
深度學習與計算機視覺 看這一篇就夠了
來源:http://www.leiphone.com/news/201605/zZqsZiVpcBBPqcGG.html#rd
人工智慧是人類一個非常美好的夢想,跟星際漫遊和長生不老一樣。我們想製造出一種機器,使得它跟人一樣具有一定的對外界事物感知能力,比如看見世界。
在上世紀50年代,數學家圖靈提出判斷機器是否具有人工智慧的標準:圖靈測試。即把機器放在一個房間,人類測試員在另一個房間,人跟機器聊天,測試員事先不知道另一房間裡是人還是機器 。經過聊天,如果測試員不能確定跟他聊天的是人還是機器的話,那麼圖靈測試就通過了,也就是說這個機器具有與人一樣的感知能力。
但是從圖靈測試提出來開始到本世紀初,50多年時間有無數科學家提出很多機器學習的演算法,試圖讓計算機具有與人一樣的智力水平,但直到2006年深度學習演算法的成功,才帶來了一絲解決的希望。
眾星捧月的深度學習
深度學習在很多學術領域,比非深度學習演算法往往有20-30%成績的提高。很多大公司也逐漸開始出手投資這種演算法,併成立自己的深度學習團隊,其中投入最大的就是谷歌,2008年6月披露了谷歌腦專案。2014年1月谷歌收購DeepMind,然後2016年3月其開發的Alphago演算法在圍棋挑戰賽中,戰勝了韓國九段棋手李世石,證明深度學習設計出的演算法可以戰勝這個世界上最強的選手。
在硬體方面,Nvidia最開始做顯示晶片,但從2006及2007年開始主推用GPU晶片進行通用計算,它特別適合深度學習中大量簡單重複的計算量。目前很多人選擇Nvidia的CUDA工具包進行深度學習軟體的開發。
微軟從2012年開始,利用深度學習進行機器翻譯和中文語音合成工作,其人工智慧小娜背後就是一套自然語言處理和
百度在2013年宣佈成立百度研究院,其中最重要的就是百度深度學習研究所,當時招募了著名科學家餘凱博士。不過後來餘凱離開百度,創立了另一家從事深度學習演算法開發的公司地平線。
Facebook和Twitter也都各自進行了深度學習研究,其中前者攜手紐約大學教授Yann Lecun,建立了自己的深度學習演算法實驗室;2015年10月,Facebook宣佈開源其深度學習演算法框架,即Torch框架。Twitter在2014年7月收購了Madbits,為使用者提供高精度的影象檢索服務。
前深度學習時代的計算機視覺
網際網路巨頭看重深度學習當然不是為了學術,主要是它能帶來巨大的市場。那為什麼在深度學習出來之前,傳統演算法為什麼沒有達到深度學習的精度?
在深度學習演算法出來之前,對於視覺演算法來說,大致可以分為以下5個步驟:特徵感知,影象預處理,特徵提取,特徵篩選,推理預測與識別。早期的機器學習中,佔優勢的統計機器學習群體中,對特徵是不大關心的。
我認為,計算機視覺可以說是機器學習在視覺領域的應用,所以計算機視覺在採用這些機器學習方法的時候,不得不自己設計前面4個部分。
但對任何人來說這都是一個比較難的任務。傳統的計算機識別方法把特徵提取和分類器設計分開來做,然後在應用時再合在一起,比如如果輸入是一個摩托車影象的話,首先要有一個特徵表達或者特徵提取的過程,然後把表達出來的特徵放到學習演算法中進行分類的學習。
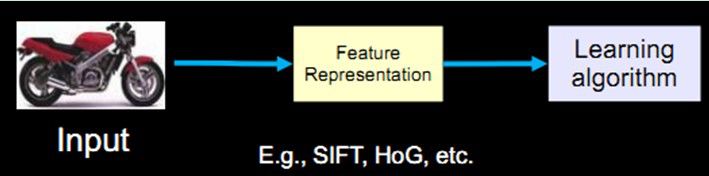
過去20年中出現了不少優秀的特徵運算元,比如最著名的SIFT運算元,即所謂的對尺度旋轉保持不變的運算元。它被廣泛地應用在影象比對,特別是所謂的structure from motion這些應用中,有一些成功的應用例子。另一個是HoG運算元,它可以提取物體,比較魯棒的物體邊緣,在物體檢測中扮演著重要的角色。
這些運算元還包括Textons,Spin image,RIFT和GLOH,都是在深度學習誕生之前或者深度學習真正的流行起來之前,佔領視覺演算法的主流。
幾個(半)成功例子
這些特徵和一些特定的分類器組合取得了一些成功或半成功的例子,基本達到了商業化的要求但還沒有完全商業化。
-
一是八九十年代的指紋識別演算法,它已經非常成熟,一般是在指紋的圖案上面去尋找一些關鍵點,尋找具有特殊幾何特徵的點,然後把兩個指紋的關鍵點進行比對,判斷是否匹配。
-
然後是2001年基於Haar的人臉檢測演算法,在當時的硬體條件下已經能夠達到實時人臉檢測,我們現在所有手機相機裡的人臉檢測,都是基於它或者它的變種。
-
第三個是基於HoG特徵的物體檢測,它和所對應的SVM分類器組合起來的就是著名的DPM演算法。DPM演算法在物體檢測上超過了所有的演算法,取得了比較不錯的成績。
但這種成功例子太少了,因為手工設計特徵需要大量的經驗,需要你對這個領域和資料特別瞭解,然後設計出來特徵還需要大量的除錯工作。說白了就是需要一點運氣。
另一個難點在於,你不只需要手工設計特徵,還要在此基礎上有一個比較合適的分類器演算法。同時設計特徵然後選擇一個分類器,這兩者合併達到最優的效果,幾乎是不可能完成的任務。
仿生學角度看深度學習
如果不手動設計特徵,不挑選分類器,有沒有別的方案呢?能不能同時學習特徵和分類器?即輸入某一個模型的時候,輸入只是圖片,輸出就是它自己的標籤。比如輸入一個明星的頭像,出來的標籤就是一個50維的向量(如果要在50個人裡識別的話),其中對應明星的向量是1,其他的位置是0。
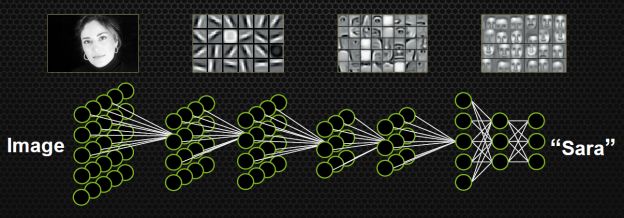
這種設定符合人類腦科學的研究成果。
1981年諾貝爾醫學生理學獎頒發給了David Hubel,一位神經生物學家。他的主要研究成果是發現了視覺系統資訊處理機制,證明大腦的可視皮層是分級的。他的貢獻主要有兩個,一是他認為人的視覺功能一個是抽象,一個是迭代。抽象就是把非常具體的形象的元素,即原始的光線畫素等資訊,抽象出來形成有意義的概念。這些有意義的概念又會往上迭代,變成更加抽象,人可以感知到的抽象概念。
畫素是沒有抽象意義的,但人腦可以把這些畫素連線成邊緣,邊緣相對畫素來說就變成了比較抽象的概念;邊緣進而形成球形,球形然後到氣球,又是一個抽象的過程,大腦最終就知道看到的是一個氣球。
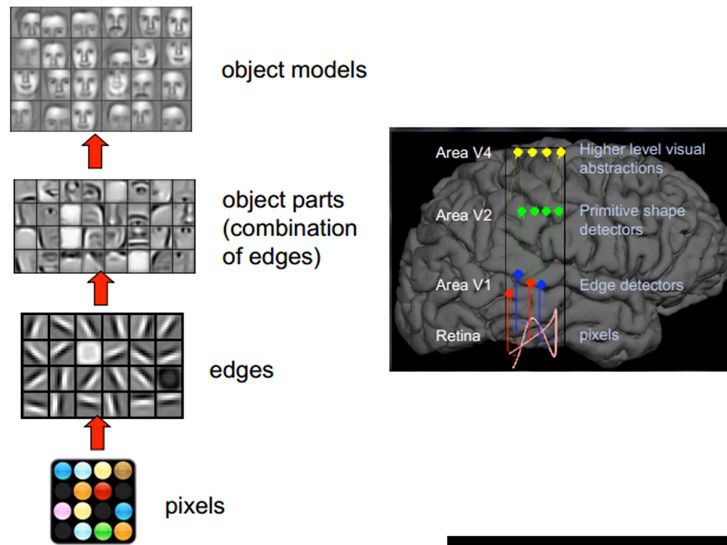
模擬人腦識別人臉,也是抽象迭代的過程,從最開始的畫素到第二層的邊緣,再到人臉的部分,然後到整張人臉,是一個抽象迭代的過程。
再比如看到圖片中的摩托車,我們可能在腦子裡就幾微秒的時間,但是經過了大量的神經元抽象迭代。對計算機來說最開始看到的根本也不是摩托車,而是RGB影象三個通道上不同的數字。
所謂的特徵或者視覺特徵,就是把這些數值給綜合起來用統計或非統計的形式,把摩托車的部件或者整輛摩托車表現出來。深度學習的流行之前,大部分的設計影象特徵就是基於此,即把一個區域內的畫素級別的資訊綜合表現出來,利於後面的分類學習。
如果要完全模擬人腦,我們也要模擬抽象和遞迴迭代的過程,把資訊從最細瑣的畫素級別,抽象到“種類”的概念,讓人能夠接受。
卷積的概念
計算機視覺裡經常使卷積神經網路,即CNN,是一種對人腦比較精準的模擬。
什麼是卷積?卷積就是兩個函式之間的相互關係,然後得出一個新的值,他是在連續空間做積分計算,然後在離散空間內求和的過程。實際上在計算機視覺裡面,可以把卷積當做一個抽象的過程,就是把小區域內的資訊統計抽象出來。
比如,對於一張愛因斯坦的照片,我可以學習n個不同的卷積和函式,然後對這個區域進行統計。可以用不同的方法統計,比如著重統計中央,也可以著重統計周圍,這就導致統計的和函式的種類多種多樣,為了達到可以同時學習多個統計的累積和。
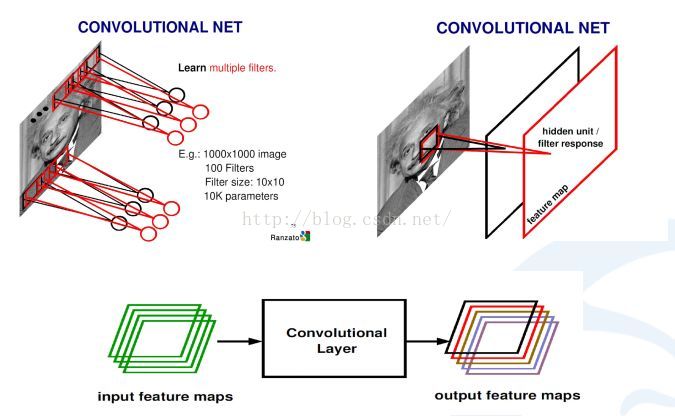
上圖中是,如何從輸入影象怎麼到最後的卷積,生成的響應map。首先用學習好的卷積和對影象進行掃描,然後每一個卷積和會生成一個掃描的響應圖,我們叫response map,或者叫feature map。如果有多個卷積和,就有多個feature map。也就說從一個最開始的輸入影象(RGB三個通道)可以得到256個通道的feature map,因為有256個卷積和,每個卷積和代表一種統計抽象的方式。
在卷積神經網路中,除了卷積層,還有一種叫池化的操作。池化操作在統計上的概念更明確,就是一個對一個小區域內求平均值或者求最大值的統計操作。
帶來的結果是,如果之前我輸入有兩個通道的,或者256通道的卷積的響應feature map,每一個feature map都經過一個求最大的一個池化層,會得到一個比原來feature map更小的256的feature map。
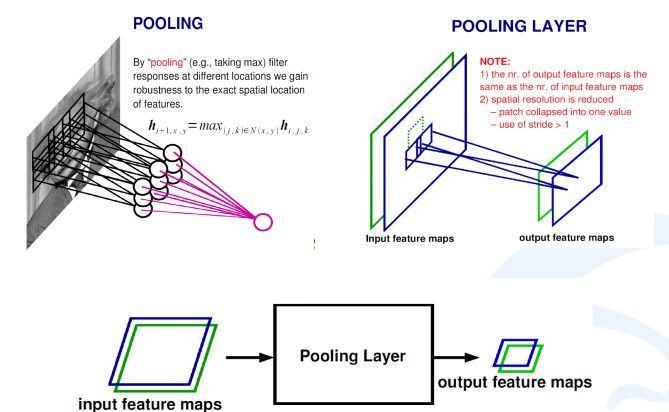
在上面這個例子裡,池化層對每一個2X2的區域求最大值,然後把最大值賦給生成的feature map的對應位置。如果輸入影象是100×100的話,那輸出影象就會變成50×50,feature map變成了一半。同時保留的資訊是原來2X2區域裡面最大的資訊。
操作的例項:LeNet網路
Le顧名思義就是指人工智慧領域的大牛Lecun。這個網路是深度學習網路的最初原型,因為之前的網路都比較淺,它較深的。LeNet在98年就發明出來了,當時Lecun在AT&T的實驗室,他用這一網路進行字母識別,達到了非常好的效果。
怎麼構成呢?輸入影象是32×32的灰度圖,第一層經過了一組卷積和,生成了6個28X28的feature map,然後經過一個池化層,得到得到6個14X14的feature map,然後再經過一個卷積層,生成了16個10X10的卷積層,再經過池化層生成16個5×5的feature map。
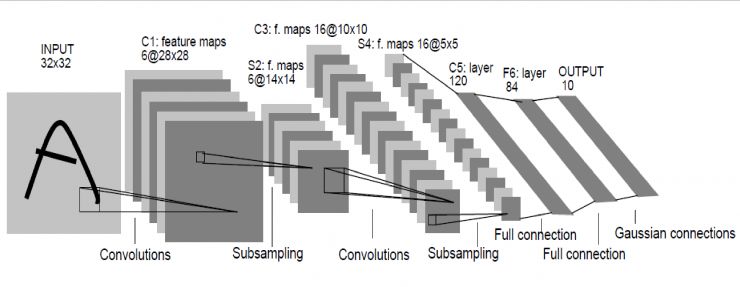
從最後16個5X5的feature map開始,經過了3個全連線層,達到最後的輸出,輸出就是標籤空間的輸出。由於設計的是隻要對0到9進行識別,所以輸出空間是10,如果要對10個數字再加上26個大小字母進行識別的話,輸出空間就是62。62維向量裡,如果某一個維度上的值最大,它對應的那個字母和數字就是就是預測結果。
壓在駱駝身上的最後一根稻草
從98年到本世紀初,深度學習興盛起來用了15年,但當時成果泛善可陳,一度被邊緣化。到2012年,深度學習演算法在部分領域取得不錯的成績,而壓在駱駝身上最後一根稻草就是AlexNet。
AlexNet由多倫多大學幾個科學家開發,在ImageNet比賽上做到了非常好的效果。當時AlexNet識別效果超過了所有淺層的方法。此後,大家認識到深度學習的時代終於來了,並有人用它做其它的應用,同時也有些人開始開發新的網路結構。
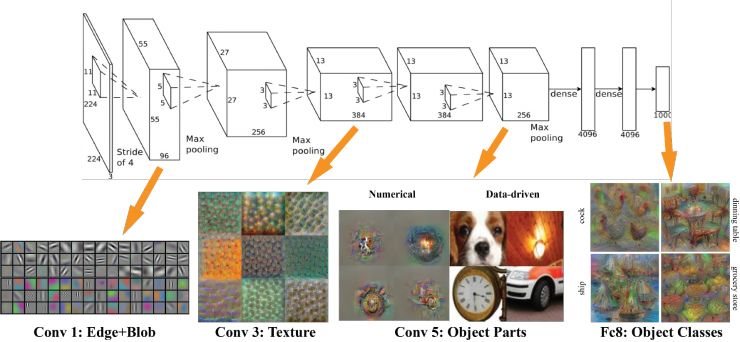
其實AlexNet的結構也很簡單,只是LeNet的放大版。輸入是一個224X224的圖片,是經過了若干個卷積層,若干個池化層,最後連線了兩個全連線層,達到了最後的標籤空間。
去年,有些人研究出來怎麼樣視覺化深度學習出來的特徵。那麼,AlexNet學習出的特徵是什麼樣子?在第一層,都是一些填充的塊狀物和邊界等特徵;中間的層開始學習一些紋理特徵;更高接近分類器的層級,則可以明顯看到的物體形狀的特徵。
最後的一層,即分類層,完全是物體的不同的姿態,根據不同的物體展現出不同姿態的特徵了。
可以說,不論是對人臉,車輛,大象或椅子進行識別,最開始學到的東西都是邊緣,繼而就是物體的部分,然後在更高層層級才能抽象到物體的整體。整個卷積神經網路在模擬人的抽象和迭代的過程。
為什麼時隔20年捲土重來?
我們不禁要問:似乎卷積神經網路設計也不是很複雜,98年就已經有一個比較像樣的雛形了。自由換演算法和理論證明也沒有太多進展。那為什麼時隔20年,卷積神經網路才能捲土重來,佔領主流?
這一問題與卷積神經網路本身的技術關係不太大,我個人認為與其他一些客觀因素有關。
-
首先,卷積神經網路的深度太淺的話,識別能力往往不如一般的淺層模型,比如SVM或者boosting。但如果做得很深,就需要大量資料進行訓練,否則機器學習中的過擬合將不可避免。而2006及2007年開始,正好是網際網路開始大量產生各種各樣的圖片資料的時候。
-
另外一個條件是運算能力。卷積神經網路對計算機的運算要求比較高,需要大量重複可並行化的計算,在當時CPU只有單核且運算能力比較低的情況下,不可能進行個很深的卷積神經網路的訓練。隨著GPU計算能力的增長,卷積神經網路結合大資料的訓練才成為可能。
-
最後一點就是人和。卷積神經網路有一批一直在堅持的科學家(如Lecun)才沒有被沉默,才沒有被海量的淺層方法淹沒。然後最後終於看到卷積神經網路佔領主流的曙光。
深度學習在視覺上的應用
計算機視覺中比較成功的深度學習的應用,包括人臉識別,影象問答,物體檢測,物體跟蹤。
人臉識別
這裡說人臉識別中的人臉比對,即得到一張人臉,與資料庫裡的人臉進行比對;或同時給兩張人臉,判斷是不是同一個人。
這方面比較超前的是湯曉鷗教授,他們提出的DeepID演算法在LWF上做得比較好。他們也是用卷積神經網路,但在做比對時,兩張人臉分別提取了不同位置特徵,然後再進行互相比對,得到最後的比對結果。最新的DeepID-3演算法,在LWF達到了99.53%準確度,與肉眼識別結果相差無幾。
圖片問答問題
這是2014年左右興起的課題,即給張圖片同時問個問題,然後讓計算機回答。比如有一個辦公室靠海的圖片,然後問“桌子後面有什麼”,神經網路輸出應該是“椅子和窗戶”。
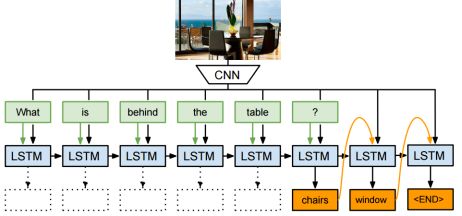
這一應用引入了LSTM網路,這是一個專門設計出來具有一定記憶能力的神經單元。特點是,會把某一個時刻的輸出當作下一個時刻的輸入。可以認為它比較適合語言等,有時間序列關係的場景。因為我們在讀一篇文章和句子的時候,對句子後面的理解是基於前面對詞語的記憶。
影象問答問題是基於卷積神經網路和LSTM單元的結合,來實現影象問答。LSTM輸出就應該是想要的答案,而輸入的就是上一個時刻的輸入,以及影象的特徵,及問句的每個詞語。
物體檢測問題
Region CNN
深度學習在物體檢測方面也取得了非常好的成果。2014年的Region CNN演算法,基本思想是首先用一個非深度的方法,在影象中提取可能是物體的圖形塊,然後深度學習演算法根據這些影象塊,判斷屬性和一個具體物體的位置。
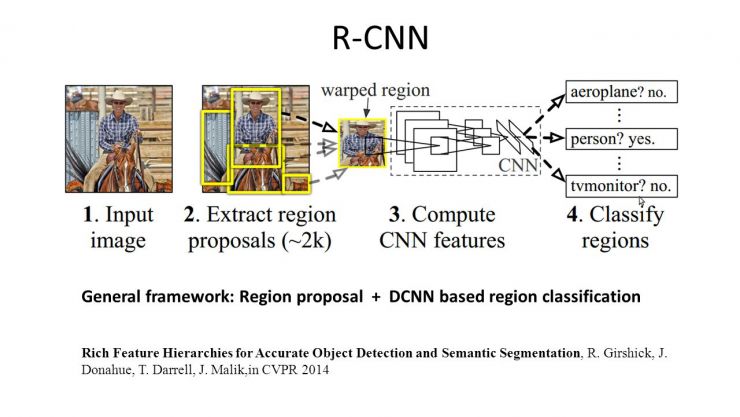
為什麼要用非深度的方法先提取可能的影象塊?因為在做物體檢測的時候,如果你用掃描窗的方法進行物體監測,要考慮到掃描窗大小的不一樣,長寬比和位置不一樣,如果每一個影象塊都要過一遍深度網路的話,這種時間是你無法接受的。
所以用了一個折中的方法,叫Selective Search。先把完全不可能是物體的影象塊去除,只剩2000左右的影象塊放到深度網路裡面判斷。那麼取得的成績是AP是58.5,比以往幾乎翻了一倍。有一點不盡如人意的是,region CNN的速度非常慢,需要10到45秒處理一張圖片。
Faster R-CNN方法
而且我在去年NIPS上,我們看到的有Faster R-CNN方法,一個超級加速版R-CNN方法。它的速度達到了每秒七幀,即一秒鐘可以處理七張圖片。技巧在於,不是用影象塊來判斷是物體還是背景,而把整張影象一起扔進深度網路裡,讓深度網路自行判斷哪裡有物體,物體的方塊在哪裡,種類是什麼?
經過深度網路運算的次數從原來的2000次降到一次,速度大大提高了。
Faster R-CNN提出了讓深度學習自己生成可能的物體塊,再用同樣深度網路來判斷物體塊是否是背景?同時進行分類,還要把邊界和給估計出來。
Faster R-CNN可以做到又快又好,在VOC2007上檢測AP達到73.2,速度也提高了兩三百倍。
YOLO
去年FACEBOOK提出來的YOLO網路,也是進行物體檢測,最快達到每秒鐘155幀,達到了完全實時。它讓一整張影象進入到神經網路,讓神經網路自己判斷這物體可能在哪裡,可能是什麼。但它縮減了可能影象塊的個數,從原來Faster R-CNN的2000多個縮減縮減到了98個。
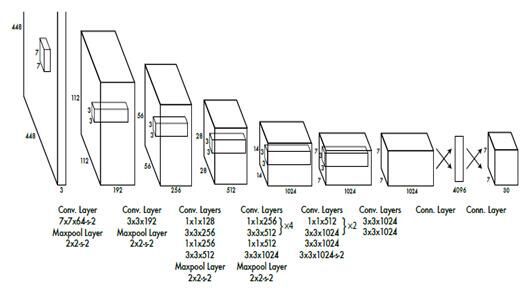
同時取消了Faster R-CNN裡面的RPN接面構,代替Selective Search結構。YOLO裡面沒有RPN這一步,而是直接預測物體的種類和位置。
YOLO的代價就是精度下降,在155幀的速度下精度只有52.7,45幀每秒時的精度是63.4。
SSD
在arXiv上出現的最新演算法叫Single Shot MultiBox Detector,即SSD。
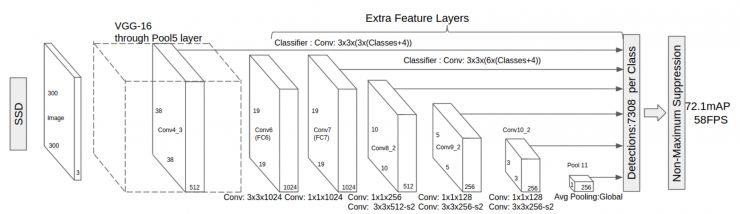
它是YOLO的超級改進版,吸取了YOLO的精度下降的教訓,同時保留速度快的特點。它能達到58幀每秒,精度有72.1。速度超過Faster R-CNN 有8倍,但達到類似的精度。
物體跟蹤
所謂跟蹤,就是在視訊裡面第一幀時鎖定感興趣的物體,讓計算機跟著走,不管怎麼旋轉晃動,甚至躲在樹叢後面也要跟蹤。
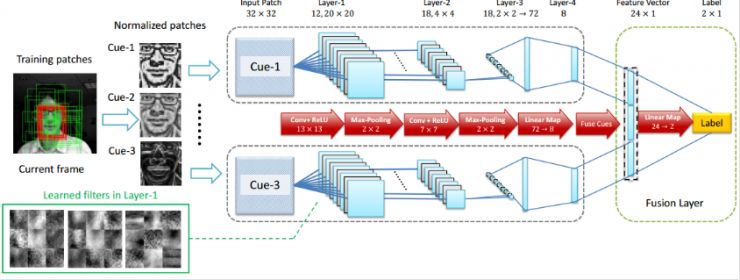
深度學習對跟蹤問題有很顯著的效果。DeepTrack演算法是我在澳大利亞資訊科技研究院時和同事提出的,是第一線上用深度學習進行跟蹤的文章,當時超過了其它所有的淺層演算法。
今年有越來越多深度學習跟蹤演算法提出。去年十二月ICCV 2015上面,馬超提出的Hierarchical Convolutional Feature演算法,在資料上達到最新的記錄。它不是線上更新一個深度學習網路,而是用一個大網路進行預訓練,然後讓大網路知道什麼是物體什麼不是物體。
將大網路放在跟蹤視訊上面,然後再分析網路在視訊上產生的不同特徵,用比較成熟的淺層跟蹤演算法來進行跟蹤,這樣利用了深度學習特徵學習比較好的好處,同時又利用了淺層方法速度較快的優點。效果是每秒鐘10幀,同時精度破了記錄。
最新的跟蹤成果是基於Hierarchical Convolutional Feature,由一個韓國的科研組提出的MDnet。它集合了前面兩種深度演算法的集大成,首先離線的時候有學習,學習的不是一般的物體檢測,也不是ImageNet,學習的是跟蹤視訊,然後在學習視訊結束後,在真正在使用網路的時候更新網路的一部分。這樣既在離線的時候得到了大量的訓練,線上的時候又能夠很靈活改變自己的網路。
基於嵌入式系統的深度學習
回到ADAS問題(慧眼科技的主業),它完全可以用深度學習演算法,但對硬體平臺有比較高的要求。在汽車上不太可能把一臺電腦放上去,因為功率是個問題,很難被市場所接受。
現在的深度學習計算主要是在雲端進行,前端拍攝照片,傳給後端的雲平臺處理。但對於ADAS而言,無法接受長時間的資料傳輸的,或許發生事故後,雲端的資料還沒傳回來。
那是否可以考慮NVIDIA推出的嵌入式平臺?NVIDIA推出的嵌入式平臺,其運算能力遠遠強過了所有主流的嵌入式平臺,運算能力接近主流的頂級CPU,如桌上型電腦的i7。那麼慧眼科技在做工作就是要使得深度學習演算法,在嵌入式平臺有限的資源情況下能夠達到實時效果,而且精度幾乎沒有減少。
具體做法是,首先對網路進行縮減,可能是對網路的結構縮減,由於識別場景不同,也要進行相應的功能性縮減;另外要用最快的深度檢測演算法,結合最快的深度跟蹤演算法,同時自己研發出一些場景分析演算法。三者結合在一起,目的是減少運算量,減少檢測空間的大小。在這種情況下,在有限資源上實現了使用深度學習演算法,但精度減少的非常少。