Excel 檔案資料讀取和篩選
阿新 • • 發佈:2018-11-19
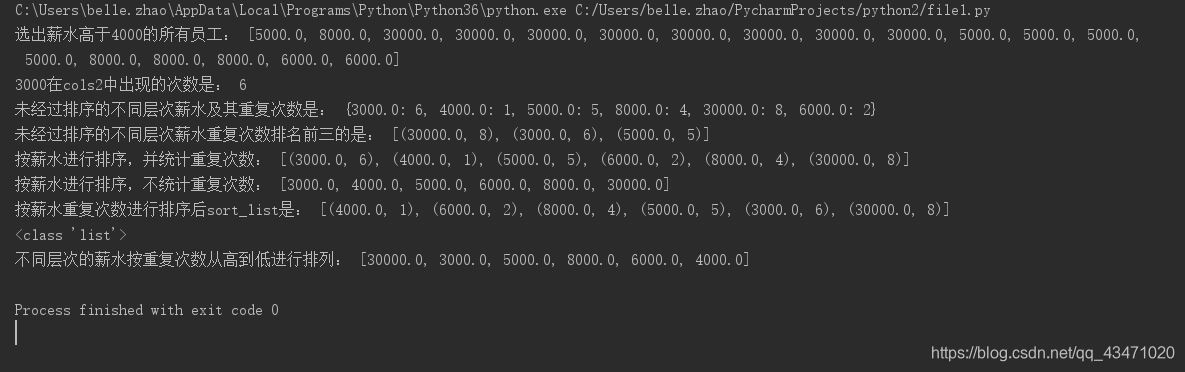
需求:已知一個excel 表中的"Sheet1"中,有id, name, salary 3列的內容,要求將薪水重複次數最多的按從高到低進行排序
#coding=utf-8
import xlrd
from collections import Counter
import operator
file = r'C:\\Users\\belle.zhao\\Desktop\\test.xlsx'
data = xlrd.open_workbook('C:\\Users\\belle.zhao\\Desktop\\test.xlsx','rb') # 開啟excel檔案
table = 執行結果如下: