【MYSQL學習筆記02】MySQL的高階應用之Explain(完美詳細版,看這一篇就夠了)
版權宣告:本文為博主原創文章,未經博主允許不得轉載。 https://blog.csdn.net/wx1528159409
最近學習MySQL的高階應用Explain,寫一篇學習心得與總結,目錄腦圖如下:
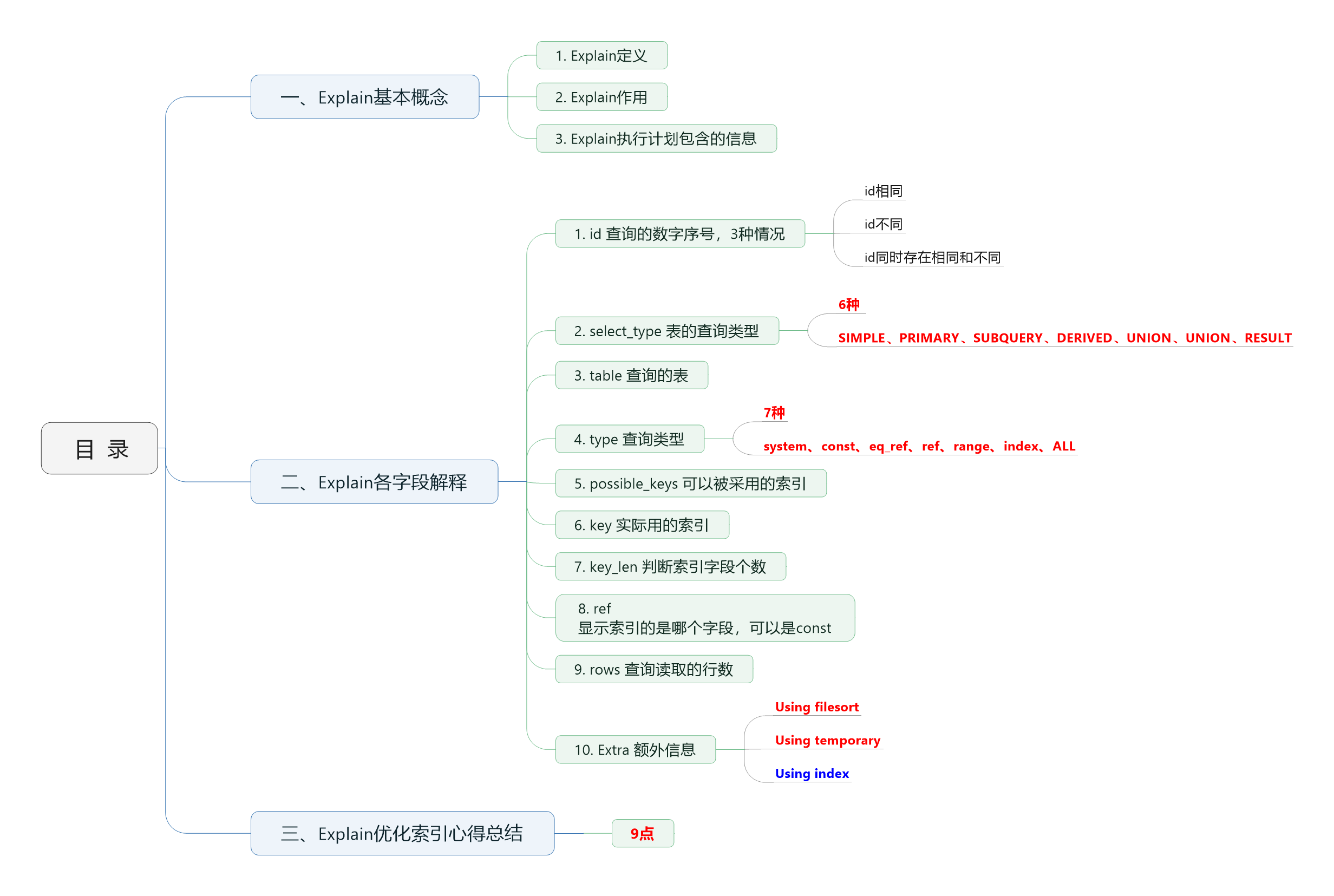
一、Explain基本概念
1. Explain定義
· 我們知道MySQL中有一個查詢優化器Query Optimizer,它的作用是找到最小代價的正確執行方案;
· EXPLAIN :模擬Mysql優化器是如何執行SQL查詢語句的,從而知道Mysql是如何處理你的SQL語句的,分析你的查詢語句或是表結構的效能瓶頸。
· explain顯示了mysql如何使用索引來處理select語句以及連線表。可以幫助選擇更好的索引和寫出更優化的查詢語句。
2. Explain的作用
通過在select+sql語句前加上explain,我們可以看出:
(1)表的讀取順序,id(table是id對應的表)
(2)資料讀取操作的操作型別,select type
(3)哪些索引可以使用,possible_keys
(4)哪些索引被實際使用,key
(5)表之間的引用,ref
(6)每張表有多少行被優化器查詢,rows
3. explain執行計劃包含的資訊

二、Explain中各欄位的解釋
1. id
select查詢的數字序列號,表示查詢中執行select子句、或多表聯合查詢時操作表、的順序;
· (1)id相同,執行順序由上至下
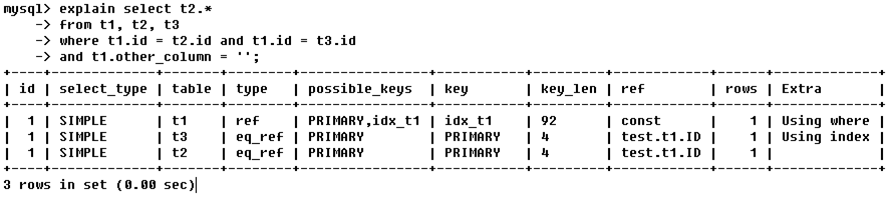
從t1、t2、t3三張表中查詢t2表的全部,查詢條件是:t1.id=t2.id 、t1.id=t3.id、t1的其他欄位是空;
優化器對於同一個where內部的條件,預設是從右往左讀取的;
所以三張表的執行順序是:t1 -> t3 -> t2;
· (2)id不同,id越大執行優先順序越高
如果是子查詢,id的序列號會遞增,越是在裡面的子查詢越優先執行,類似於遞迴的思想;( )裡的語句具有優先順序
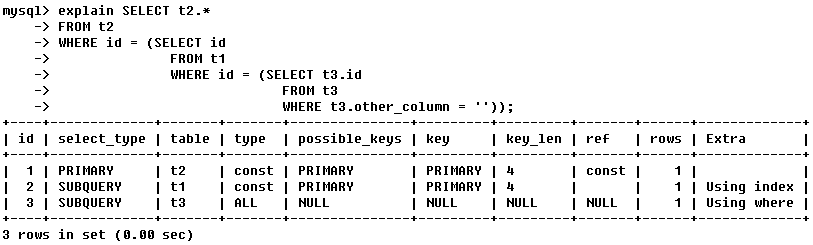
從t2表中查詢t2表的全部,查詢條件是id,查詢條件是三層巢狀:
從表t1查詢id——id是從表t3中查詢到的t3表的id——t3表的其他欄位為空;
用遞迴的思想,很容易判斷,表的執行順序:t3 -> t1 -> t2
· (3)id同時存在相同和不同的情況,id不同的id大的優先執行,id相同的從上到下執行
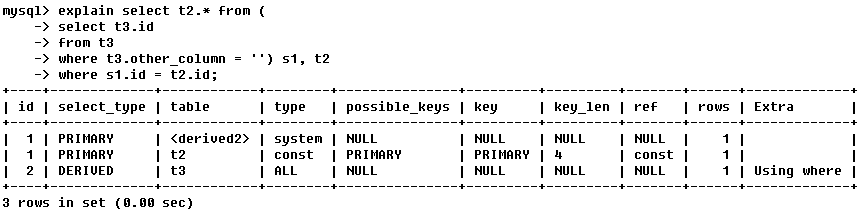
這裡需要引入一個概念,衍生虛表查詢(Derived):
從原表中擷取部分資訊,組成的結果集可以構成一張新表,這張表並不實際存在,作為一張虛表被呼叫;這種查詢就叫衍生虛表查詢;
(從表t3中查詢t3表的id,查詢條件是其他欄位為空)將括號中t3表的查詢條件,的結果集作為一張虛表s1,
從虛表s1、表t2中,查詢表t2的全部,查詢條件是s1.id=t2.id;
所以,查詢的順序是:t3 -> derived2 -> t2
derived2指,由id=2時,即表t3的結果集衍生構成的虛表s1;
2. select_type
查詢的型別,一共有以下6種表的查詢型別:
· (1)SIMPLE
簡單查詢,查詢中不包含子查詢、union(聯合查詢);
· (2)PRIMARY
查詢中若包含子查詢,則最外層查詢被標記為PRIMARY;
· (3)SUBQUERY
在select或where列表中的子查詢
· (4)DERIVED
典型語法:from ( 子查詢 ) s1,
在from列表中包含的子查詢,被標記為DERIVED(衍生),這個子查詢執行後的結果集放在一張虛表s1中;
· (5)UNION
若第二條select出現在union之後,則標記為union聯合多表查詢;
若union包含在from字句的查詢中,即select 屬性 from(子查詢1 union 子查詢2)s1,這種外層的select被標記為DERIVED;
· (6)UNION RESULT
從UNION表中獲取結果的SELECT
3. table
指id對應的表,通過id判斷表的執行順序;
也指這一行的資料是關於哪張表的;
4. type
顯示查詢時,使用了哪種查詢型別,日常工作中經常接觸到的有以下7種,效能由最好到最差依次是:
system > const > eq_ref > ref > range > index > ALL
一般需要保證查詢型別等級達到range,最好能達到ref,避免使用ALL。
· (1)system
系統查詢,指表中只有一行資料,這是const的特例,平時不會出現,因為只有一行資訊就不叫大資料了,所以意義不大;
· (2)const
常量查詢,表示通過索引Index一次就找到了,用於比較 primary key=常量 和 unique=常量 這種索引;
如將主鍵置於where列表中,mysql具有自動轉換型別的功能,會自動將該查詢轉化為一個常量

d1是虛表,括號具有優先順序,首先執行表t1,where id = 1是常量查詢const;
虛表d1由於只有一行資料,所以查詢型別是系統查詢system;
· (3)eq_ref
唯一性索引掃描,對於每個索引鍵,表中只對應一行資料,常見於主鍵

where後面沒有括號,MySQL優化器從左到右執行,因此先執行表t2,type是ALL全表查詢,對應639行資訊;然後查詢表
t1,type是eq_ref,表1中id只對應1行資訊,唯一索引掃描;
· (4)ref
非唯一索引掃描,對於每個索引鍵,表中可能對應多行資料;
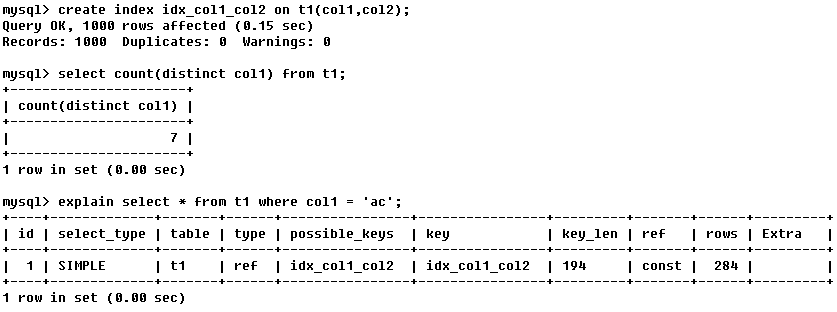
查詢表t1中,不重複的欄位col1有7條,其餘全是重複的;
滿足查詢條件col1='ac’的記錄有284行,所以是ref非唯一索引掃描;
· (5)range
範圍查詢,where後面的列表中是between、<、>、in等的查詢;

關鍵詞between,type是range範圍查詢;

關鍵詞in,type是range範圍查詢;
★ 關鍵詞like也是範圍查詢,後面再寫;
· (6)index
全索引掃描,FULL INDEX SCAN,只遍歷索引樹,通常比ALL快;
(index與ALL都是全表查詢,但index是從索引中讀取,ALL是從全表中讀取);
· (7)ALL
全表掃描,FULL TABLE SCAN,遍歷全表找到匹配的行;速度最慢,避免使用;
5. possible_keys
查詢的欄位上若存在索引,則將索引列出,一個或多個,但不一定在查詢時實際使用;
6. key
實際使用的索引,若為NULL,則沒有使用索引,常見的可能原因:
· (1)沒有建索引
· (2)sql語句寫法錯誤,索引失效;
· (3)possible_key也為NULL時,表示用不到索引
7. key_len
可以通過key_len看出索引欄位的個數,74指1個,78指2個,140指3個;
8. ref
顯示使用索引的是哪個欄位,可以是一個const常量;
ps:type裡的ref指非唯一索引掃描,對索引欄位,可能存在多個重複值;

從表t1和表t2中查詢所有,查詢條件:t1.col1=t2.col1、t1.col2=‘ac’;
同一個where列表中,優化器從右到左執行,索引有兩個欄位;
優先執行欄位值’ac’,是const常量;
然後執行資料庫shared中表t2中的欄位col1,即shared.t2.col1;
9. rows
索引查詢時,大致估算出查詢到所需記錄讀取的行數,rows越小越好;
10. Extra
額外資訊,包含以下三種:
· (1)Using filesort
說明建立的、準備使用的索引index並沒有被用到,執行了檔案排序;
可能是sql語句寫法有問題,與之前建立的索引index衝突了;
· (2)Using temporary
使用了臨時表來儲存中間結果,說明建立的索引沒有使用完全;
常見於排序order by和分組查詢group by;
· (3)Using index
select操作中用到了覆蓋索引(Covering Index),說明sql執行的效率不錯!
覆蓋索引(Covering Index):
eg:先creat一個index,index_欄位a_欄位b;
然後select 欄位a,欄位b on table where 欄位a=…,欄位b=…
即先建立擁有某幾個欄位的索引,然後查詢索引裡的欄位,where列表是索引欄位的值;即當索引欄位值為XXX時,查詢該欄位;這是select效率最高的方式。
··· 若同時出現using where,表明索引被用來執行索引鍵值的查詢;
··· 若沒有同時出現using where,表明索引沒有用來執行索引鍵值的查詢,只是用來讀取資料;
三、Explain中優化索引心得總結
1. 左字首保留原則
如果索引了多個欄位,查詢從索引的最左端欄位開始,並且不會跳過索引中的欄位;
eg:索引欄位1,2,3,對應樓層的123層,
如果沒有1層,索引2和3,那麼無法找到2樓和3樓;
如果沒有中間層2層,那麼無法找到3樓;
ALTER TABLE staffs ADD INDEX idx_staffs_nameAgePos(name, age, pos);
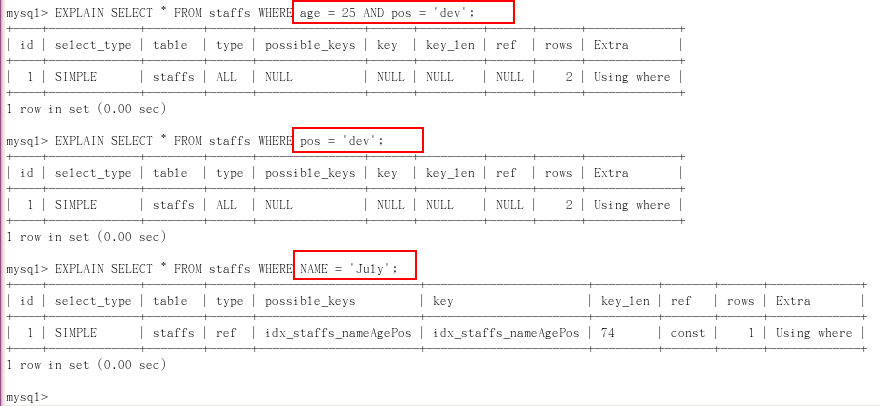
建立索引 idx_staffs_nameAgePos(name, age, pos),索引欄位從左往右依次是name、age、pos
從上圖中可以看出:
表1和表2沒有name,所以索引無法查詢,possible_keys和key都是NULL,出錯;
表3中有name,possible_keys和key使用索引idx_staffs_nameAgePos查詢,正確;
2. 不在索引列上做任何操作(計算、函式、(自動or手動)型別轉換)
已經建立好了索引,在select時,在where列表中對索引列表進行修改,容易引起索引失效,從而變成全表掃描ALL,
降低資料庫的效能;
3. 儲存引擎不能使用索引中範圍條件range(<、>、between、in等)右邊的索引欄位
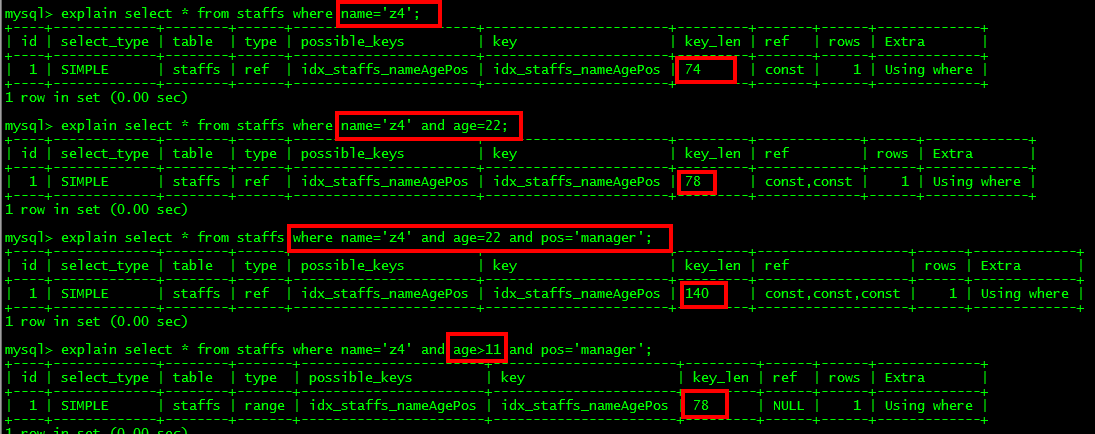
最下面的索引,age>11是範圍條件,它右邊的欄位pos='manger’索引失效;
所以最後索引只用到了兩個欄位,name和age;key_len是78;
4. like形式的range範圍查詢,以萬用字元%開頭時,要將%放在字母右邊,否則索引失效轉為全表掃描
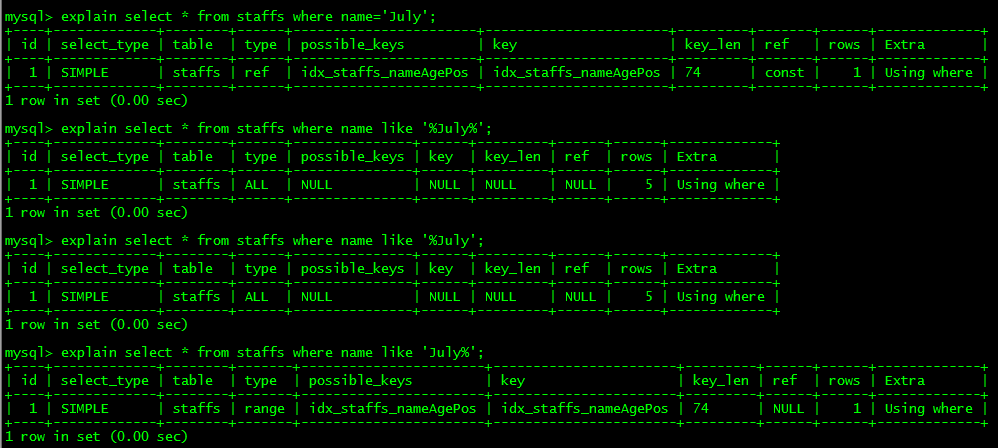
可以發現,當like後面欄位萬用字元%放在最左邊時,索引失效,type轉為全表掃描ALL;
因為欄位掃描時,%在最左邊無法確定欄位,所以索引失效;
若字母在欄位最左邊,可以確定欄位,索引有效;
5. 儘量使用覆蓋索引(Covering Index),即create的索引欄位與select中where列表的查詢欄位,一致;
減少使用select *,提高索引效率;
6. 使用不等於(!=、<、>)時,有時無法使用索引會導致全表掃描ALL
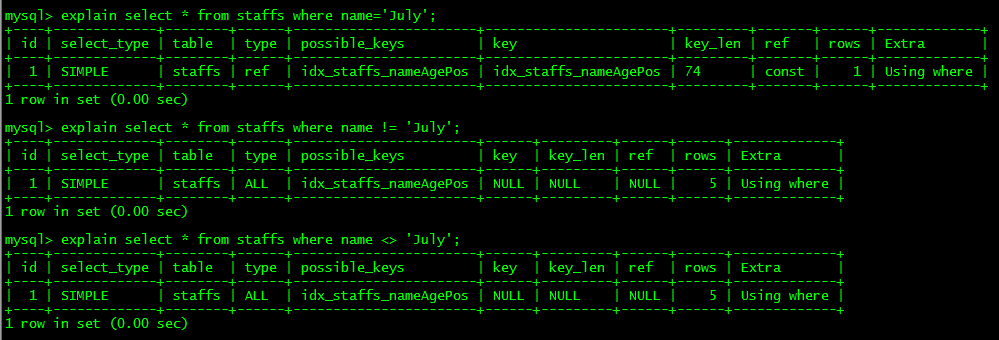
* 原本的name='July’時,使用的查詢型別type是ref非唯一性索引;*
當變成!=和<>後,轉為全表掃描ALL,索引失效;
7. 在建立table中資料時,欄位的null/not null,要與explain select where列表中欄位保持一致
eg:建立表時,插入資料,欄位a為null;
explain select where列表中欄位a not null;
查詢會出問題;
8. 字串不加單引號,索引會失效

name=‘917’,變成了name=917;優化器自動轉換欄位的型別,結果索引失效,key為NULL;
9. 少用or,用它來連線時,索引會失效