
第七周:Python-new
python的應用場景
重復性的東西編寫腳本
和對於大數據量的操作
數據搭建的環境
不建議自己在網上找下載,建議下載anaconda,可在清華鏡像裏面下載anaconda,下載安裝之後可在桌面上找到程序image.png
jupyer Notebook 為本次學習的常用項目,可進行可視化界面操作,分段
shift+光標執行

python基礎
目錄
1.數據類型
2.變量
3.三大結構
- 3.1列表
- 3.2元組
- 3.3字典
4.控制流
5.def命名函數
6.Numpy包
- 7.1 Series
- 7.2 dataframe
8.數據的篩選
9.數據的聚合
10.多表關聯
11.多重索引
12.文本函數
13.空值&去重
14.apply函數
15.數據透視表
16.鏈接數據庫
1.數據類型:
數值型,直接輸入可以進行計算

可用type進行數據類型的判斷

返回整除的結果

顯示余數的結果

int整數直接計算

在python裏面單雙引號基本沒有影響,但是在一段話表示的時候裏面有單引號,整段話兩邊套上雙引號才能識別,都為單引號系統則識別不了。相反,整句裏面用雙引號,整句的時候則用單引號作為系統區分。

系統報錯,將單引號改成雙引號就可以識別(雙引號為具體內容的邊界)
邊界用三引號的時候,內容可以包含單雙引號的。
字符串:字符串同樣不能直接進行計算,可用int轉換成數字進行計算。
bool數組(ture默認為1,false默認為0):是可以進行與數字加減運算的

註意,第一個字母要大寫
None:代表缺失值,不能進行運算(相當於表格內畫斜線的格子)
“”:代表空值回目錄
2.變量
對應的叫“常量
a=1變量=1(不加引號的時候就是變量,中文也可以,但是不建議用,因為兼容性差)

同時給對個變量賦值:a,b=1,2
3.三大結構
3.1列表
num=[1,2,3]表示數據裏面有1,2,3,可以對其進行運算
len()列表裏面有幾個元素
訪問列表裏面有幾個元素:列表名[] 第一個位置是“0”表示

查找sql、增加、更改、刪除
shift+tab幫助鍵查
insert(位置,插入內容)插入
apped(插入內容)在末尾添加內容,但是插入的是唯一的值,不能添加多個因素
變量=變量+[內容1,內容2]添加多個因素可以此方法

pop(位置)刪除,直接空的話默認刪除末尾的數字
更改

二維列表的創建



元組
()
元組不能修改,與列表對比
字典
鍵key值value對
在磁盤上占用空間比較大,查詢效果一直會很快


set()將列表集合化,相當並集去重
list(set())將set進行嵌套變成新的列表


回目錄
4.控制流
if for while
【if】判斷

【while】循環


【for】for i in range(10) #10代表一個列表
for優點就是不容易形成死循環

需要1~100之間的數字


換一種寫法,一句等同以上三句的效果
5.def命名函數
”:“
換行縮進表示def內部的函數內容


1~10之間求平方
map()全匹配


免除了定義函數的苦惱
python有很多第三方庫,可以進行加載使用
加載:import collection
其中collection為第三方模塊

常用包:

特性是用法比較簡單,並且有很多共享的第三方包
回目錄
6.Numpy包
進行加載

Python的特點是語法比較簡單,並且有很多可以共享的第三方包其中今天提到的Numpy和Pandas這兩個包常用語統計分析,這兩個包會幫助我們保證速度的處理上千條數據。
【Numpy包進行加載和使用】



可用type查看數據類型
利用a變量對數組進行賦值
一樣可以接受與數組一樣的切片,簡單運算


能夠進行多維數據結構

註意數據類型的區別“int32“
7.Pandas包
性價比會相對較高一些(因為是基於Numpy開發的)--操作方面更加習慣,數據框的形式。
進行加載並重命名為pd:import pandas as pd

其主要有兩個數據結構:
- 7.1 Series
一維的,在tab搜索時首字母S要大寫

從0開始到4結束,索引
有一些比較高的屬性shift+tab調出查看裏面支持哪些參數

結果區別

索引查找

索引也可以進行多個值索引,索引是列表表示,所以需要有方括號。

最外面的方括號代表索引方式
裏面的方括號,代表索引的內容一個列表

比較智能的可以自動補缺

特性:原始的數值類型的內容增加一個字符串,則整體都會變成字符串,數據類型會保證統一。
基礎是一維的近似於數組的結構。
- 7.2 dataframe
二維的,視覺上比較接近表格
相當於無數的一維疊加起來,支持多形式輸入
通過字典來輸入數據框:

會發現順序改變,是因為字典本身就是無需的
進行一維輸入:會發現,兩者不等價,數據結構是不一樣的

對數據框進行切片,數據類型進行變換

等價代碼df.age,與別的一起寫有可能會報錯,建議用方括號的切片形式
基於行的切片

同時可切多個值



以上主要是些標準的查找
單獨搜索某一值

字符串的更改

針對的是某個行和某個列
某一個特定值的篩選“年齡為18歲的”
方法1:邏輯判斷


外面的df是提取出來,裏面的df代表的是邏輯判斷。
提取結構就是TRUE的結果內容

多條件的篩選查找

同時滿足這兩個條件的,“|”為並集
方法2:邏輯判斷

iloc和loc查找(可同時滿足兩個參數進行切片的)
iloc所在行的數字進行索引,是針對第幾行的

loc是針對標簽進行切片的

(可同時滿足兩個參數進行切片的)


df.ix是可以行和標簽一起使用,但是還是會報錯,不建議使用。

讀入.csv文件:read.csv
首先把文件放在相同的目錄下面

本身默認讀取就是utf所以讀取會很順暢
如果改成讀取gbk則會報錯,如果讀取gbk需要進行設置解析編碼

查看前幾行:

查看尾行:df.tail()
查看數據類型依然用:df.info()




還可以繼續追加篩選過濾條件

回目錄
8.數據的篩選
1.轉至
表名稱.T,可將表格快速的轉至


2.排序
【values】函數
方法1:排序的依據by="排序依據"

方法2:通過數組也可以進行排序
df.avg.sort_values()
二者區別是,如果用數組調,返回的是數組,在數據框裏面調直接返回的是數據框。
ascending=False改變排序升序為降序
對字段進行排序:直接把條件加入

列出的表不是根據實際的中文順序進行的,介意的話需建另一張表格進行調整。
【index】按照索引的排序

【rank】函數


默認順序為升序排列,添加ascending參數改為降序
method參數默認為加權平均,改為min直接用排序第一個,符合現實使用的習慣。改為first則排序不考慮並列情況直接按照順序來進行。
3.查找重復

直接可查出有多少個唯一值

加個count可直接查找出合計數量
4.描述性統計



5.累計累加

6.分段統計
使用更加適合分段統計的cut函數
pd.cut(df.avg.bins=5) 系統自動分割成5部分
也可以自定義區間,然後命名

常用於用戶分級、消費水平分割等使用場景
7.分位法進行分割統計
分位法函數:.qcut()

x具體的內容例如df.avg
q排名幾等分
retbins是否包含開區間閉區間
precision分割出來的精度
duplicates是否要進行些去重操作
回目錄
9.數據的聚合
聚合函數:mysql不支持分組排名,則可用此函數groupby

通過for循環可把分組內容打印出來進行查看

10.多表關聯
三種關聯方法
1.merge根據鍵值,對的是某一列

同名去重不同名保留
附加:
修改表的字段名稱可用rename()函數
也可把行名提取出來,然後從0開始查其位置進行更改,再賦值的方法(一般用於只改一個,比較簡單)
col=list(df.columns)
col[0]=‘all‘
df.columns=col2.join針對索引進行

針對的是固定的索引例如日期
3.concat堆疊,對應的是對象

兩張表格上下放一起,“暴力組合”
之間是上下拼接,增加函數 .axis=1 進行左右拼接,對不上的默認為空值。
應用場景:例如1~12月份相同字段的銷售統計的拼接匯總等。
11.多重索引
方法1:可用切片

方法2:數據框類型的

不借助groupby進行設置多重索引的方法:set_index

把列變成索引進行排序,輸出可達到整理在一起的效果

反過來把索引變成列,增加函數reset_index()即可

這時後面可直接[]去引用。
回目錄
12.文本函數
pandas裏面預處理函數
需求:想把表格內某一列帶方括號的字段去掉方括號。
思路1:直接進行左右兩邊切掉(不成功,因為操作是針對數組進行的,是針對索引的切片)

思路2:調用.str()(可行)
例如:.str.count統計字符串出現的次數
.str.find(“數據”)從哪個位置開始統計
.str都是針對值裏面的字符串進行的操作

需求:繼續把單引號排除
思路1:用空值替換單引號(不可行)

因為replace針對的是表格內具體的某一值進行替換,所以,上面對表格內字段進行替換並沒有成功。
思路2:增加.str (可行)

回目錄
13.空值&去重
1.空值
對表賦予空值,及對空值進行再賦值


2.刪除重復元素

去重方法1:

去重方法2:相對更簡單

14.apply函數
幫助我們把一個函數或者自定義函數應用到所有的行或者列裏面進行處理,可大大提高數據分析的效率。
需求示例:
薪資顯示數值後面加上K,例如11.5K
方法1:

用 .str將浮點數據轉成文本再進行拼接
方法2:

輸入x,輸出的是. str和k進行拼接
輸入從position.avg來
apply的優點是特別快
方法3:等價方法2(在裏面可加進去簡單的判斷)

方法4:

註意,直接position會直接報錯,因為對象不能針對整個表,其中參數axis默認為0,是空值對應函數應用到列裏面。需要把它設置為=1,說明函數設置應用到列,對這一列數組進行操作,指明是x.avvg則可成功。
1.apply聚合(分組)
需求:不同城市下面新增排名前5的職位。
分析需求:
①對不同城市--分組
②前5---排序

方法1:記住輸入和輸出

數據拆開後再合並
方法2:

通過控制參數,變成升序

agg和apply的區別:agg聚合後針對固定的行和列,apply的靈活性比較高,可以對數據進行拆分再組合,不涉及行數的變化用agg是可以的。

agg直接調用方法;

等價於:

比較高級的用法是,可以同時應用多個函數

回目錄
15.數據透視表
可以處理超大的數據對比Excel透視

首選要考慮“我想要的數據透視表形式是什麽樣子的”
values:具體的哪個值進行計算
index:按照什麽來進行聚合,例如“city”
columns:列是設什麽樣子的,例如“workyear”
aggfunc:具體形成什麽樣子的值,默認是“mean”

多重索引同樣可以

調用np,所以要用np.mean等計算方式,直接mean則會報錯

也可在此表格進行繼續接片

其中margins參數=Ture是在透視表下面添加匯總項目
透視表的一些高級用法:
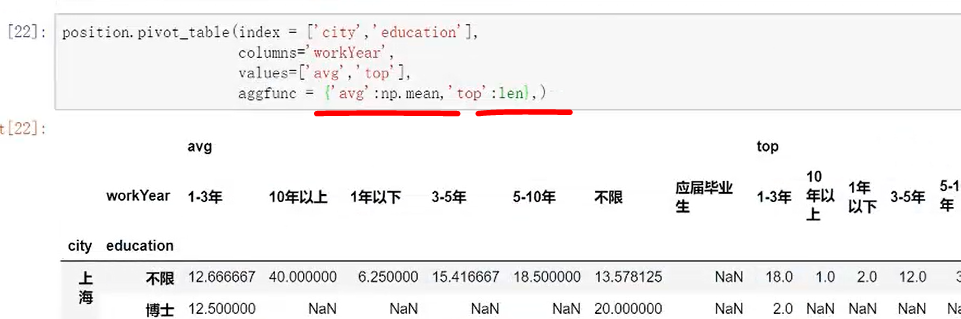
需求:只想要對平均薪資進行平均,top進行求和,想要計算values的值是有針對性的。
方法:aggfuns裏面把列表改成字典
應用場景,對處理大數據量的統計提供很好的工具。
<a href=#mulu><font color="#C0C0C0">回目錄</font></a>
### <a id="16">16.鏈接數據庫</a>
建議用pandas鏈接數據庫,會比較方便
需要安裝一依賴包
老師在講的時候說新人在安裝依賴包的時候回會遇到些問題,很幸運~我就遇到了~~~
安裝包的時候出現“pip不是內部外部,或其他可執行的程序”的報錯
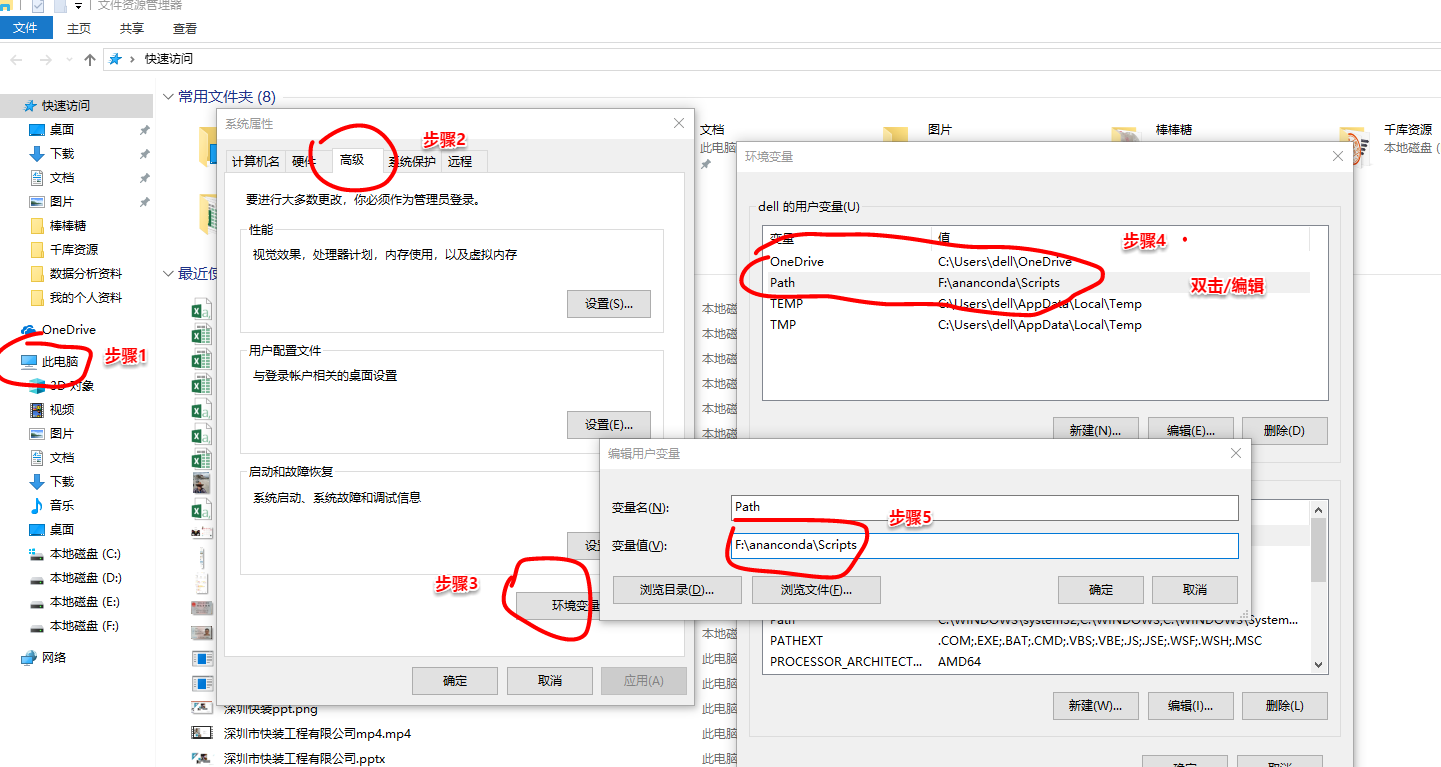
方法:需要把環境配置一下,
此電腦-->屬性-->高級-->環境變量-->Path-->把ananconda裏面含有pip程序的兩個文件的位置路徑放進去-->保存-->調用cmd(win+r,輸入cmd)-->成功

**1.鏈接數據庫方式**
import pymysql #加載變量
conn=pymysql.connect(
host=‘localhost‘, #定義新的變量鏈接,可以直接輸入localhost,也可以直接輸入本地的地址127.0.0.11因為mysql一般都是本地所以這兩種方法均可
user=‘root‘, #數據庫用戶名稱
password=‘12346‘, #賬號密碼
db=‘data‘, #想要鏈接的數據庫
port=3306, #輸入端口,默認的,如果有變化自己更改即可
charset=‘utf8‘ #文本編碼如果是gbk則改成gbk對應
)
```
創建後調用一個方法(直接記住)
conn.cursor()
之後可以用 .execute()來進行sql語句的輸入

如果需要把所有的結果都執行出來
data=cur.fetchall()
不過會以元組的形式輸出,需要簡單處理一下


進行增刪該查後的結果提交操作可用.conn.commit()方可提交
打開遊標之後,需要養成好的習慣進行關閉
cur.close()
同樣,數據庫連接進行關閉
conn.close()
2.連接數據庫方式
pandas在數據庫的應用最關鍵的是sql和con
可直接先把sql語句寫好
要註意的是鏈接是比較特殊的,新的鏈接方式 .orm幫助數據讀寫的sqlalchemy

從讀取到處理然後到寫入數據庫的過程:
①讀取表:

如果忘記數據庫中有哪些表的具體名頭可以用此函數進行查看
reader(‘show tables‘)
②處理合並多表格

③按照需求條件,分組匯總,提取部分數值轉換重置成數據框

④查看數據類型是否需要更改
result.info()
⑤寫入數據庫

參數if_exists指的是他是否存在了=‘fail‘是默認的,也就是說如果表存在的話,則寫入是失敗的。
把參數修改成 =‘append‘ 是指插入數據,即表存在的話則是插入數據,表不存在的話則會是新建數據,
參數index,如果=True是代表寫入的時候把數據框裏面的索引變成一列進行存儲;一般會更改為=False不寫入。

返回mysql數據庫查看

會發現新導入的表格的字段類型和之前的不太相符,不是預想的最優形式。
建議在開始做的時候,預先在數據庫中建好,設置好新的表格表頭及類型,然後再進行導入。
並且註意,在python導入運行步驟時候,如不小心執行了多次,則在數據庫中也會相應的重復增加多次的數據,所以操作要小心謹慎。
當在數據庫建表的時候字段小於導入字段的時候,python會報錯。
當在數據庫建表的時候字段大於導入字段的時候,python則可正常寫入,在數據庫中可自動匹配為空。
⑥寫入 .csv

返回總目錄
轉自:https://ask.hellobi.com/blog/cbdingchebao/10505
第七周:Python-new