Spark在Intellij IDEA中開發並執行
阿新 • • 發佈:2018-11-19
word count demo
引入jar
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.0</version>
</dependency>
wc程式碼
package com.tiffany;
import org.apache.spark.SparkConf;
import org.apache. maven打包
打包好後上傳jar包到伺服器
clean package -Dmaven.test.skip=true
執行
建立測試目錄
[[email protected] test]$ hdfs dfs -mkdir /input
[[email protected] test]$ hdfs dfs -ls /
drwxr-xr-x - hadoop supergroup 0 2018-08-13 11:13 /hbase
drwxr-xr-x - hadoop supergroup 0 2018-10-10 16:42 /input
drwxr-xr-x - hadoop supergroup 0 2018-04-08 10:40 /out
-rw-r--r-- 3 hadoop supergroup 2309 2017-08-06 19:21 /profile
drwx-wx-wx - hadoop supergroup 0 2018-04-08 10:39 /tmp
drwxr-xr-x - hadoop supergroup 0 2017-09-03 19:18 /user
上傳測試檔案
[[email protected] data]$ hdfs dfs -put test.txt /input
檢視測試檔案
[[email protected] data]$ hdfs dfs -cat /input/test.txt
hello world
hello spark
standalone叢集模式-client模式
[[email protected] jars]$ /data/spark-2.2.0-bin-hadoop2.6/bin/spark-submit --class com.tiffany.SparkWordCount --master spark://hadoop1:7077 /data/spark-2.2.0-bin-hadoop2.6/examples/jars/Spark-1.0-SNAPSHOT.jar hdfs://hadoop1:9000/input/test.txt
standalone叢集模式-cluster模式
[[email protected] jars]$ /data/spark-2.2.0-bin-hadoop2.6/bin/spark-submit --class com.tiffany.SparkWordCount --master spark://hadoop1:7077 --deploy-mode cluster /data/spark-2.2.0-bin-hadoop2.6/examples/jars/Spark-1.0-SNAPSHOT.jar hdfs://hadoop1:9000/input/test.txt
Running Spark using the REST application submission protocol.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
18/10/10 17:01:47 INFO RestSubmissionClient: Submitting a request to launch an application in spark://hadoop1:7077.
18/10/10 17:01:58 WARN RestSubmissionClient: Unable to connect to server spark://hadoop1:7077.
18/10/10 17:01:58 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
執行結果
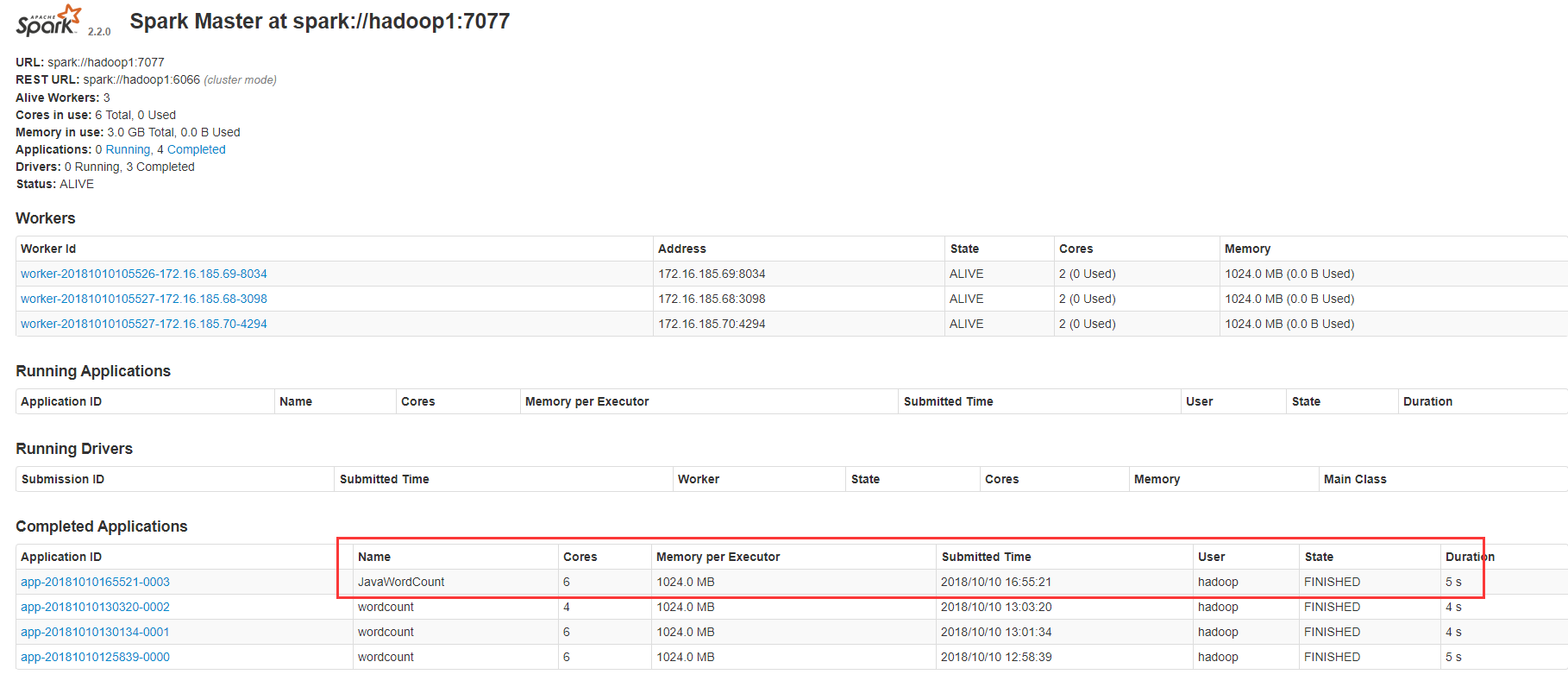
執行結果
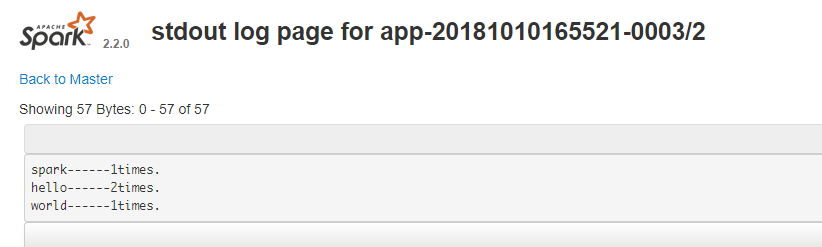
IDEA local
設定IDEA執行項的Configuration中的VM opthion 增加-Dspark.master=local
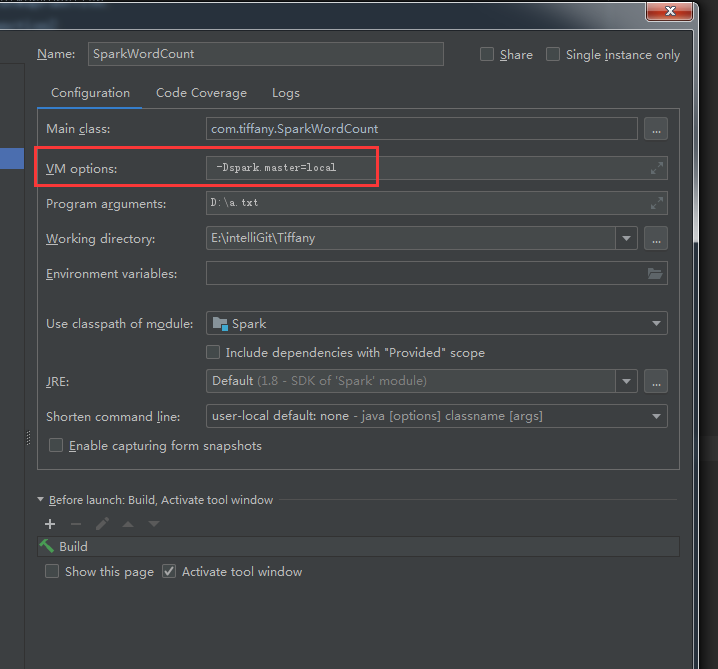
執行結果