
論文筆記 | A Closer Look at Spatiotemporal Convolutions for Action Recognition
( 這篇博文為原創,如需轉載本文請email我: [email protected], 並註明來源連結,THX!)
本文主要分享了一篇來自CVPR 2018的論文,A Closer Look at Spatiotemporal Convolutions for Action Recognition。這篇論文主要介紹了Video Classification、Action Recognition方面的工作,包括2D、3D以及混合卷積等多種方法,最重要的貢獻在於提出(2+1)D的結構。
1. Related Work

圖1 視訊領域深度學習方法發展
在靜態影象任務(Object Detection、Image Classification等)中,深度學習的引入產生了巨大影響。但在視訊領域,深度網路在引入之初顯得有些乏力,於是針對2D網路對視訊任務適應性改進的工作開始成為流行。一種思路是保留2D網路用於空間推理,另外通過2D對Optical Flow或者3D對RGB進行時間推理,比如Two-Stream就屬於前者,ARTNet屬於後者。另一種思路是將2D核換成3D核,直接時空混合卷積,C3D是這種思路的體現。而後的P3D將時空操作分解,ARTNet和FstNet也是出於同樣的考慮。I3D另闢蹊徑,使得之前的2D網路在視訊領域仍然能發揮pre-train的作用。更重要的是,我認為2017年提出的Kinetics資料集可以稱為“視訊領域的ImageNet”,極大地擴充了資料量。今年,研究人員開始關注Relationship,很多Long-term的結構被提出。
2. Motivation
在Section 1,我闡述了在視訊任務中出現的幾種思路,本文是對其中“時空分解”的研究。單獨的2D網路對於視訊任務能力有限,3D網路的主要問題體現在引數量上(比如ResNet-18 2D的引數量為11.4M,同樣結構的3D網路引數量為33.4M,如果50或者101會更多),這會帶來很多問題,諸如過擬合、更難訓練等。既然單純的2D或者3D都不太好,時空分解或許值得嘗試,作者提出的時空分解具體分為混合卷積(Mixed Convolution)和(2+1)D。
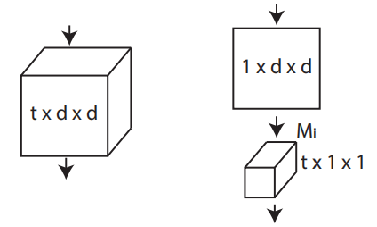
圖2 作者提出的(2+1)D模組
(圖2來自:D. Tran, H. Wang, L. Torresani, J. Ray, Y. LeCun and M. Paluri.
A Closer Look at Spatiotemporal Convolutions for Action Recognition.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
根據論文中作者的描述,他提出的MCx、rMCx和(2+1)D,是2D與3D的Middle Ground,混合卷積可以用更少的引數量取得與3D相當的Performance。(2+1)D對時空表達做了解構,這樣可以獲得額外的非線性(由於Factorization可以增加一個額外的ReLU層)。
3. Detail
上一部分中提到了3D模型引數量大的問題,使用(2+1)D可以有效減少引數量。但是引數量少了,模型的複雜度與表達能力會相應減弱,為了在同等引數量的前提下比較融合的時空資訊與分解的時空資訊的有效性,作者提出可以通過一個超引數M,將時空分解後的引數量恢復至分解前,如公式1所示。
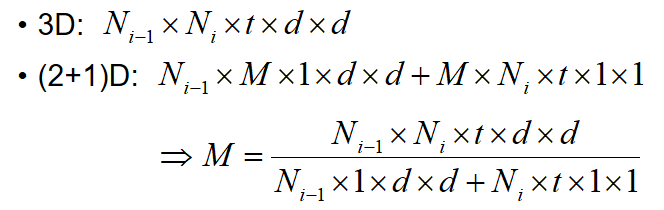
公式1 用於引數恢復的超引數M
4. Experiment
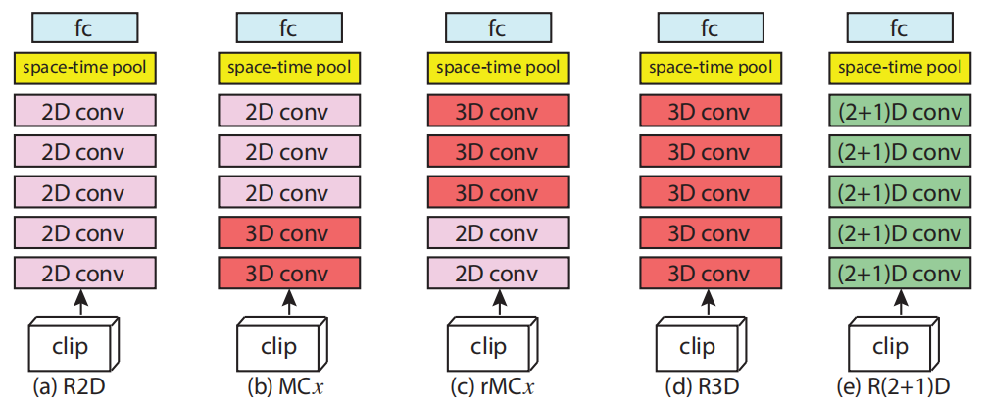
圖3 原文實驗的幾種結構
(a)R2D結構示意圖;(b)Mixed Convolution(MC)結構示意圖,x指明2D與3D卷積層的分界點;
(c)reversed Mixed Convolution(MC),x的意義與(b)相同;(d)R3D結構示意圖;(e)R(2+1)D結構示意圖。
(圖3來自:D. Tran, H. Wang, L. Torresani, J. Ray, Y. LeCun and M. Paluri.
A Closer Look at Spatiotemporal Convolutions for Action Recognition.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.)
作者使用了五種網路結構用於對比實驗(圖3),MC結構的提出是基於這樣一種Hypothesis:對於Motion/Temporal這種資訊的提取,應該在網路的底層進行,因為到了高層之後的資訊是高度抽象的,而非具體的。實驗的結果如表1所示,R2D的表現最差,但是從絕對角度而言,這種幾乎完全捨棄時間資訊的結構能夠達到58.9,也說明了空間資訊對於行為理解、場景理解的重要作用。3D模型的表現相比較2D大約有5個百分點的提升,但是引數量增加了兩倍。混合卷積的各種Variant都表現良好,但是卻無法印證之前的假設,似乎引數量更為重要。(2+1)D結構,通過將引數恢復到與3D模型一致後,其結果比3D高3.8個百分點,這說明了時空分解確實產生了作用。
總結:
(1)在視訊任務中,3D模型比2D模型更適用;
(2)3D模型引數量比較大,使用引數量更小的混合卷積,可以取得與3D模型相當的成績;
(3)時空資訊分解後,會帶來更好的表現。
表 1 實驗結果
(表中資料來自:D. Tran, H. Wang, L. Torresani, J. Ray, Y. LeCun and M. Paluri.
A Closer Look at Spatiotemporal Convolutions for Action Recognition.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.)

如有疑惑或發現錯誤,歡迎郵件聯絡:[email protected]
本文所分享的這篇論文來自CVPR 2018:
D. Tran, H. Wang, L. Torresani, J. Ray, Y. LeCun and M. Paluri. A Closer Look at Spatiotemporal Convolutions for Action Recognition. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.