
YARN的資源排程
一、YARN 概述
YARN 是一個資源排程平臺,負責為運算程式提供伺服器運算資源,相當於一個分散式的操 作系統平臺,而 MapReduce 等運算程式則相當於運行於作業系統之上的應用程式
YARN 是 Hadoop2.x 版本中的一個新特性。它的出現其實是為了解決第一代 MapReduce 程式設計 框架的不足,提高叢集環境下的資源利用率,這些資源包括記憶體,磁碟,網路,IO等。Hadoop2.X 版本中重新設計的這個 YARN 叢集,具有更好的擴充套件性,可用性,可靠性,向後相容性,以 及能支援除 MapReduce 以外的更多分散式計算程式
1、YARN 並不清楚使用者提交的程式的執行機制
2、YARN 只提供運算資源的排程(使用者程式向 YARN 申請資源,YARN 就負責分配資源)
3、YARN 中的主管角色叫 ResourceManager
4、YARN 中具體提供運算資源的角色叫 NodeManager
5、這樣一來,YARN 其實就與執行的使用者程式完全解耦,就意味著 YARN 上可以執行各種類 型的分散式運算程式(MapReduce 只是其中的一種),比如 MapReduce、Storm 程式,Spark 程式,Tez ……
6、所以,Spark、Storm 等運算框架都可以整合在 YARN 上執行,只要他們各自的框架中有 符合 YARN 規範的資源請求機制即可
7、yarn 就成為一個通用的資源排程平臺,從此,企業中以前存在的各種運算叢集都可以整 合在一個物理叢集上,提高資源利用率,方便資料共享
二、原 MR框架的不足
1、JobTracker 是叢集事務的集中處理點,存在單點故障
2、JobTracker 需要完成的任務太多,既要維護 job 的狀態又要維護 job 的 task 的狀態,造成 過多的資源消耗
3、在 TaskTracker 端,用 Map/Reduce Task 作為資源的表示過於簡單,沒有考慮到 CPU、內 存等資源情況,當把兩個需要消耗大記憶體的 Task 排程到一起,很容易出現 OOM
4、把資源強制劃分為 Map/Reduce Slot,當只有 MapTask 時,TeduceSlot 不能用;當只有 Reduce Task 時,MapSlot 不能用,容易造成資源利用不足。
總結起來就是:
1、擴充套件性差
2、可靠性低
3、資源利用率低
4、不支援多種計算框架
三、新版 YARN 架構的優點
YARN/MRv2 最基本的想法是將原 JobTracker 主要的資源管理和 Job 排程/監視功能分開作為 兩個單獨的守護程序。有一個全域性的 ResourceManager(RM)和每個 Application 有一個 ApplicationMaster(AM),Application 相當於 MapReduce Job 或者 DAG jobs。ResourceManager 和 NodeManager(NM)組成了基本的資料計算框架。ResourceManager 協調叢集的資源利用, 任何 Client 或者執行著的 applicatitonMaster 想要執行 Job 或者 Task 都得向 RM 申請一定的資 源。ApplicatonMaster 是一個框架特殊的庫,對於 MapReduce 框架而言有它自己的 AM 實現, 使用者也可以實現自己的 AM,在執行的時候,AM 會與 NM 一起來啟動和監視 Tasks。
四、Yarn基本架構
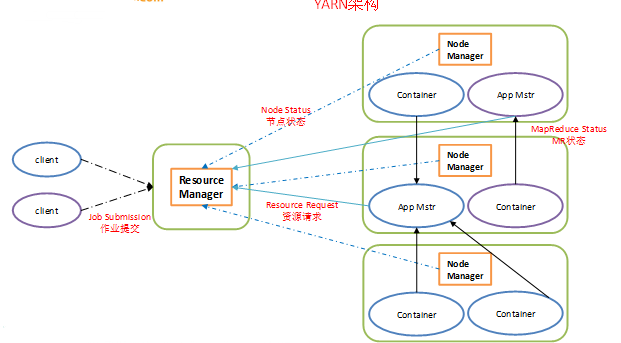
從YARN的架構圖來看,它主要由ResourceManager、NodeManager、ApplicationMaster和Container等以下幾個元件構成。
1)ResourceManager(RM)
YARN分層結構的本質是ResourceManager。這個實體控制整個叢集並管理應用程式向基礎計算資源的分配。ResourceManager將各個資源部分(計算、記憶體、頻寬等)精心安排給基礎NodeManager(YARN的每節點代理)。ResourceManager還與ApplicationMaster一起分配資源,與NodeManager一起啟動和監視它們的基礎應用程式。在此上下文中,ApplicationMaster承擔了以前的TaskTracker的一些角色,ResourceManager承擔了JobTracker 的角色。
總的來說,RM有以下作用
(1)處理客戶端請求
(2)啟動或監控ApplicationMaster
(3)監控NodeManager
(4)資源的分配與排程
2)ApplicationMaster(AM)
ApplicationMaster管理在YARN內執行的每個應用程式例項。ApplicationMaster負責協調來自ResourceManager的資源,並通過NodeManager監視容器的執行和資源使用(CPU、記憶體等的資源分配)。請注意,儘管目前的資源更加傳統(CPU 核心、記憶體),但未來會帶來基於手頭任務的新資源型別(比如圖形處理單元或專用處理裝置)。從YARN角度講,ApplicationMaster是使用者程式碼,因此存在潛在的安全問題。YARN假設ApplicationMaster存在錯誤或者甚至是惡意的,因此將它們當作無特權的程式碼對待。
總的來說,AM有以下作用
(1)負責資料的切分
(2)為應用程式申請資源並分配給內部的任務
(3)任務的監控與容錯
3)NodeManager(NM)
NodeManager管理YARN叢集中的每個節點。NodeManager提供針對叢集中每個節點的服務,從監督對一個容器的終生管理到監視資源和跟蹤節點健康。MRv1通過插槽管理Map 和Reduce任務的執行,而NodeManager管理抽象容器,這些容器代表著可供一個特定應用程式使用的針對每個節點的資源。
總的來說,NM有以下作用
(1)管理單個節點上的資源
(2)處理來自ResourceManager的命令
(3)處理來自ApplicationMaster的命令
4)Container
Container是YARN中的資源抽象,它封裝了某個節點上的多維度資源,如記憶體、CPU、磁碟、網路等,當AM向RM申請資源時,RM為AM返回的資源便是用Container表示的。YARN會為每個任務分配一個Container,且該任務只能使用該Container中描述的資源。
總的來說,Container有以下作用
對任務執行環境進行抽象,封裝CPU、記憶體等多維度的資源以及環境變數、啟動命令等任務執行相關的資訊
要使用一個YARN叢集,首先需要一個包含應用程式的客戶的請求。ResourceManager協商一個容器的必要資源,啟動一個ApplicationMaster來表示已提交的應用程式。通過使用一個資源請求協議,ApplicationMaster協商每個節點上供應用程式使用的資源容器。執行應用程式時,ApplicationMaster監視容器直到完成。當應用程式完成時,ApplicationMaster從 ResourceManager登出其容器,執行週期就完成了。
通過上面的講解,應該明確的一點是,舊的Hadoop架構受到了JobTracker的高度約束,JobTracker負責整個叢集的資源管理和作業排程。新的YARN架構打破了這種模型,允許一個新ResourceManager管理跨應用程式的資源使用,ApplicationMaster負責管理作業的執行。這一更改消除了一處瓶頸,還改善了將Hadoop叢集擴充套件到比以前大得多的配置的能力。此外,不同於傳統的MapReduce,YARN允許使用MPI( Message Passing Interface) 等標準通訊模式,同時執行各種不同的程式設計模型,包括圖形處理、迭代式處理、機器學習和一般叢集計算。
五、Yarn工作機制
1)Yarn執行機制
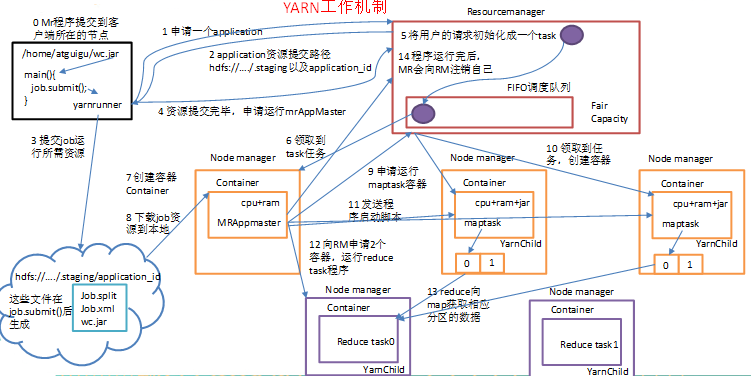
2)工作機制詳解
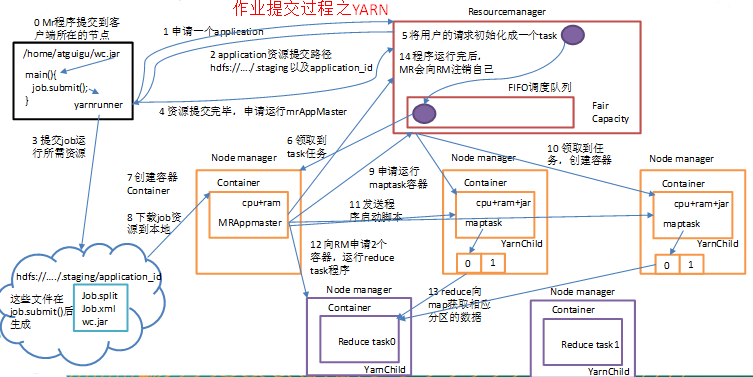
(0)Mr程式提交到客戶端所在的節點
(1)Yarnrunner向Resourcemanager申請一個Application。
(2)rm將該應用程式的資源路徑返回給yarnrunner
(3)該程式將執行所需資源提交到HDFS上
(4)程式資源提交完畢後,申請執行mrAppMaster
(5)RM將使用者的請求初始化成一個task
(6)其中一個NodeManager領取到task任務。
(7)該NodeManager建立容器Container,併產生MRAppmaster
(8)Container從HDFS上拷貝資源到本地
(9)MRAppmaster向RM 申請執行maptask容器
(10)RM將執行maptask任務分配給另外兩個NodeManager,另兩個NodeManager分別領取任務並建立容器。
(11)MR向兩個接收到任務的NodeManager傳送程式啟動指令碼,這兩個NodeManager分別啟動maptask,maptask對資料分割槽排序。
(12)MRAppmaster向RM申請2個容器,執行reduce task。
(13)reduce task向maptask獲取相應分割槽的資料。
(14)程式執行完畢後,MR會向RM登出自己。
六、資源排程器
目前,Hadoop作業排程器主要有三種:FIFO、Capacity Scheduler和Fair Scheduler。Hadoop2.7.2預設的資源排程器是Capacity Scheduler。
具體設定詳見:yarn-default.xml檔案
| <property> <description>The class to use as the resource scheduler.</description> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value> </property> |
1)先進先出排程器(FIFO)
FIFO是Hadoop中預設的排程器,也是一種批處理排程器。它先按照作業的優先順序高低,再按照到達時間的先後選擇被執行的作業。原理圖如下所示。
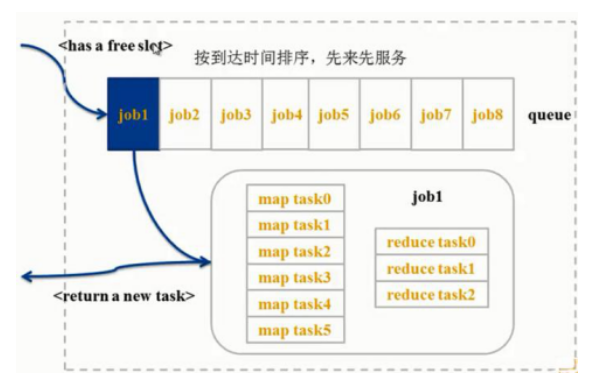
比如,一個TaskTracker正好有一個空閒的slot,此時FIFO排程器的佇列已經排好序,就選擇排在最前面的任務job1,job1包含很多map task和reduce task。假如空閒資源是map slot,我們就選擇job1中的map task。假如map task0要處理的資料正好儲存在該TaskTracker 節點上,根據資料的本地性,排程器把map task0分配給該TaskTracker。FIFO 排程器整體就是這樣一個過程。
2)容量排程器(Capacity Scheduler)
支援多個佇列,每個佇列可配置一定的資源量,每個佇列採用FIFO排程策略,為了防止同一個使用者的作業獨佔佇列中的資源,該排程器會對同一使用者提交的作業所佔資源量進行限定。排程時,首先按以下策略選擇一個合適佇列:計算每個佇列中正在執行的任務數與其應該分得的計算資源之間的比值,選擇一個該比值最小的佇列;然後按以下策略選擇該佇列中一個作業:按照作業優先順序和提交時間順序選擇,同時考慮使用者資源量限制和記憶體限制。 原理圖如下所示。

比如我們分為三個佇列:queueA、queueB和queueC,每個佇列的 job 按照到達時間排序。假如這裡有100個slot,queueA分配20%的資源,可配置最多執行15個task,queueB 分配50%的資源,可配置最多執行25個task,queueC分配30%的資源,可配置最多執行25個task。這三個佇列同時按照任務的先後順序依次執行,比如,job11、job21和job31分別排在佇列最前面,是最先執行,也是同時執行。
3)公平排程器(Fair Scheduler)
同計算能力排程器類似,支援多佇列多使用者,每個佇列中的資源量可以配置,同一佇列中的作業公平共享佇列中所有資源。原理圖如下所示
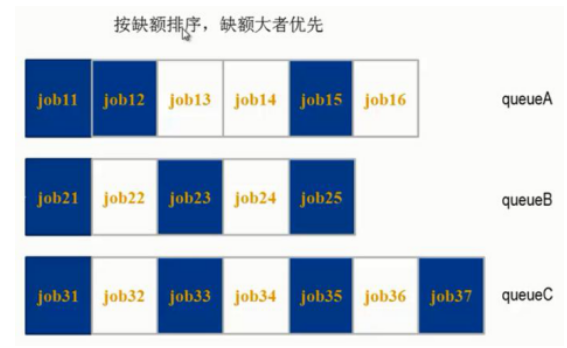
比如有三個佇列:queueA、queueB和queueC,每個佇列中的 job 按照優先順序分配資源,優先順序越高分配的資源越多,但是每個 job 都會分配到資源以確保公平。在資源有限的情況下,每個 job 理想情況下獲得的計算資源與實際獲得的計算資源存在一種差距, 這個差距就叫做缺額。在同一個佇列中,job的資源缺額越大,越先獲得資源優先執行。作業是按照缺額的高低來先後執行的,而且可以看到上圖有多個作業同時執行。
七、作業提交全過程
1)作業提交過程之YARN
2)作業提交過程之MapReduce
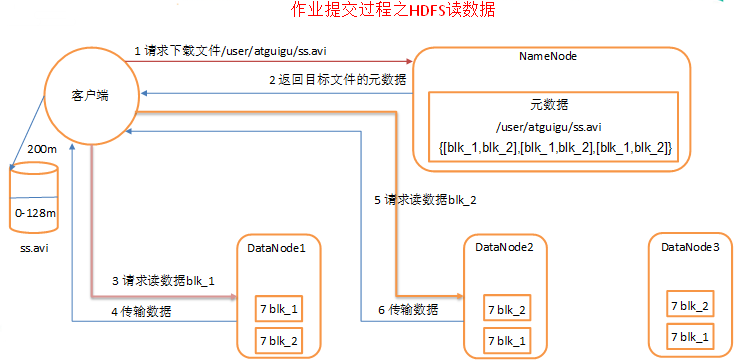
3)作業提交過程之讀資料
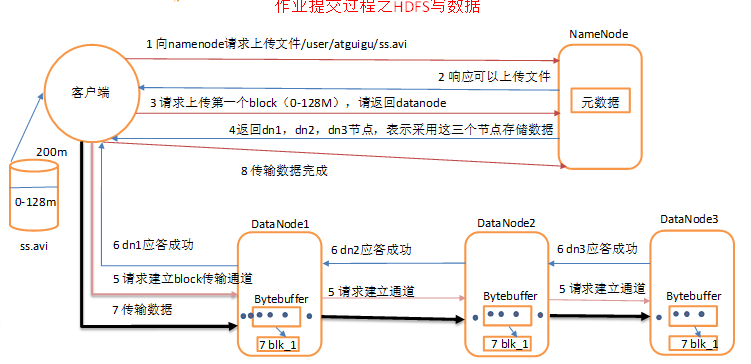
4)作業提交過程之寫資料
5)作業提交詳解
(1)作業提交
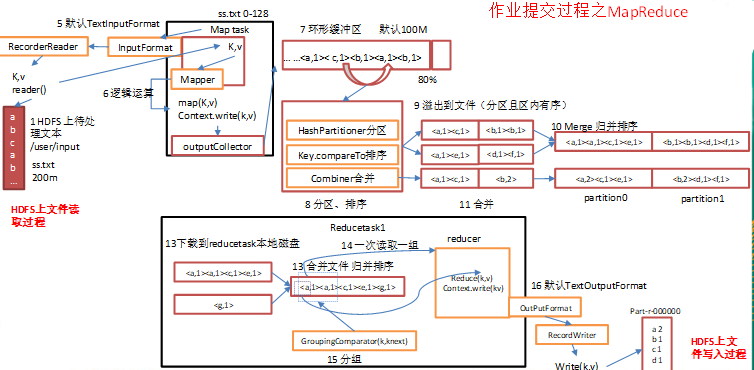
client呼叫job.waitForCompletion方法,向整個叢集提交MapReduce作業 (第1步) 。 新的作業ID(應用ID)由資源管理器分配(第2步)。作業的client核實作業的輸出, 計算輸入的split, 將作業的資源(包括Jar包, 配置檔案, split資訊)拷貝給HDFS(第3步)。最後, 通過呼叫資源管理器的submitApplication()來提交作業(第4步)。
(2)作業初始化
當資源管理器收到submitApplciation()的請求時, 就將該請求發給排程器(scheduler), 排程器分配container, 然後資源管理器在該container內啟動應用管理器程序, 由節點管理器監控(第5步)。
MapReduce作業的應用管理器是一個主類為MRAppMaster的Java應用。其通過創造一些bookkeeping物件來監控作業的進度, 得到任務的進度和完成報告(第6步)。然後其通過分散式檔案系統得到由客戶端計算好的輸入split(第7步)。然後為每個輸入split建立一個map任務, 根據mapreduce.job.reduces建立reduce任務物件。
(3)任務分配
如果作業很小, 應用管理器會選擇在其自己的JVM中執行任務。
如果不是小作業, 那麼應用管理器向資源管理器請求container來執行所有的map和reduce任務(第8步)。這些請求是通過心跳來傳輸的, 包括每個map任務的資料位置, 比如存放輸入split的主機名和機架(rack)。排程器利用這些資訊來排程任務, 儘量將任務分配給儲存資料的節點, 或者分配給和存放輸入split的節點相同機架的節點。
(4)任務執行
當一個任務由資源管理器的排程器分配給一個container後, 應用管理器通過聯絡節點管理器來啟動container(第9步)。任務由一個主類為YarnChild的Java應用執行。在執行任務之前首先本地化任務需要的資源, 比如作業配置, JAR檔案, 以及分散式快取的所有檔案(第10步)。最後, 執行map或reduce任務(第11步)。
YarnChild執行在一個專用的JVM中, 但是YARN不支援JVM重用。
(5)進度和狀態更新
YARN中的任務將其進度和狀態(包括counter)返回給應用管理器, 客戶端每秒(通過mapreduce.client.progressmonitor.pollinterval設定)嚮應用管理器請求進度更新, 展示給使用者。
(6)作業完成
除了嚮應用管理器請求作業進度外, 客戶端每5分鐘都會通過呼叫waitForCompletion()來檢查作業是否完成。時間間隔可以通過mapreduce.client.completion.pollinterval來設定。作業完成之後, 應用管理器和container會清理工作狀態, OutputCommiter的作業清理方法也會被呼叫。作業的資訊會被作業歷史伺服器儲存以備之後使用者核查。
八、任務的推測執行
1)作業完成時間取決於最慢的任務完成時間
一個作業由若干個Map任務和Reduce任務構成。因硬體老化、軟體Bug等,某些任務可能執行非常慢。
典型案例:系統中有99%的Map任務都完成了,只有少數幾個Map老是進度很慢,完不成,怎麼辦?
2)推測執行機制:
發現拖後腿的任務,比如某個任務執行速度遠慢於任務平均速度。為拖後腿任務啟動一個備份任務,同時執行。誰先執行完,則採用誰的結果。
3)執行推測任務的前提條件
(1)每個task只能有一個備份任務;
(2)當前job已完成的task必須不小於0.05(5%)
(3)開啟推測執行引數設定。Hadoop2.7.2 mapred-site.xml檔案中預設是開啟的。
| <property> <name>mapreduce.map.speculative</name> <value>true</value> <description>If true, then multiple instances of some map tasks may be executed in parallel.</description> </property>
<property> <name>mapreduce.reduce.speculative</name> <value>true</value> <description>If true, then multiple instances of some reduce tasks may be executed in parallel.</description> </property> |
4)不能啟用推測執行機制情況
(1)任務間存在嚴重的負載傾斜;
(2)特殊任務,比如任務向資料庫中寫資料。
5)演算法原理:
假設某一時刻,任務T的執行進度為progress,則可通過一定的演算法推測出該任務的最終完成時刻estimateEndTime。另一方面,如果此刻為該任務啟動一個備份任務,則可推斷出它可能的完成時刻estimateEndTime`,於是可得出以下幾個公式:
estimateEndTime=estimatedRunTime+taskStartTime
estimatedRunTime=(currentTimestamp-taskStartTime)/progress
estimateEndTime`= currentTimestamp+averageRunTime
其中,
currentTimestamp為當前時刻;
taskStartTime為該任務的啟動時刻;
averageRunTime為已經成功執行完成的任務的平均執行時間;
progress是任務執行的比例(0.1-1);
這樣,MRv2總是選擇(estimateEndTime- estimateEndTime·)差值最大的任務,併為之啟動備份任務。為了防止大量任務同時啟動備份任務造成的資源浪費,MRv2為每個作業設定了同時啟動的備份任務數目上限。
推測執行機制實際上採用了經典的優化演算法:以空間換時間,它同時啟動多個相同任務處理相同的資料,並讓這些任務競爭以縮短資料處理時間。顯然,這種方法需要佔用更多的計算資源。在叢集資源緊缺的情況下,應合理使用該機制,爭取在多用少量資源的情況下,減少作業的計算時間。