1994/my_reference_library/tree/master/papers
本文的貢獻點如下:
1. 提出了一個新的利用深度網路架構基於patch的匹配來明顯的改善了效果;
2. 利用更少的描述符,得到了比state-of-the-art更好的結果;
3. 實驗研究了該系統的各個成分的有效作用,表明,MatchNet改善了手工設計 和 學習到的描述符加上對比函式;
4. 最後,作者 release 了訓練的 MatchNet模型。
網路框架:
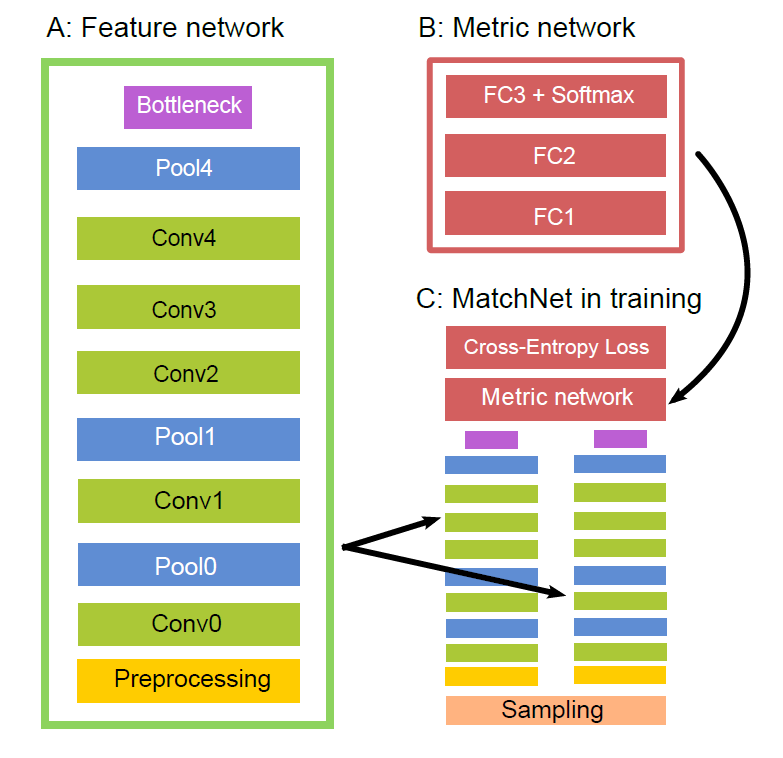
主要有如下幾個成分:
A:Feature Network.
主要用於提取輸入patch的特徵,主要根據AlexNet改變而來,有些許變化。主要的卷積和pool層的兩段分別有 preprocess layer 和 bottleneck layer,各自起到歸一化資料和降維,防止過擬合的作用。啟用函式:ReLU.
B:Metric Network.
主要用於feature Comparison,3層fc 加上 softmax,輸出得到影象塊相似度概率。
C:Two-tower structure with tied parameters
在訓練階段,特徵網路用作“雙塔”,共享引數。雙塔的輸出串聯在一起作為度量網路的輸入。The entire network is trained on labeled patch-pairs generated from the sampler to minimize the cross-entropy loss. 在預測的時候,這兩個子網路A 和 B 方便的用在 two-stage pipeline. 如下圖所示:

D:The bottleneck layer
用來減少特徵表示向量的維度,儘量避免過擬合。在特徵提取網路和全連線層之間,控制輸入到全連線層的特徵向量的維度。
E:The preprocessing layer
輸入影象塊預處理,歸一化到(-1,1)之間。
MatchNet 的具體引數如下表所示,注意Bottleneck 和 FC 中引數的選擇。

訓練和預測:
交叉熵損失,SGD優化,由於資料正負樣本的不平衡性,會導致實驗精度的降低,本文采用取樣的訓練方法,在一個batchsize中,選擇一半正樣本,一半負樣本進行訓練。
特徵網路和度量網路是聯合訓練的,使用交叉熵損失函式。在測試階段,可以分開進行,先將影象塊經過特徵提取網路得到特徵編碼並儲存,然後組合這些特徵,輸入到度量網路中得到N1*N2的得分矩陣。

總結:
1、MatchNet網路就是 siamese的雙分支權重共享網路,與論文Learning to Compare Image Patches via Convolutional Neural Networks有共通之處。CNN提取影象塊特徵,FC學習度量特徵的相似度。
2、本文指出,在測試階段,可以將特徵網路和度量網路分開進行,避免匹配影象時特徵提取的重複計算。首先得到影象塊的特徵編碼儲存,之後輸入度量網路中,計算得到N1*N2的得分矩陣。
參考文獻:
https://www.cnblogs.com/wangxiaocvpr/p/5515181.html