
python Deep learning 學習筆記(4)
本節講卷積神經網路的視覺化
三種方法
視覺化卷積神經網路的中間輸出(中間啟用)
有助於理解卷積神經網路連續的層如何對輸入進行變換,也有助於初步瞭解卷積神經網路每個過濾器的含義
視覺化卷積神經網路的過濾器
有助於精確理解卷積神經網路中每個過濾器容易接受的視覺模式或視覺概念
視覺化影象中類啟用的熱力圖
有助於理解影象的哪個部分被識別為屬於某個類別,從而可以定點陣圖像中的物體
視覺化中間啟用
是指對於給定輸入,展示網路中各個卷積層和池化層輸出的特徵圖,這讓我們可以看到輸入如何被分解為網路學到的不同過濾器。我們希望在三個維度對特徵圖進行視覺化:寬度、高度和深度(通道)。每個通道都對應相對獨立的特徵,所以將這些特徵圖視覺化的正確方法是將每個通道的內容分別繪製成二維影象
Keras載入模型方法
from keras.models import load_model
model = load_model('cats_and_dogs_small_2.h5')視覺化方法
from keras.models import load_model from keras.preprocessing import image import numpy as np import matplotlib.pyplot as plt from keras import models model = load_model('dogVScat.h5') # 檢視模型 model.summary() img_path = "C:\\Users\\fan\\Desktop\\testDogVSCat\\test\\cats\\cat.1700.jpg" img = image.load_img(img_path, target_size=(150, 150)) img_tensor = image.img_to_array(img) img_tensor = np.expand_dims(img_tensor, axis=0) img_tensor /= 255 # shape(1, 150, 150, 3) print(img_tensor.shape) plt.title("original cat") plt.imshow(img_tensor[0]) plt.show() # 提取前 8 層的輸出 layer_outputs = [layer.output for layer in model.layers[:8]] # 建立一個模型,給定模型輸入,可以返回這些輸出 activation_model = models.Model(inputs=model.input, outputs=layer_outputs) # 返回8個Numpy陣列組成的列表,每個層啟用對應一個 Numpy 陣列 activations = activation_model.predict(img_tensor) first_layer_activation = activations[0] # 將第 4 個通道視覺化 plt.matshow(first_layer_activation[0, :, :, 4]) plt.show() # 將每個中間啟用的所有通道視覺化 layer_names = [] for layer in model.layers[:8]: layer_names.append(layer.name) images_per_row = 16 for layer_name, layer_activation in zip(layer_names, activations): # 特徵圖中的特徵個數 n_features = layer_activation.shape[-1] size = layer_activation.shape[1] # 在這個矩陣中將啟用通道平鋪 n_cols = n_features // images_per_row display_grid = np.zeros((size * n_cols, images_per_row * size)) for col in range(n_cols): for row in range(images_per_row): channel_image = layer_activation[0, :, :, col * images_per_row + row] # 對特徵進行後處理,使其看起來更美觀 channel_image -= channel_image.mean() if channel_image.std() != 0: channel_image /= channel_image.std() channel_image *= 64 channel_image += 128 channel_image = np.clip(channel_image, 0, 255).astype('uint8') display_grid[col * size: (col + 1) * size, row * size: (row + 1) * size] = channel_image scale = 1. / size plt.figure(figsize=(scale * display_grid.shape[1], scale * display_grid.shape[0])) plt.title(layer_name) plt.grid(False) plt.imshow(display_grid, aspect='auto', cmap='viridis') plt.show()
結果
原始貓
模型,使用之上第一個介紹的貓狗二分類的模型
第一層

第四層

第七層

第八層
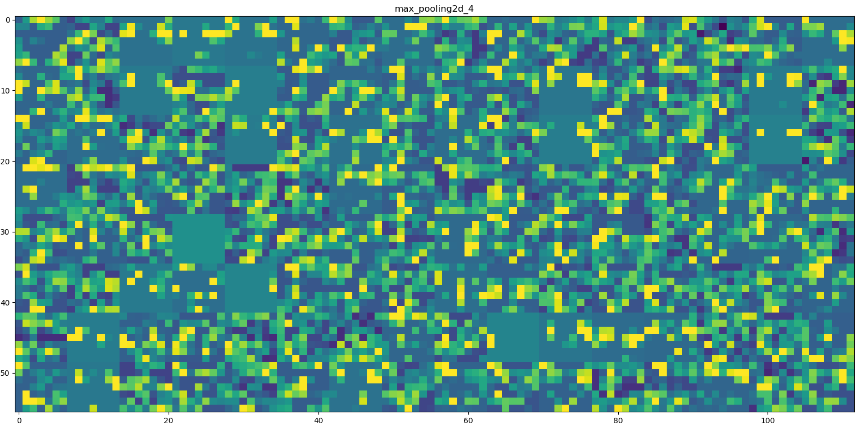
隨著層數的加深,啟用變得越來越抽象,並且越來越難以直觀地理解。它們開始表示更高層次的概念
即,隨著層數的加深,層所提取的特徵變得越來越抽象。更高的層啟用包含關於特定輸入的資訊越來越少,而關於目標的資訊越來越多
視覺化卷積神經網路的過濾器
想要觀察卷積神經網路學到的過濾器,另一種簡單的方法是顯示每個過濾器所響應的視覺模式。這可以通過在輸入空間中進行梯度上升來實現:從空白輸入影象開始,將梯度下降應用於卷積神經網路輸入影象的值,其目的是讓某個過濾器的響應最大化。得到的輸入影象是選定過濾器具有最大響應的影象
過程
首先,需要構建一個損失函式,其目的是讓某個卷積層的某個過濾器的值最大化;然後,我們要使用隨機梯度下降來調節輸入影象的值,以便讓這個啟用值最大化
from keras import backend as K
import numpy as np
from keras.applications import VGG16
import matplotlib.pyplot as plt
from keras.preprocessing import image
# 將張量轉換為有效影象
def deprocess_image(x):
x -= x.mean()
x /= (x.std() + 1e-5)
x *= 0.1
x += 0.5
# 將 x 裁切(clip)到 [0, 1] 區間
x = np.clip(x, 0, 1)
x *= 255
# 將 x 轉換為 RGB 陣列
x = np.clip(x, 0, 255).astype('uint8')
return x
# 生成過濾器視覺化
def generate_pattern(layer_name, filter_index, size=150):
layer_output = model.get_layer(layer_name).output
loss = K.mean(layer_output[:, :, :, filter_index])
grads = K.gradients(loss, model.input)[0]
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5)
iterate = K.function([model.input], [loss, grads])
input_img_data = np.random.random((1, size, size, 3)) * 20 + 128.
step = 1.
for i in range(40):
loss_value, grads_value = iterate([input_img_data])
input_img_data += grads_value * step
img = input_img_data[0]
return deprocess_image(img)
# 為過濾器的視覺化定義損失張量
model = VGG16(weights='imagenet', include_top=False)
layer_name = 'block3_conv1'
filter_index = 0
layer_output = model.get_layer(layer_name).output
loss = K.mean(layer_output[:, :, :, filter_index])
# 獲取損失相對於輸入的梯度
grads = K.gradients(loss, model.input)[0]
# 將梯度張量除以其 L2 範數來標準化
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5)
# 給定 Numpy 輸入值,得到 Numpy 輸出值
iterate = K.function([model.input], [loss, grads])
loss_value, grads_value = iterate([np.zeros((1, 150, 150, 3))])
# 通過隨機梯度下降讓損失最大化
# 從一個帶噪聲的隨機影象開始
input_img_data = np.random.random((1, 150, 150, 3)) * 20 + 128.
plt.imshow(image.array_to_img(input_img_data[0]))
plt.show()
step = 1.
for i in range(40):
loss_value, grads_value = iterate([input_img_data])
input_img_data += grads_value * step
def draw_layer_filter(layer_name):
size = 64
margin = 5
results = np.zeros((8 * size + 7 * margin, 8 * size + 7 * margin, 3))
for i in range(8):
for j in range(8):
filter_img = generate_pattern(layer_name, i + (j * 8), size=size)
horizontal_start = i * size + i * margin
horizontal_end = horizontal_start + size
vertical_start = j * size + j * margin
vertical_end = vertical_start + size
results[horizontal_start: horizontal_end, vertical_start: vertical_end, :] = filter_img
plt.figure(figsize=(20, 20))
results = image.array_to_img(results)
plt.imshow(results)
plt.show()
draw_layer_filter(layer_name='block1_conv1')
draw_layer_filter(layer_name='block4_conv1')
結果
輸入影象
過濾器: block1_conv1

過濾器:block4_conv1

通過對比發現
模型第一層(block1_conv1)的過濾器對應簡單的方向邊緣和顏色(還有一些是彩色邊緣)
高層的過濾器類似於自然影象中的紋理
視覺化類啟用的熱力圖
這種視覺化方法有助於瞭解一張影象的哪一部分讓卷積神經網路做出了最終的分類決策。這有助於對卷積神經網路的決策過程進行除錯,特別是出現分類錯誤的情況下。這種方法還可以定點陣圖像中的特定目標
這種通用的技術叫作類啟用圖(CAM,class activation map)視覺化,它是指對輸入影象生成類啟用的熱力圖。類啟用熱力圖是與特定輸出類別相關的二維分數網格,對任何輸入影象的每個位置都要進行計算,它表示每個位置對該類別的重要程度
一種方法
給定一張輸入影象,對於一個卷積層的輸出特徵圖,用類別相對於通道的梯度對這個特徵圖中的每個通道進行加權
from keras.applications.vgg16 import VGG16
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input, decode_predictions
import numpy as np
from keras import backend as K
import matplotlib.pyplot as plt
from PIL import Image
import cv2
model = VGG16(weights='imagenet')
img_path = 'E:\\study\\研究生\\筆記\\studyNote\\bookStudy\\bookNote\\imgs\\testImg.png'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
# 新增一個維度,將陣列轉換為(1, 224, 224, 3) 形狀的批量
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
preds = model.predict(x)
print('Predicted:', decode_predictions(preds, top=3)[0])
# 索引編號
np.argmax(preds[0])
# 來使用 Grad-CAM 演算法展示影象中哪些部分最像非洲象
african_elephant_output = model.output[:, 386]
last_conv_layer = model.get_layer('block5_conv3')
grads = K.gradients(african_elephant_output, last_conv_layer.output)[0]
pooled_grads = K.mean(grads, axis=(0, 1, 2))
iterate = K.function([model.input], [pooled_grads, last_conv_layer.output[0]])
pooled_grads_value, conv_layer_output_value = iterate([x])
for i in range(512):
conv_layer_output_value[:, :, i] *= pooled_grads_value[i]
heatmap = np.mean(conv_layer_output_value, axis=-1)
# 熱力圖後處理
heatmap = np.maximum(heatmap, 0)
heatmap /= np.max(heatmap)
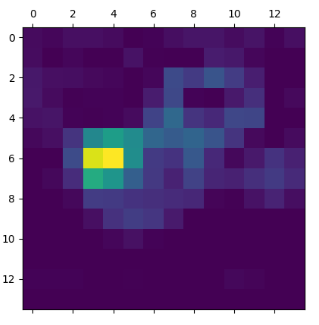
plt.matshow(heatmap)
plt.show()
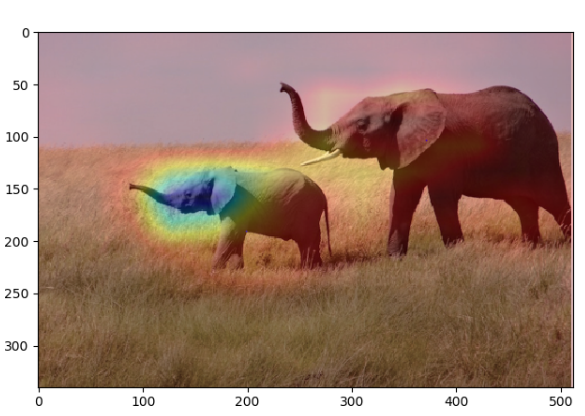
# 將熱力圖與原始影象疊加
img = Image.open(img_path).convert('RGB')
img = np.array(img)
heatmap = cv2.resize(heatmap, (img.shape[1], img.shape[0]))
heatmap = np.uint8(255 * heatmap)
heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET)
superimposed_img = heatmap * 0.4 + img
cv2.imwrite('elephant_cam.jpg', superimposed_img)
superimposed_img = image.array_to_img(superimposed_img)
plt.imshow(superimposed_img)
plt.show()
原始影象

熱力圖
混合影象
儲存的影象

此處儲存的影象和顯示的影象不一致