
SQL——語法基礎篇(上)
用資料庫的方式思考SQL是如何執行的
雖然 SQL 是宣告式語言,我們可以像使用英語一樣使用它,不過在 RDBMS(關係型資料庫管理系統)中,SQL 的實現方式還是有差別的。今天我們就從資料庫的角度來思考一下 SQL 是如何被執行的。
Oracle 中的 SQL 是如何執行的
我們先來看下 SQL 在 Oracle 中的執行過程:
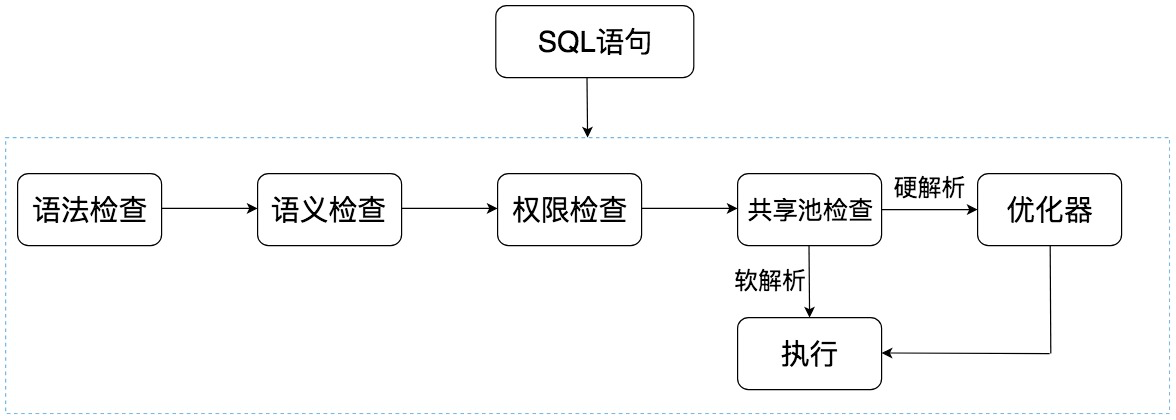
從上面這張圖中可以看出,SQL 語句在 Oracle 中經歷了以下的幾個步驟。
-
語法檢查:檢查 SQL 拼寫是否正確,如果不正確,Oracle 會報語法錯誤。
-
語義檢查:檢查 SQL 中的訪問物件是否存在。比如我們在寫 SELECT 語句的時候,列名寫錯了,系統就會提示錯誤。語法檢查和語義檢查的作用是保證 SQL 語句沒有錯誤。
-
許可權檢查:看使用者是否具備訪問該資料的許可權。
-
共享池檢查:共享池(Shared Pool)是一塊記憶體池,最主要的作用是快取 SQL 語句和該語句的執行計劃。Oracle 通過檢查共享池是否存在 SQL 語句的執行計劃,來判斷進行軟解析,還是硬解析。那軟解析和硬解析又該怎麼理解呢?
在共享池中,Oracle 首先對 SQL 語句進行 Hash 運算,然後根據 Hash 值在庫快取(Library Cache)中查詢,如果存在 SQL 語句的執行計劃,就直接拿來執行,直接進入“執行器”的環節,這就是軟解析。
如果沒有找到 SQL 語句和執行計劃,Oracle 就需要建立解析樹進行解析,生成執行計劃,進入“優化器”這個步驟,這就是硬解析。
-
優化器:優化器中就是要進行硬解析,也就是決定怎麼做,比如建立解析樹,生成執行計劃。
-
執行器:當有了解析樹和執行計劃之後,就知道了 SQL 該怎麼被執行,這樣就可以在執行器中執行語句了。
共享池是 Oracle 中的術語,包括了庫快取,資料字典緩衝區等。我們上面已經講到了庫快取區,它主要快取 SQL 語句和執行計劃。而資料字典緩衝區儲存的是 Oracle 中的物件定義,比如表、檢視、索引等物件。當對 SQL 語句進行解析的時候,如果需要相關的資料,會從資料字典緩衝區中提取。
庫快取這一個步驟,決定了 SQL 語句是否需要進行硬解析。為了提升 SQL 的執行效率,我們應該儘量避免硬解析,因為在 SQL 的執行過程中,建立解析樹,生成執行計劃是很消耗資源的。
如何避免硬解析,儘量使用軟解析呢?在 Oracle 中,繫結變數是它的一大特色。繫結變數就是在 SQL 語句中使用變數,通過不同的變數取值來改變 SQL 的執行結果。這樣做的好處是能提升軟解析的可能性,不足之處在於可能會導致生成的執行計劃不夠優化,因此是否需要繫結變數還需要視情況而定。
舉個例子,我們可以使用下面的查詢語句:
SQL> select * from player where player_id = 10001;
你也可以使用繫結變數,如:
SQL> select * from player where player_id = :player_id;
這兩個查詢語句的效率在 Oracle 中是完全不同的。如果你在查詢 player_id = 10001 之後,還會查詢 10002、10003 之類的資料,那麼每一次查詢都會建立一個新的查詢解析。而第二種方式使用了繫結變數,那麼在第一次查詢之後,在共享池中就會存在這類查詢的執行計劃,也就是軟解析。
因此我們可以通過使用繫結變數來減少硬解析,減少 Oracle 的解析工作量。但是這種方式也有缺點,使用動態 SQL 的方式,因為引數不同,會導致 SQL 的執行效率不同,同時 SQL 優化也會比較困難。
MySQL 中的 SQL 是如何執行的
Oracle 中採用了共享池來判斷 SQL 語句是否存在快取和執行計劃,通過這一步驟我們可以知道應該採用硬解析還是軟解析。那麼在 MySQL 中,SQL 是如何被執行的呢?
首先 MySQL 是典型的 C/S 架構,即 Client/Server 架構,伺服器端程式使用的 mysqld。整體的 MySQL 流程如下圖所示:

你能看到 MySQL 由三層組成:
- 連線層:客戶端和伺服器端建立連線,客戶端傳送 SQL 至伺服器端;
- SQL 層:對 SQL 語句進行查詢處理;
- 儲存引擎層:與資料庫檔案打交道,負責資料的儲存和讀取。
其中 SQL 層與資料庫檔案的儲存方式無關,我們來看下 SQL 層的結構:
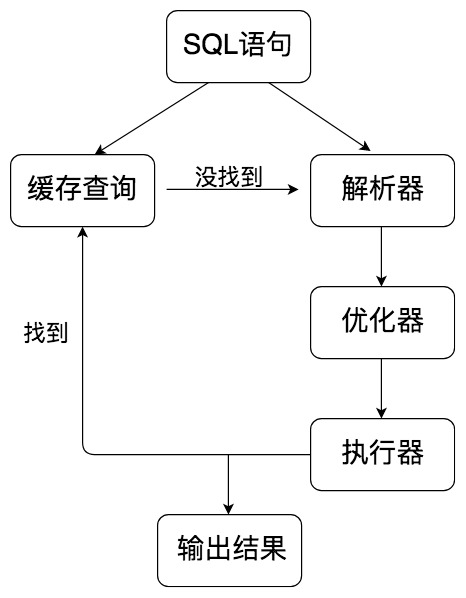
- 查詢快取:Server 如果在查詢快取中發現了這條 SQL 語句,就會直接將結果返回給客戶端;如果沒有,就進入到解析器階段。需要說明的是,因為查詢快取往往效率不高,所以在 MySQL8.0 之後就拋棄了這個功能。
- 解析器:在解析器中對 SQL 語句進行語法分析、語義分析。
- 優化器:在優化器中會確定 SQL 語句的執行路徑,比如是根據全表檢索,還是根據索引來檢索等。
- 執行器:在執行之前需要判斷該使用者是否具備許可權,如果具備許可權就執行 SQL 查詢並返回結果。在 MySQL8.0 以下的版本,如果設定了查詢快取,這時會將查詢結果進行快取。
你能看到 SQL 語句在 MySQL 中的流程是:SQL 語句→快取查詢→解析器→優化器→執行器。在一部分中,MySQL 和 Oracle 執行 SQL 的原理是一樣的。
與 Oracle 不同的是,MySQL 的儲存引擎採用了外掛的形式,每個儲存引擎都面向一種特定的資料庫應用環境。同時開源的 MySQL 還允許開發人員設定自己的儲存引擎,下面是一些常見的儲存引擎:
- InnoDB 儲存引擎:它是 MySQL 5.5 版本之後預設的儲存引擎,最大的特點是支援事務、行級鎖定、外來鍵約束等。
- MyISAM 儲存引擎:在 MySQL 5.5 版本之前是預設的儲存引擎,不支援事務,也不支援外來鍵,最大的特點是速度快,佔用資源少。
- Memory 儲存引擎:使用系統記憶體作為儲存介質,以便得到更快的響應速度。不過如果 mysqld 程序崩潰,則會導致所有的資料丟失,因此我們只有當資料是臨時的情況下才使用 Memory 儲存引擎。
- NDB 儲存引擎:也叫做 NDB Cluster 儲存引擎,主要用於 MySQL Cluster 分散式叢集環境,類似於 Oracle 的 RAC 叢集。
- Archive 儲存引擎:它有很好的壓縮機制,用於檔案歸檔,在請求寫入時會進行壓縮,所以也經常用來做倉庫。
需要注意的是,資料庫的設計在於表的設計,而在 MySQL 中每個表的設計都可以採用不同的儲存引擎,我們可以根據實際的資料處理需要來選擇儲存引擎,這也是 MySQL 的強大之處。
資料庫管理系統也是一種軟體
我們剛才瞭解了 SQL 語句在 Oracle 和 MySQL 中的執行流程,實際上完整的 Oracle 和 MySQL 結構圖要複雜得多
如果你只是簡單地把 MySQL 和 Oracle 看成資料庫管理系統軟體,從外部看難免會覺得“晦澀難懂”,畢竟組織結構太多了。我們在學習的時候,還需要具備抽象的能力,抓取最核心的部分:SQL 的執行原理。因為不同的 DBMS 的 SQL 的執行原理是相通的,只是在不同的軟體中,各有各的實現路徑。
既然一條 SQL 語句會經歷不同的模組,那我們就來看下,在不同的模組中,SQL 執行所使用的資源(時間)是怎樣的。下面我來教你如何在 MySQL 中對一條 SQL 語句的執行時間進行分析。
首先我們需要看下 profiling 是否開啟,開啟它可以讓 MySQL 收集在 SQL 執行時所使用的資源情況,命令如下:
mysql> select @@profiling;
profiling=0 代表關閉,我們需要把 profiling 開啟,即設定為 1:
mysql> set profiling=1;
然後我們執行一個 SQL 查詢(你可以執行任何一個 SQL 查詢):
mysql> select * from wucai.heros;
檢視當前會話所產生的所有 profiles:
你會發現我們剛才執行了兩次查詢,Query ID 分別為 1 和 2。如果我們想要獲取上一次查詢的執行時間,可以使用:
mysql> show profile;
當然你也可以查詢指定的 Query ID,比如:
mysql> show profile for query 2;
查詢 SQL 的執行時間結果和上面是一樣的。
在 8.0 版本之後,MySQL 不再支援快取的查詢,原因我在上文已經說過。一旦資料表有更新,快取都將清空,因此只有資料表是靜態的時候,或者資料表很少發生變化時,使用快取查詢才有價值,否則如果資料表經常更新,反而增加了 SQL 的查詢時間。
你可以使用 select version() 來檢視 MySQL 的版本情況。
總結
我們在使用 SQL 的時候,往往只見樹木,不見森林,不會注意到它在各種資料庫軟體中是如何執行的,今天我們從全貌的角度來理解這個問題。你能看到不同的 RDBMS 之間有相同的地方,也有不同的地方。
相同的地方在於 Oracle 和 MySQL 都是通過解析器→優化器→執行器這樣的流程來執行 SQL 的。
但 Oracle 和 MySQL 在進行 SQL 的查詢上面有軟體實現層面的差異。Oracle 提出了共享池的概念,通過共享池來判斷是進行軟解析,還是硬解析。而在 MySQL 中,8.0 以後的版本不再支援查詢快取,而是直接執行解析器→優化器→執行器的流程,這一點從 MySQL 中的 show profile 裡也能看到。同時 MySQL 的一大特色就是提供了各種儲存引擎以供選擇,不同的儲存引擎有各自的使用場景,我們可以針對每張表選擇適合的儲存引擎。
使用DDL建立資料庫&資料表時需要注意什麼?
DDL 是 DBMS 的核心元件,也是 SQL 的重要組成部分,DDL 的正確性和穩定性是整個 SQL 執行的重要基礎。面對同一個需求,不同的開發人員創建出來的資料庫和資料表可能千差萬別,那麼在設計資料庫的時候,究竟什麼是好的原則?我們在建立資料表的時候需要注意什麼?
DDL 的基礎語法及設計工具
DDL 的英文全稱是 Data Definition Language,中文是資料定義語言。它定義了資料庫的結構和資料表的結構。
在 DDL 中,我們常用的功能是增刪改,分別對應的命令是 CREATE、DROP 和 ALTER。需要注意的是,在執行 DDL 的時候,不需要 COMMIT,就可以完成執行任務。
1.對資料庫進行定義
CREATE DATABASE nba; // 建立一個名為 nba 的資料庫
DROP DATABASE nba; // 刪除一個名為 nba 的資料庫
2.對資料表進行定義
建立表結構的語法是這樣的:
CREATE TABLE table_name
建立表結構
比如我們想建立一個球員表,表名為 player,裡面有兩個欄位,一個是 player_id,它是 int 型別,另一個 player_name 欄位是varchar(255)型別。這兩個欄位都不為空,且 player_id 是遞增的。
那麼建立的時候就可以寫為:
CREATE TABLE player (
player_id int(11) NOT NULL AUTO_INCREMENT,
player_name varchar(255) NOT NULL
);
需要注意的是,語句最後以分號(;)作為結束符,最後一個欄位的定義結束後沒有逗號。資料型別中 int(11) 代表整數型別,顯示長度為 11 位,括號中的引數 11 代表的是最大有效顯示長度,與型別包含的數值範圍大小無關。varchar(255)代表的是最大長度為 255 的可變字串型別。NOT NULL表明整個欄位不能是空值,是一種資料約束。AUTO_INCREMENT代表主鍵自動增長。
實際上,我們通常很少自己寫 DDL 語句,可以使用一些視覺化工具來建立和操作資料庫和資料表。在這裡我推薦使用 Navicat,它是一個數據庫管理和設計工具,跨平臺,支援很多種資料庫管理軟體,比如 MySQL、Oracle、MariaDB 等。基本上專欄講到的資料庫軟體都可以使用 Navicat 來管理。
假如還是針對 player 這張表,我們想設計以下的欄位:
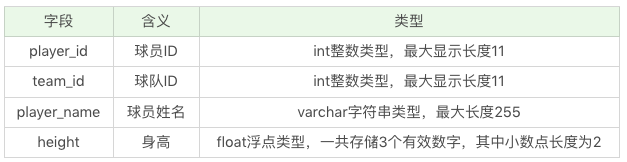
其中 player_id 是資料表 player 的主鍵,且自動增長,也就是 player_id 會從 1 開始,然後每次加 1。player_id、team_id、player_name 這三個欄位均不為空,height 欄位可以為空。
按照上面的設計需求,我們可以使用 Navicat 軟體進行設計,如下所示:
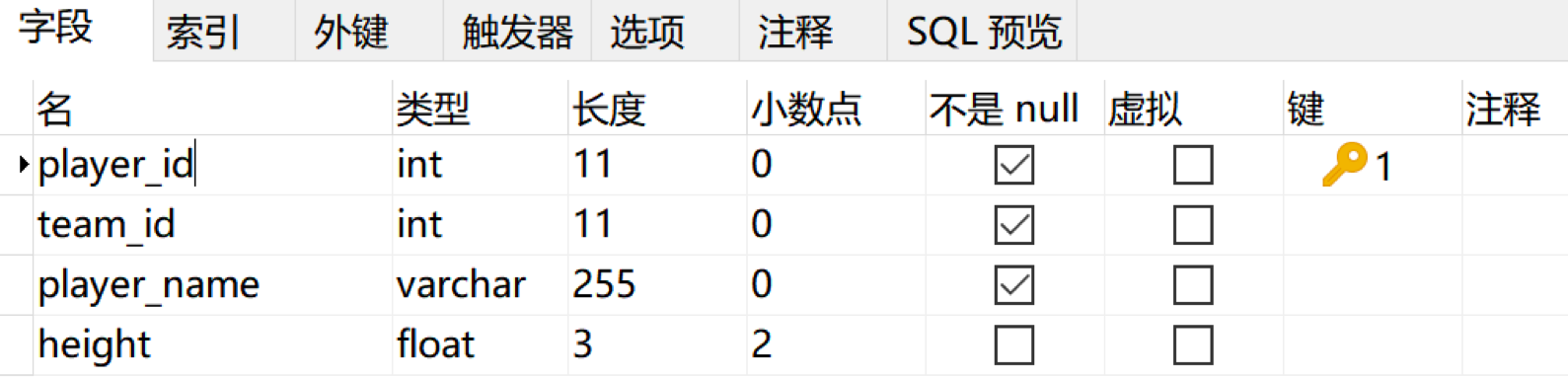
然後,我們還可以對 player_name 欄位進行索引,索引型別為Unique。使用 Navicat 設定如下:

這樣一張 player 表就通過視覺化工具設計好了。我們可以把這張表匯出來,可以看看這張表對應的 SQL 語句是怎樣的。方法是在 Navicat 左側用右鍵選中 player 這張表,然後選擇“轉儲 SQL 檔案”→“僅結構”,這樣就可以看到匯出的 SQL 檔案了,程式碼如下:
DROP TABLE IF EXISTS `player`;
CREATE TABLE `player` (
`player_id` int(11) NOT NULL AUTO_INCREMENT,
`team_id` int(11) NOT NULL,
`player_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`height` float(3, 2) NULL DEFAULT 0.00,
PRIMARY KEY (`player_id`) USING BTREE,
UNIQUE INDEX `player_name`(`player_name`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
你能看到整個 SQL 檔案中的 DDL 處理,首先先刪除 player 表(如果資料庫中存在該表的話),然後再建立 player 表,裡面的資料表和欄位都使用了反引號,這是為了避免它們的名稱與 MySQL 保留欄位相同,對資料表和欄位名稱都加上了反引號。
其中 player_name 欄位的字符集是 utf8,排序規則是utf8_general_ci,代表對大小寫不敏感,如果設定為utf8_bin,代表對大小寫敏感,還有許多其他排序規則這裡不進行介紹。
因為 player_id 設定為了主鍵,因此在 DDL 中使用PRIMARY KEY進行規定,同時索引方法採用 BTREE。
因為我們對 player_name 欄位進行索引,在設定欄位索引時,我們可以設定為UNIQUE INDEX(唯一索引),也可以設定為其他索引方式,比如NORMAL INDEX(普通索引),這裡我們採用UNIQUE INDEX。唯一索引和普通索引的區別在於它對欄位進行了唯一性的約束。在索引方式上,你可以選擇BTREE或者HASH,這裡採用了BTREE方法進行索引。我會在後面介紹BTREE和HASH索引方式的區別。
整個資料表的儲存規則採用 InnoDB。之前我們簡單介紹過 InnoDB,它是 MySQL5.5 版本之後預設的儲存引擎。同時,我們將字符集設定為 utf8,排序規則為utf8_general_ci,行格式為Dynamic,就可以定義資料表的最後約定了:
ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
你能看出視覺化工具還是非常方便的,它能直接幫我們將資料庫的結構定義轉化成 SQL 語言,方便資料庫和資料表結構的匯出和匯入。不過在使用視覺化工具前,你首先需要了解對於 DDL 的基礎語法,至少能清晰地看出來不同欄位的定義規則、索引方法,以及主鍵和外來鍵的定義。
修改表結構
在建立表結構之後,我們還可以對錶結構進行修改,雖然直接使用 Navicat 可以保證重新匯出的資料表就是最新的,但你也有必要了解,如何使用 DDL 命令來完成表結構的修改。
\1. 新增欄位,比如我在資料表中新增一個 age 欄位,型別為int(11)
ALTER TABLE player ADD (age int(11));
\2. 修改欄位名,將 age 欄位改成player_age
ALTER TABLE player RENAME COLUMN age to player_age
\3. 修改欄位的資料型別,將player_age的資料型別設定為float(3,1)
ALTER TABLE player MODIFY (player_age float(3,1));
\4. 刪除欄位, 刪除剛才新增的player_age欄位
ALTER TABLE player DROP COLUMN player_age;
資料表的常見約束
當我們建立資料表的時候,還會對欄位進行約束,約束的目的在於保證 RDBMS 裡面資料的準確性和一致性。下面,我們來看下常見的約束有哪些。
首先是主鍵約束。
主鍵起的作用是唯一標識一條記錄,不能重複,不能為空,即 UNIQUE+NOT NULL。一個數據表的主鍵只能有一個。主鍵可以是一個欄位,也可以由多個欄位複合組成。在上面的例子中,我們就把 player_id 設定為了主鍵。
其次還有外來鍵約束。
外來鍵確保了表與表之間引用的完整性。一個表中的外來鍵對應另一張表的主鍵。外來鍵可以是重複的,也可以為空。比如 player_id 在 player 表中是主鍵,如果你想設定一個球員比分表即 player_score,就可以在 player_score 中設定 player_id 為外來鍵,關聯到 player 表中。
除了對鍵進行約束外,還有欄位約束。
唯一性約束
唯一性約束表明了欄位在表中的數值是唯一的,即使我們已經有了主鍵,還可以對其他欄位進行唯一性約束。比如我們在 player 表中給 player_name 設定唯一性約束,就表明任何兩個球員的姓名不能相同。需要注意的是,唯一性約束和普通索引(NORMAL INDEX)之間是有區別的。唯一性約束相當於建立了一個約束和普通索引,目的是保證欄位的正確性,而普通索引只是提升資料檢索的速度,並不對欄位的唯一性進行約束。
NOT NULL 約束。對欄位定義了 NOT NULL,即表明該欄位不應為空,必須有取值。
DEFAULT,表明了欄位的預設值。如果在插入資料的時候,這個欄位沒有取值,就設定為預設值。比如我們將身高 height 欄位的取值預設設定為 0.00,即DEFAULT 0.00。
CHECK 約束,用來檢查特定欄位取值範圍的有效性,CHECK 約束的結果不能為 FALSE,比如我們可以對身高 height 的數值進行 CHECK 約束,必須≥0,且<3,即CHECK(height>=0 AND height<3)。
設計資料表的原則
我們在設計資料表的時候,經常會考慮到各種問題,比如:
- 使用者都需要什麼資料?
- 需要在資料表中儲存哪些資料?
- 哪些資料是經常訪問的資料?
- 如何提升檢索效率?
- 如何保證資料表中資料的正確性,當插入、刪除、更新的時候該進行怎樣的約束檢查?
- 如何降低資料表的資料冗餘度,保證資料表不會因為使用者量的增長而迅速擴張?
- 如何讓負責資料庫維護的人員更方便地使用資料庫?
除此以外,我們使用資料庫的應用場景也各不相同,可以說針對不同的情況,設計出來的資料表可能千差萬別。那麼有沒有一種設計原則可以讓我們來借鑑呢?這裡我整理了一個“三少一多”原則:
資料表的個數越少越好
RDBMS 的核心在於對實體和聯絡的定義,也就是 E-R 圖(Entity Relationship Diagram),資料表越少,證明實體和聯絡設計得越簡潔,既方便理解又方便操作。
資料表中的欄位個數越少越好
欄位個數越多,資料冗餘的可能性越大。設定欄位個數少的前提是各個欄位相互獨立,而不是某個欄位的取值可以由其他欄位計算出來。當然欄位個數少是相對的,我們通常會在資料冗餘和檢索效率中進行平衡。
資料表中聯合主鍵的欄位個數越少越好
設定主鍵是為了確定唯一性,當一個欄位無法確定唯一性的時候,就需要採用聯合主鍵的方式(也就是用多個欄位來定義一個主鍵)。聯合主鍵中的欄位越多,佔用的索引空間越大,不僅會加大理解難度,還會增加執行時間和索引空間,因此聯合主鍵的欄位個數越少越好。
使用主鍵和外來鍵越多越好
資料庫的設計實際上就是定義各種表,以及各種欄位之間的關係。這些關係越多,證明這些實體之間的冗餘度越低,利用度越高。這樣做的好處在於不僅保證了資料表之間的獨立性,還能提升相互之間的關聯使用率。
你應該能看出來“三少一多”原則的核心就是簡單可複用。簡單指的是用更少的表、更少的欄位、更少的聯合主鍵欄位來完成資料表的設計。可複用則是通過主鍵、外來鍵的使用來增強資料表之間的複用率。因為一個主鍵可以理解是一張表的代表。鍵設計得越多,證明它們之間的利用率越高。
總結
今天我們學習了 DDL 的基礎語法,比如如何對資料庫和資料庫表進行定義,也瞭解了使用 Navicat 視覺化管理工具來輔助我們完成資料表的設計,省去了手寫 SQL 的工作量。
在建立資料表的時候,除了對欄位名及資料型別進行定義以外,我們考慮最多的就是關於欄位的約束,我介紹了 7 種常見的約束,它們都是資料表設計中會用到的約束:主鍵、外來鍵、唯一性、NOT NULL、DEFAULT、CHECK 約束等。
當然,瞭解瞭如何操作建立資料表之後,你還需要動腦思考,怎樣才能設計出一個好的資料表?設計的原則都有哪些?針對這個,我整理出了“三少一多”原則,在實際使用過程中,你需要靈活掌握,因為這個原則並不是絕對的,有時候我們需要犧牲資料的冗餘度來換取資料處理的效率。
檢索資料
SELECT 可以說是 SQL 中最常用的語句了。你可以把 SQL 語句看作是英語語句,SELECT 就是 SQL 中的關鍵字之一,除了 SELECT 之外,還有 INSERT、DELETE、UPDATE 等關鍵字,這些關鍵字是 SQL 的保留字,這樣可以很方便地幫助我們分析理解 SQL 語句。我們在定義資料庫表名、欄位名和變數名時,要儘量避免使用這些保留字。
SELECT 的作用是從一個表或多個表中檢索出想要的資料行。
SELECT 查詢的基礎語法
SELECT 可以幫助我們從一個表或多個表中進行資料查詢。我們知道一個數據表是由列(欄位名)和行(資料行)組成的,我們要返回滿足條件的資料行,就需要在 SELECT 後面加上我們想要查詢的列名,可以是一列,也可以是多個列。如果你不知道所有列名都有什麼,也可以檢索所有列。
我建立了一個王者榮耀英雄資料表,這張表裡一共有 69 個英雄,23 個屬性值(不包括英雄名 name)。SQL 檔案見百度網盤連結 提取碼:gov5

資料表中這 24 個欄位(除了 id 以外),分別代表的含義見下圖。
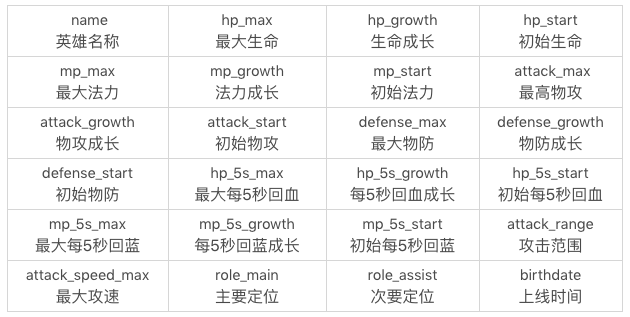
查詢列
如果我們想要對資料表中的某一列進行檢索,在 SELECT 後面加上這個列的欄位名即可。比如我們想要檢索資料表中都有哪些英雄。
SQL:SELECT name FROM heros
執行結果(69 條記錄)見下圖,你可以看到這樣就等於單獨輸出了 name 這一列。

我們也可以對多個列進行檢索,在列名之間用逗號 (,) 分割即可。比如我們想要檢索有哪些英雄,他們的最大生命、最大法力、最大物攻和最大物防分別是多少。
SQL:SELECT name, hp_max, mp_max, attack_max, defense_max FROM heros
執行結果(69 條記錄):

這個表中一共有 25 個欄位,除了 id 和英雄名 name 以外,還存在 23 個屬性值,如果我們記不住所有的欄位名稱,可以使用 SELECT * 幫我們檢索出所有的列:
SQL:SELECT * FROM heros
執行結果(69 條記錄):
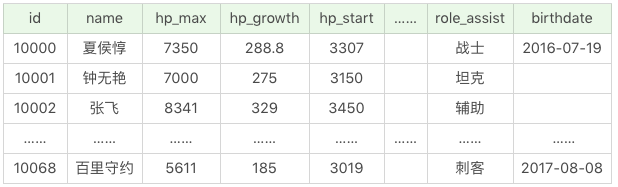
我們在做資料探索的時候,SELECT *還是很有用的,這樣我們就不需要寫很長的 SELECT 語句了。但是在生產環境時要儘量避免使用SELECT*。
起別名
我們在使用 SELECT 查詢的時候,還有一些技巧可以使用,比如你可以給列名起別名。我們在進行檢索的時候,可以給英雄名、最大生命、最大法力、最大物攻和最大物防等取別名:
SQL:SELECT name AS n, hp_max AS hm, mp_max AS mm, attack_max AS am, defense_max AS dm FROM heros
執行結果和上面多列檢索的執行結果是一樣的,只是將列名改成了 n、hm、mm、am 和 dm。當然這裡的列別名只是舉例,一般來說起別名的作用是對原有名稱進行簡化,從而讓 SQL 語句看起來更精簡。同樣我們也可以對錶名稱起別名,這個在多表連線查詢的時候會用到。
查詢常數
SELECT 查詢還可以對常數進行查詢。對的,就是在 SELECT 查詢結果中增加一列固定的常數列。這列的取值是我們指定的,而不是從資料表中動態取出的。你可能會問為什麼我們還要對常數進行查詢呢?SQL 中的 SELECT 語法的確提供了這個功能,一般來說我們只從一個表中查詢資料,通常不需要增加一個固定的常數列,但如果我們想整合不同的資料來源,用常數列作為這個表的標記,就需要查詢常數。
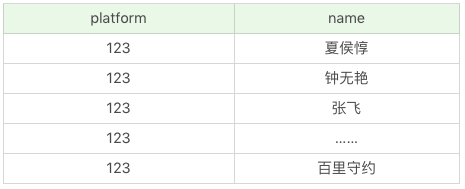
比如說,我們想對 heros 資料表中的英雄名進行查詢,同時增加一列欄位platform,這個欄位固定值為“王者榮耀”,可以這樣寫:
SQL:SELECT '王者榮耀' as platform, name FROM heros
執行結果:(69 條記錄)

在這個 SQL 語句中,我們虛構了一個platform欄位,並且把它設定為固定值“王者榮耀”。
需要說明的是,如果常數是個字串,那麼使用單引號(‘’)就非常重要了,比如‘王者榮耀’。單引號說明引號中的字串是個常數,否則 SQL 會把王者榮耀當成列名進行查詢,但實際上資料表裡沒有這個列名,就會引起錯誤。如果常數是英文字母,比如'WZRY'也需要加引號。如果常數是個數字,就可以直接寫數字,不需要單引號,比如:
SQL:SELECT 123 as platform, name FROM heros
執行結果:(69 條記錄)
去除重複行
關於單個表的 SELECT 查詢,還有一個非常實用的操作,就是從結果中去掉重複的行。使用的關鍵字是 DISTINCT。比如我們想要看下 heros 表中關於攻擊範圍的取值都有哪些:
SQL:SELECT DISTINCT attack_range FROM heros
這是執行結果(2 條記錄),這樣我們就能直觀地看到攻擊範圍其實只有兩個值,那就是近戰和遠端。

如果我們帶上英雄名稱,會是怎樣呢:
SQL:SELECT DISTINCT attack_range, name FROM heros
執行結果(69 條記錄):
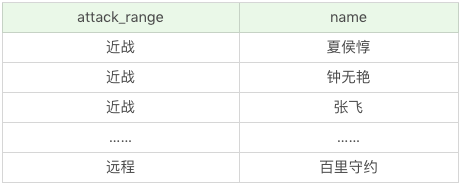
這裡有兩點需要注意:
- DISTINCT 需要放到所有列名的前面,如果寫成
SELECT name, DISTINCT attack_range FROM heros會報錯。 - DISTINCT 其實是對後面所有列名的組合進行去重,你能看到最後的結果是 69 條,因為這 69 個英雄名稱不同,都有攻擊範圍(attack_range)這個屬性值。如果你想要看都有哪些不同的攻擊範圍(attack_range),只需要寫
DISTINCT attack_range即可,後面不需要再加其他的列名了。
如何排序檢索資料
當我們檢索資料的時候,有時候需要按照某種順序進行結果的返回,比如我們想要查詢所有的英雄,按照最大生命從高到底的順序進行排列,就需要使用 ORDER BY 子句。使用 ORDER BY 子句有以下幾個點需要掌握:
- 排序的列名:ORDER BY 後面可以有一個或多個列名,如果是多個列名進行排序,會按照後面第一個列先進行排序,當第一列的值相同的時候,再按照第二列進行排序,以此類推。
- 排序的順序:ORDER BY 後面可以註明排序規則,ASC 代表遞增排序,DESC 代表遞減排序。如果沒有註明排序規則,預設情況下是按照 ASC 遞增排序。我們很容易理解 ORDER BY 對數值型別欄位的排序規則,但如果排序欄位型別為文字資料,就需要參考資料庫的設定方式了,這樣才能判斷 A 是在 B 之前,還是在 B 之後。比如使用 MySQL 在建立欄位的時候設定為 BINARY 屬性,就代表區分大小寫。
- 非選擇列排序:ORDER BY 可以使用非選擇列進行排序,所以即使在 SELECT 後面沒有這個列名,你同樣可以放到 ORDER BY 後面進行排序。
- ORDER BY 的位置:ORDER BY 通常位於 SELECT 語句的最後一條子句,否則會報錯。
在瞭解了 ORDER BY 的使用語法之後,我們來看下如何對 heros 資料表進行排序。
假設我們想要顯示英雄名稱及最大生命值,按照最大生命值從高到低的方式進行排序:
SQL:SELECT name, hp_max FROM heros ORDER BY hp_max DESC
執行結果(69 條記錄):
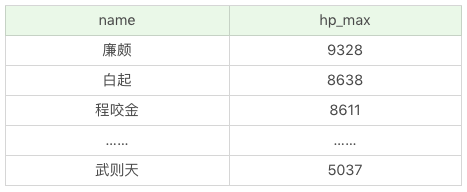
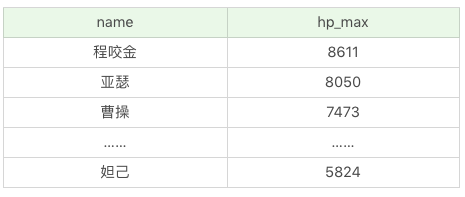
如果想要顯示英雄名稱及最大生命值,按照第一排序最大法力從低到高,當最大法力值相等的時候則按照第二排序進行,即最大生命值從高到低的方式進行排序:
SQL:SELECT name, hp_max FROM heros ORDER BY mp_max, hp_max DESC
執行結果:(69 條記錄)
約束返回結果的數量
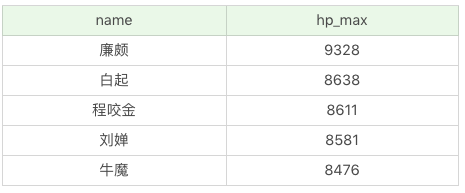
另外在查詢過程中,我們可以約束返回結果的數量,使用 LIMIT 關鍵字。比如我們想返回英雄名稱及最大生命值,按照最大生命值從高到低排序,返回 5 條記錄即可。
SQL:SELECT name, hp_max FROM heros ORDER BY hp_max DESC LIMIT 5
執行結果(5 條記錄):
有一點需要注意,約束返回結果的數量,在不同的 DBMS 中使用的關鍵字可能不同。在 MySQL、PostgreSQL、MariaDB 和 SQLite 中使用 LIMIT 關鍵字,而且需要放到 SELECT 語句的最後面。如果是 SQL Server 和 Access,需要使用 TOP 關鍵字,比如:
SQL:SELECT TOP 5 name, hp_max FROM heros ORDER BY hp_max DESC
如果是 DB2,使用FETCH FIRST 5 ROWS ONLY這樣的關鍵字:
SQL:SELECT name, hp_max FROM heros ORDER BY hp_max DESC FETCH FIRST 5 ROWS ONLY
如果是 Oracle,你需要基於 ROWNUM 來統計行數:
SQL:SELECT name, hp_max FROM heros WHERE ROWNUM <=5 ORDER BY hp_max DESC
需要說明的是,這條語句是先取出來前 5 條資料行,然後再按照 hp_max 從高到低的順序進行排序。但這樣產生的結果和上述方法的並不一樣。我會在後面講到子查詢,你可以使用SELECT name, hp_max FROM (SELECT name, hp_max FROM heros ORDER BY hp_max) WHERE ROWNUM <=5得到與上述方法一致的結果。
約束返回結果的數量可以減少資料表的網路傳輸量,也可以提升查詢效率。如果我們知道返回結果只有 1 條,就可以使用LIMIT 1,告訴 SELECT 語句只需要返回一條記錄即可。這樣的好處就是 SELECT 不需要掃描完整的表,只需要檢索到一條符合條件的記錄即可返回。
SELECT 的執行順序
查詢是 RDBMS 中最頻繁的操作。我們在理解 SELECT 語法的時候,還需要了解 SELECT 執行時的底層原理。只有這樣,才能讓我們對 SQL 有更深刻的認識。
其中你需要記住 SELECT 查詢時的兩個順序:
關鍵字的順序是不能顛倒的:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ...
SELECT 語句的執行順序(在 MySQL 和 Oracle 中,SELECT 執行順序基本相同):
FROM > WHERE > GROUP BY > HAVING > SELECT 的欄位 > DISTINCT > ORDER BY > LIMIT
比如你寫了一個 SQL 語句,那麼它的關鍵字順序和執行順序是下面這樣的:
SELECT DISTINCT player_id, player_name, count(*) as num # 順序 5
FROM player JOIN team ON player.team_id = team.team_id # 順序 1
WHERE height > 1.80 # 順序 2
GROUP BY player.team_id # 順序 3
HAVING num > 2 # 順序 4
ORDER BY num DESC # 順序 6
LIMIT 2 # 順序 7
在 SELECT 語句執行這些步驟的時候,每個步驟都會產生一個虛擬表,然後將這個虛擬表傳入下一個步驟中作為輸入。需要注意的是,這些步驟隱含在 SQL 的執行過程中,對於我們來說是不可見的。
詳細解釋一下 SQL 的執行原理。
首先,你可以注意到,SELECT 是先執行 FROM 這一步的。在這個階段,如果是多張表聯查,還會經歷下面的幾個步驟:
- 首先先通過 CROSS JOIN 求笛卡爾積,相當於得到虛擬表 vt(virtual table)1-1;
- 通過 ON 進行篩選,在虛擬表 vt1-1 的基礎上進行篩選,得到虛擬表 vt1-2;
- 新增外部行。如果我們使用的是左連線、右連結或者全連線,就會涉及到外部行,也就是在虛擬表 vt1-2 的基礎上增加外部行,得到虛擬表 vt1-3。
當然如果我們操作的是兩張以上的表,還會重複上面的步驟,直到所有表都被處理完為止。這個過程得到是我們的原始資料。
當我們拿到了查詢資料表的原始資料,也就是最終的虛擬表 vt1,就可以在此基礎上再進行 WHERE 階段。在這個階段中,會根據 vt1 表的結果進行篩選過濾,得到虛擬表 vt2。
然後進入第三步和第四步,也就是 GROUP 和 HAVING 階段。在這個階段中,實際上是在虛擬表 vt2 的基礎上進行分組和分組過濾,得到中間的虛擬表 vt3 和 vt4。
當我們完成了條件篩選部分之後,就可以篩選表中提取的欄位,也就是進入到 SELECT 和 DISTINCT 階段。
首先在 SELECT 階段會提取想要的欄位,然後在 DISTINCT 階段過濾掉重複的行,分別得到中間的虛擬表 vt5-1 和 vt5-2。
當我們提取了想要的欄位資料之後,就可以按照指定的欄位進行排序,也就是 ORDER BY 階段,得到虛擬表 vt6。
最後在 vt6 的基礎上,取出指定行的記錄,也就是 LIMIT 階段,得到最終的結果,對應的是虛擬表 vt7。
當然我們在寫 SELECT 語句的時候,不一定存在所有的關鍵字,相應的階段就會省略。
同時因為 SQL 是一門類似英語的結構化查詢語言,所以我們在寫 SELECT 語句的時候,還要注意相應的關鍵字順序,所謂底層執行的原理,就是我們剛才講到的執行順序。
什麼情況下用 SELECT*,如何提升 SELECT 查詢效率?
當我們初學 SELECT 語法的時候,經常會使用SELECT *,因為使用方便。實際上這樣也增加了資料庫的負擔。所以如果我們不需要把所有列都檢索出來,還是先指定出所需的列名,因為寫清列名,可以減少資料表查詢的網路傳輸量,而且考慮到在實際的工作中,我們往往不需要全部的列名,因此你需要養成良好的習慣,寫出所需的列名。
如果我們只是練習,或者對資料表進行探索,那麼是可以使用SELECT *的。它的查詢效率和把所有列名都寫出來再進行查詢的效率相差並不大。這樣可以方便你對資料表有個整體的認知。但是在生產環境下,不推薦你直接使用SELECT *進行查詢。
總結
對 SELECT 的基礎語法進行了講解,SELECT 是 SQL 的基礎。但不同階段看 SELECT 都會有新的體會。當你第一次學習的時候,關注的往往是如何使用它,或者語法是否正確。再看的時候,可能就會更關注 SELECT 的查詢效率,以及不同 DBMS 之間的差別。
在我們的日常工作中,很多人都可以寫出 SELECT 語句,但是執行的效率卻相差很大。產生這種情況的原因主要有兩個,一個是習慣的培養,比如大部分初學者會經常使用SELECT *,而好的習慣則是隻查詢所需要的列;另一個對 SQL 查詢的執行順序及查詢效率的關注,比如當你知道只有 1 條記錄的時候,就可以使用LIMIT 1來進行約束,從而提升查詢效率。
資料過濾
提升查詢效率的一個很重要的方式,就是約束返回結果的數量,還有一個很有效的方式,就是指定篩選條件,進行過濾。過濾可以篩選符合條件的結果,並進行返回,減少不必要的資料行。
你可能已經使用過 WHERE 子句,說起來 SQL 其實很簡單,只要能把滿足條件的內容篩選出來即可,但在實際使用過程中,不同人寫出來的 WHERE 子句存在很大差別,比如執行效率的高低,有沒有遇到莫名的報錯等。
比較運算子
在 SQL 中,我們可以使用 WHERE 子句對條件進行篩選,在此之前,你需要了解 WHERE 子句中的比較運算子。這些比較運算子的含義你可以參見下面這張表格:
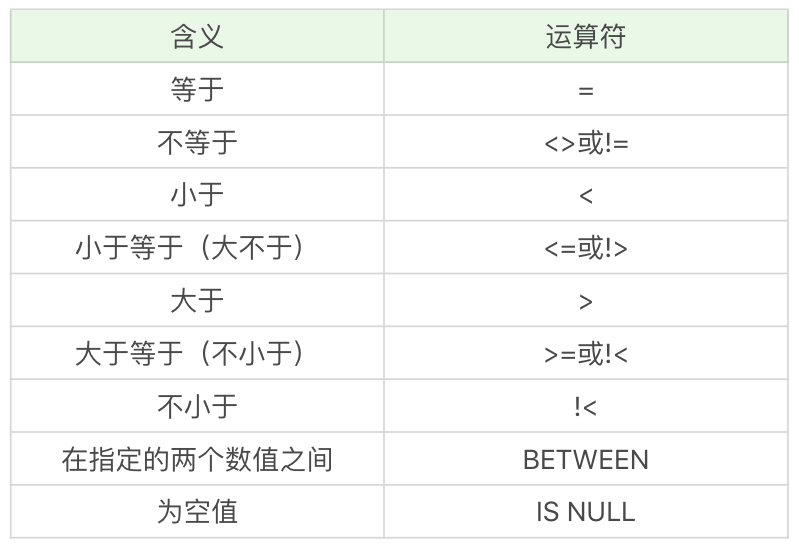
實際上你能看到,同樣的含義可能會有多種表達方式,比如小於等於,可以是(<=),也可以是不大於(!>)。同樣不等於,可以用(<>),也可以用(!=),它們的含義都是相同的,但這些符號的順序都不能顛倒,比如你不能寫(=<)。需要注意的是,你需要檢視使用的 DBMS 是否支援,不同的 DBMS 支援的運算子可能是不同的,比如 Access 不支援(!=),不等於應該使用(<>)。在 MySQL 中,不支援(!>)(!<)等。
WHERE 子句的基本格式是:SELECT ……(列名) FROM ……(表名) WHERE ……(子句條件)
比如我們想要查詢所有最大生命值大於 6000 的英雄:
SQL:SELECT name, hp_max FROM heros WHERE hp_max > 6000
執行結果(41 條記錄):

想要查詢所有最大生命值在 5399 到 6811 之間的英雄:
SQL:SELECT name, hp_max FROM heros WHERE hp_max BETWEEN 5399 AND 6811
執行結果:(41 條記錄)

需要注意的是hp_max可以取值到最小值和最大值,即 5399 和 6811。
我們也可以對 heros 表中的hp_max欄位進行空值檢查。
SQL:SELECT name, hp_max FROM heros WHERE hp_max IS NULL
執行結果為空,說明 heros 表中的hp_max欄位沒有存在空值的資料行。
邏輯運算子
我剛才介紹了比較運算子,如果我們存在多個 WHERE 條件子句,可以使用邏輯運算子:
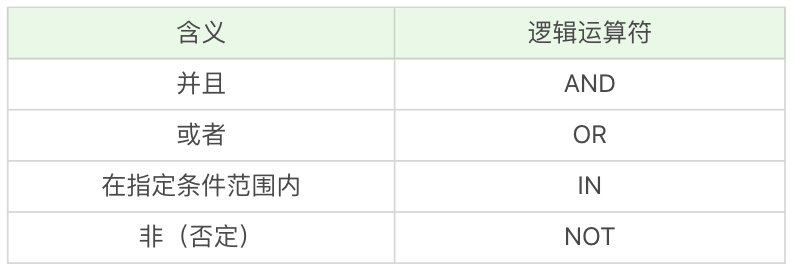
假設想要篩選最大生命值大於 6000,最大法力大於 1700 的英雄,然後按照最大生命值和最大法力值之和從高到低進行排序。
SQL:SELECT name, hp_max, mp_max FROM heros WHERE hp_max > 6000 AND mp_max > 1700 ORDER BY (hp_max+mp_max) DESC
執行結果:(23 條記錄)

如果 AND 和 OR 同時存在 WHERE 子句中會是怎樣的呢?假設我們想要查詢最大生命值加最大法力值大於 8000 的英雄,或者最大生命值大於 6000 並且最大法力值大於 1700 的英雄。
SQL:SELECT name, hp_max, mp_max FROM heros WHERE (hp_max+mp_max) > 8000 OR hp_max > 6000 AND mp_max > 1700 ORDER BY (hp_max+mp_max) DESC
執行結果:(33 條記錄)

你能看出來相比於上一個條件查詢,這次的條件查詢多出來了 10 個英雄,這是因為我們放寬了條件,允許最大生命值 + 最大法力值大於 8000 的英雄顯示出來。另外你需要注意到,當 WHERE 子句中同時存在 OR 和 AND 的時候,AND 執行的優先順序會更高,也就是說 SQL 會優先處理 AND 操作符,然後再處理 OR 操作符。
如果我們對這條查詢語句 OR 兩邊的條件增加一個括號,結果會是怎樣的呢?
SQL:SELECT name, hp_max, mp_max FROM heros WHERE ((hp_max+mp_max) > 8000 OR hp_max > 6000) AND mp_max > 1700 ORDER BY (hp_max+mp_max) DESC
執行結果:

所以當 WHERE 子句中同時出現 AND 和 OR 操作符的時候,你需要考慮到執行的先後順序,也就是兩個操作符執行的優先順序。一般來說 () 優先順序最高,其次優先順序是 AND,然後是 OR。
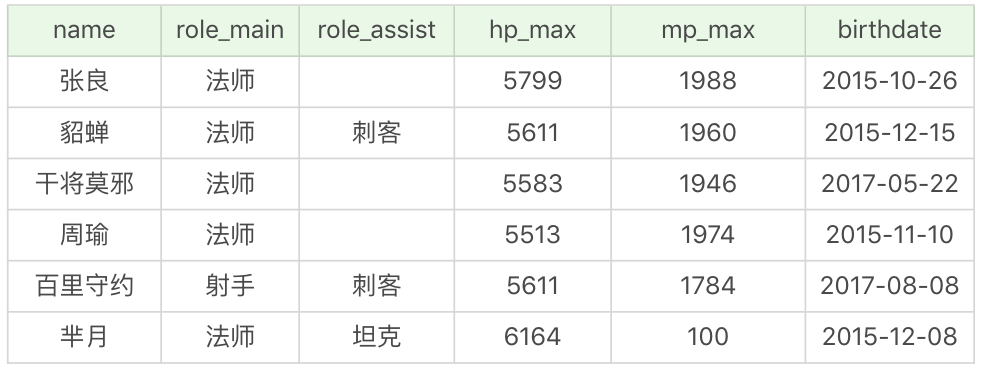
如果我想要查詢主要定位或者次要定位是法師或是射手的英雄,同時英雄的上線時間不在 2016-01-01 到 2017-01-01 之間。
SQL:
SELECT name, role_main, role_assist, hp_max, mp_max, birthdate
FROM heros
WHERE (role_main IN ('法師', '射手') OR role_assist IN ('法師', '射手'))
AND DATE(birthdate) NOT BETWEEN '2016-01-01' AND '2017-01-01'
ORDER BY (hp_max + mp_max) DESC
你能看到我把 WHERE 子句分成了兩個部分。第一部分是關於主要定位和次要定位的條件過濾,使用的是role_main in ('法師', '射手') OR role_assist in ('法師', '射手')。這裡用到了 IN 邏輯運算子,同時role_main和role_assist是 OR(或)的關係。
第二部分是關於上線時間的條件過濾。NOT 代表否,因為我們要找到不在 2016-01-01 到 2017-01-01 之間的日期,因此用到了NOT BETWEEN '2016-01-01' AND '2017-01-01'。同時我們是在對日期型別資料進行檢索,所以使用到了 DATE 函式,將欄位 birthdate 轉化為日期型別再進行比較。
這是執行結果(6 條記錄):
使用萬用字元進行過濾
剛才講解的條件過濾都是對已知值進行的過濾,還有一種情況是我們要檢索文字中包含某個詞的所有資料,這裡就需要使用萬用字元。萬用字元就是我們用來匹配值的一部分的特殊字元。這裡我們需要使用到 LIKE 操作符。
如果我們想要匹配任意字串出現的任意次數,需要使用(%)萬用字元。比如我們想要查詢英雄名中包含“太”字的英雄都有哪些:
SQL:SELECT name FROM heros WHERE name LIKE '% 太 %'
執行結果:(2 條記錄)

需要說明的是不同 DBMS 對萬用字元的定義不同,在 Access 中使用的是(*)而不是(%)。另外關於字串的搜尋可能是需要區分大小寫的,比如'liu%'就不能匹配上'LIU BEI'。具體是否區分大小寫還需要考慮不同的 DBMS 以及它們的配置。
如果我們想要匹配單個字元,就需要使用下劃線 (_) 萬用字元。(%)和(_)的區別在於,(%)代表一個或多個字元,而(_)只代表一個字元。比如我們想要查詢英雄名除了第一個字以外,包含“太”字的英雄有哪些。
SQL:SELECT name FROM heros WHERE name LIKE '_% 太 %'
執行結果(1 條記錄):

因為太乙真人的太是第一個字元,而_%太%中的太不是在第一個字元,所以匹配不到“太乙真人”,只可以匹配上“東皇太一”。
同樣需要說明的是,在 Access 中使用(?)來代替(_),而且在 DB2 中是不支援萬用字元(_)的,因此你需要在使用的時候查閱相關的 DBMS 文件。
你能看出來萬用字元還是很有用的,尤其是在進行字串匹配的時候。不過在實際操作過程中,我還是建議你儘量少用萬用字元,因為它需要消耗資料庫更長的時間來進行匹配。即使你對 LIKE 檢索的欄位進行了索引,索引的價值也可能會失效。如果要讓索引生效,那麼 LIKE 後面就不能以(%)開頭,比如使用LIKE '%太%'或LIKE '%太'的時候就會對全表進行掃描。如果使用LIKE '太%',同時檢索的欄位進行了索引的時候,則不會進行全表掃描。
總結
對 SQL 語句中的 WHERE 子句進行了講解,你可以使用比較運算子、邏輯運算子和萬用字元這三種方式對檢索條件進行過濾。
比較運算子是對數值進行比較,不同的 DBMS 支援的比較運算子可能不同,你需要事先查閱相應的 DBMS 文件。邏輯運算子可以讓我們同時使用多個 WHERE 子句,你需要注意的是 AND 和 OR 運算子的執行順序。萬用字元可以讓我們對文字型別的欄位進行模糊查詢,不過檢索的代價也是很高的,通常都需要用到全表掃描,所以效率很低。只有當 LIKE 語句後面不用萬用字元,並且對欄位進行索引的時候才不會對全表進行掃描。
你可能認為學習 SQL 並不難,掌握這些語法就可以對資料進行篩選查詢。但實際工作中不同人寫的 SQL 語句的查詢效率差別很大,保持高效率的一個很重要的原因,就是要避免全表掃描,所以我們會考慮在 WHERE 及 ORDER BY 涉及到的列上增加索引。
SQL函式
函式在計算機語言的使用中貫穿始終,在 SQL 中我們也可以使用函式對檢索出來的資料進行函式操作,比如求某列資料的平均值,或者求字串的長度等。從函式定義的角度出發,我們可以將函式分成內建函式和自定義函式。在 SQL 語言中,同樣也包括了內建函式和自定義函式。內建函式是系統內建的通用函式,而自定義函式是我們根據自己的需要編寫的,下面講解的是 SQL 的內建函式。
什麼是 SQL 函式
當我們學習程式語言的時候,也會遇到函式。函式的作用是什麼呢?它可以把我們經常使用的程式碼封裝起來,需要的時候直接呼叫即可。這樣既提高了程式碼效率,又提高了可維護性。
SQL 中的函式一般是在資料上執行的,可以很方便地轉換和處理資料。一般來說,當我們從資料表中檢索出資料之後,就可以進一步對這些資料進行操作,得到更有意義的結果,比如返回指定條件的函式,或者求某個欄位的平均值等。
常用的 SQL 函式有哪些
SQL 提供了一些常用的內建函式,當然你也可以自己定義 SQL 函式。SQL 的內建函式對於不同的資料庫軟體來說具有一定的通用性,我們可以把內建函式分成四類:
- 算術函式
- 字串函式
- 日期函式
- 轉換函式
這 4 類函式分別代表了算術處理、字串處理、日期處理、資料型別轉換,它們是 SQL 函式常用的劃分形式,你可以思考下,為什麼是這 4 個維度?
函式是對提取出來的資料進行操作,那麼資料表中欄位型別的定義有哪幾種呢?
我們經常會儲存一些數值,不論是整數型別,還是浮點型別,實際上對應的就是數值型別。
同樣我們也會儲存一些文字內容,可能是人名,也可能是某個說明,對應的就是字串型別。
此外我們還需要儲存時間,也就是日期型別。那麼針對數值、字串和日期型別的資料,我們可以對它們分別進行算術函式、字串函式以及日期函式的操作。
如果想要完成不同型別資料之間的轉換,就可以使用轉換函式。
算術函式
算術函式,顧名思義就是對數值型別的欄位進行算術運算。常用的算術函式及含義如下表所示:

舉一些簡單的例子:
SELECT ABS(-2),執行結果為 2。
SELECT MOD(101,3),執行結果 2。
SELECT ROUND(37.25,1),執行結果 37.3。
字串函式
常用的字串函式操作包括了字串拼接,大小寫轉換,求長度以及字串替換和擷取等。具體的函式名稱及含義如下表所示:
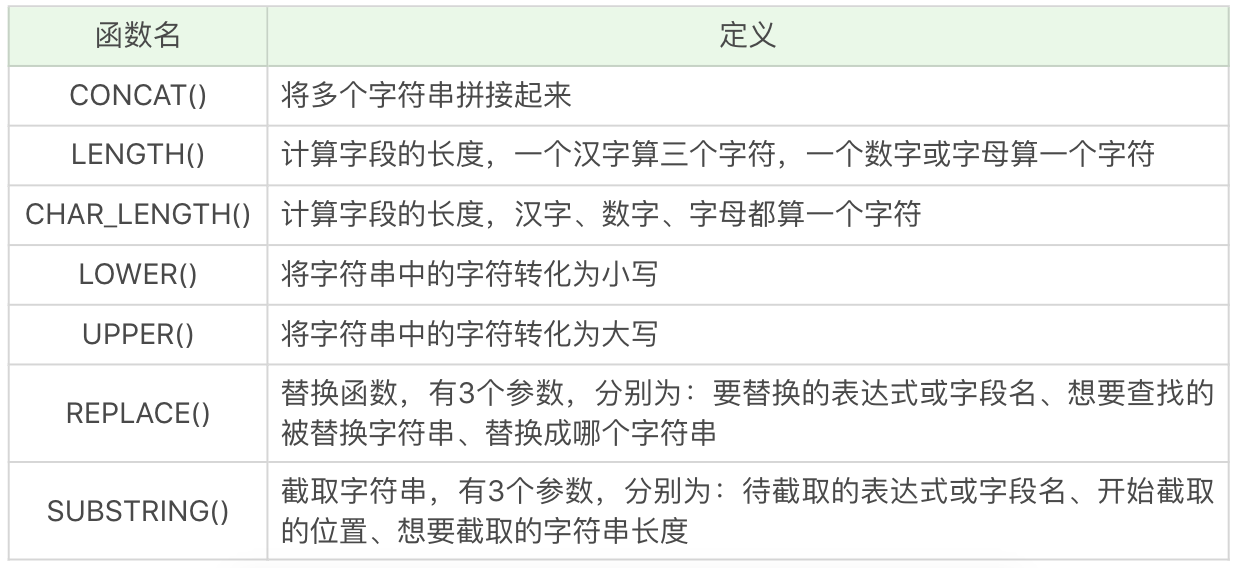
同樣有一些簡單的例子:
SELECT CONCAT('abc', 123),執行結果為 abc123。
SELECT LENGTH('你好'),執行結果為 6。
SELECT CHAR_LENGTH('你好'),執行結果為 2。
SELECT LOWER('ABC'),執行結果為 abc。
SELECT UPPER('abc'),執行結果 ABC。
SELECT REPLACE('fabcd', 'abc', 123),執行結果為 f123d。
SELECT SUBSTRING('fabcd', 1,3),執行結果為 fab。
日期函式
日期函式是對資料表中的日期進行處理,常用的函式包括:
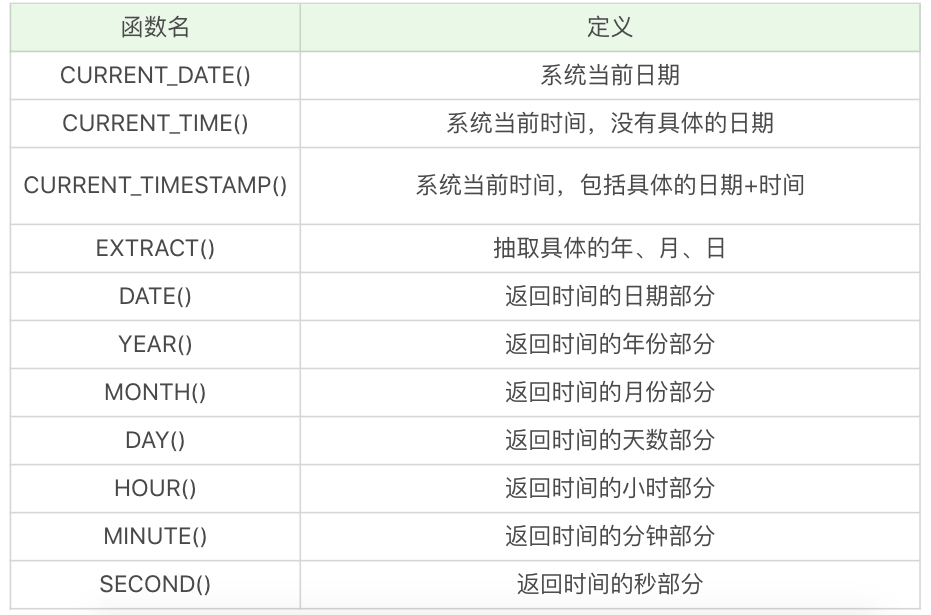
下面是一些簡單的例子:
SELECT CURRENT_DATE(),執行結果為 2019-04-03。
SELECT CURRENT_TIME(),執行結果為 21:26:34。
SELECT CURRENT_TIMESTAMP(),執行結果為 2019-04-03 21:26:34。
SELECT EXTRACT(YEAR FROM '2019-04-03'),執行結果為 2019。
SELECT DATE('2019-04-01 12:00:05'),執行結果為 2019-04-01。
這裡需要注意的是,DATE 日期格式必須是 yyyy-mm-dd 的形式。如果要進行日期比較,就要使用 DATE 函式,不要直接使用日期與字串進行比較,我會在後面的例子中講具體的原因。
轉換函式
轉換函式可以轉換資料之間的型別,常用的函式如下表所示:

實踐
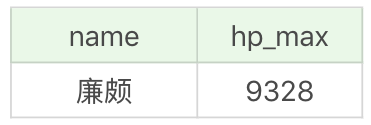
假設我們想顯示英雄最大生命值的最大值,就需要用到 MAX 函式。在資料中,“最大生命值”對應的列數為hp_max,在程式碼中的格式為MAX(hp_max)。
SQL:SELECT MAX(hp_max) FROM heros
執行結果為 9328。
假如我們想要知道最大生命值最大的是哪個英雄,以及對應的數值,就需要分成兩個步驟來處理:首先找到英雄的最大生命值的最大值,即SELECT MAX(hp_max) FROM heros,然後再篩選最大生命值等於這個最大值的英雄,如下所示。
SQL:SELECT name, hp_max FROM heros WHERE hp_max = (SELECT MAX(hp_max) FROM heros)
執行結果:
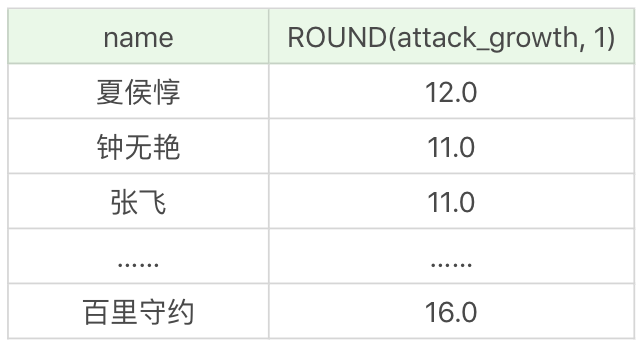
假如我們想顯示英雄的名字,以及他們的名字字數,需要用到CHAR_LENGTH函式。
SQL:SELECT CHAR_LENGTH(name), name FROM heros
執行結果為:
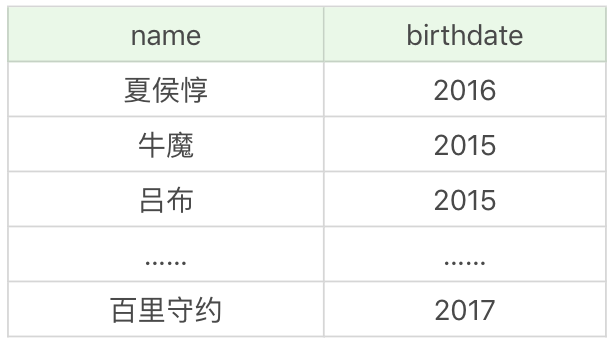
假如想要提取英雄上線日期(對應欄位 birthdate)的年份,只顯示有上線日期的英雄即可(有些英雄沒有上線日期的資料,不需要顯示),這裡我們需要使用 EXTRACT 函式,提取某一個時間元素。所以我們需要篩選上線日期不為空的英雄,即WHERE birthdate is not null,然後再顯示他們的名字和上線日期的年份,即:
SQL: SELECT name, EXTRACT(YEAR FROM birthdate) AS birthdate FROM heros WHERE birthdate is NOT NULL
或者使用如下形式:
SQL: SELECT name, YEAR(birthdate) AS birthdate FROM heros WHERE birthdate is NOT NULL
執行結果為:
假設我們需要找出在 2016 年 10 月 1 日之後上線的所有英雄。這裡我們可以採用 DATE 函式來判斷 birthdate 的日期是否大於 2016-10-01,即WHERE DATE(birthdate)>'2016-10-01',然後再顯示符合要求的全部欄位資訊,即:
SQL: SELECT * FROM heros WHERE DATE(birthdate)>'2016-10-01'
需要注意的是下面這種寫法是不安全的:
SELECT * FROM heros WHERE birthdate>'2016-10-01'
因為很多時候你無法確認 birthdate 的資料型別是字串,還是 datetime 型別,如果你想對日期部分進行比較,那麼使用DATE(birthdate)來進行比較是更安全的。
執行結果為:

假設我們需要知道在 2016 年 10 月 1 日之後上線英雄的平均最大生命值、平均最大法力和最高物攻最大值。同樣我們需要先篩選日期條件,即WHERE DATE(birthdate)>'2016-10-01',然後再選擇AVG(hp_max), AVG(mp_max), MAX(attack_max)欄位進行顯示。
SQL: SELECT AVG(hp_max), AVG(mp_max), MAX(attack_max) FROM heros WHERE DATE(birthdate)>'2016-10-01'
執行結果為:

為什麼使用 SQL 函式會帶來問題
儘管 SQL 函式使用起來會很方便,但我們使用的時候還是要謹慎,因為你使用的函式很可能在執行環境中無法工作,這是為什麼呢?
如果你學習過程式語言,就會知道語言是有不同版本的,比如 Python 會有 2.7 版本和 3.x 版本,不過它們之間的函式差異不大,也就在 10% 左右。但我們在使用 SQL 語言的時候,不是直接和這門語言打交道,而是通過它使用不同的資料庫軟體,即 DBMS。DBMS 之間的差異性很大,遠大於同一個語言不同版本之間的差異。實際上,只有很少的函式是被 DBMS 同時支援的。比如,大多數 DBMS 使用(||)或者(+)來做拼接符,而在 MySQL 中的字串拼接函式為Concat()。大部分 DBMS 會有自己特定的函式,這就意味著採用 SQL 函式的程式碼可移植性是很差的,因此在使用函式的時候需要特別注意。
關於大小寫的規範
實際上在 SQL 中,關鍵字和函式名是不用區分字母大小寫的,比如 SELECT、WHERE、ORDER、GROUP BY 等關鍵字,以及 ABS、MOD、ROUND、MAX 等函式名。
不過在 SQL 中,你是要確定大小寫的規範,因為在 Linux 和 Windows 環境下,你可能會遇到不同的大小寫問題。
比如 MySQL 在 Linux 的環境下,資料庫名、表名、變數名是嚴格區分大小寫的,而欄位名是忽略大小寫的。
而 MySQL 在 Windows 的環境下全部不區分大小寫。
這就意味著如果你的變數名命名規範沒有統一,就可能產生錯誤。這裡有一個有關命名規範的建議:
- 關鍵字和函式名稱全部大寫;
- 資料庫名、表名、欄位名稱全部小寫;
- SQL 語句必須以分號結尾。
雖然關鍵字和函式名稱在 SQL 中不區分大小寫,也就是如果小寫的話同樣可以執行,但是資料庫名、表名和欄位名在 Linux MySQL 環境下是區分大小寫的,因此建議你統一這些欄位的命名規則,比如全部採用小寫的方式。同時將關鍵詞和函式名稱全部大寫,以便於區分資料庫名、表名、欄位名。
總結
函式對於一門語言的重要性毋庸置疑,我們在寫 Python 程式碼的時候,會自己編寫函式,也會使用 Python 內建的函式。在 SQL 中,使用函式的時候需要格外留意。不過如果工程量不大,使用的是同一個 DBMS 的話,還是可以使用函式簡化操作的,這樣也能提高程式碼效率。只是在系統整合,或者在多個 DBMS 同時存在的情況下,使用函式的時候就需要慎重一些。
比如CONCAT()是字串拼接函式,在 MySQL 和 Oracle 中都有這個函式,但是在這兩個 DBMS 中作用卻不一樣,CONCAT函式在 MySQL 中可以連線多個字串,而在 Oracle 中CONCAT函式只能連線兩個字串,如果要連線多個字串就需要用(||)連字元來解決。
SQL的聚集函式
聚集函式是對一組資料進行彙總的函式,輸入的是一組資料的集合,輸出的是單個值。通常我們可以利用聚集函式彙總表的資料,如果稍微複雜一些,我們還需要先對資料做篩選,然後再進行聚集,比如先按照某個條件進行分組,對分組條件進行篩選,然後得到篩選後的分組的彙總資訊。
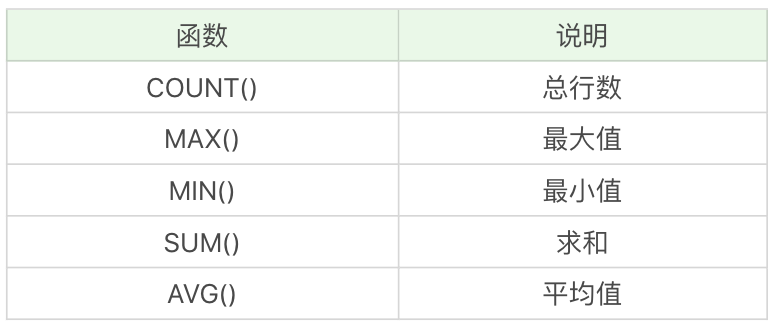
聚集函式都有哪些
SQL 中的聚集函式一共包括 5 個,可以幫我們求某列的最大值、最小值和平均值等,它們分別是:
這些函式你可能已經接觸過,我們再來簡單複習一遍。我們繼續使用 heros 資料表,對王者榮耀的英雄資料進行聚合。
如果我們想要查詢最大生命值大於 6000 的英雄數量。
SQL:SELECT COUNT(*) FROM heros WHERE hp_max > 6000
執行結果為 41。
如果想要查詢最大生命值大於 6000,且有次要定位的英雄數量,需要使用 COUNT 函式。
SQL:SELECT COUNT(role_assist) FROM heros WHERE hp_max > 6000
執行結果是 23。
需要