
資源排程框架YARN
一.產生背景
Hadoop1.0的時候是沒有YARN,MapReduce1.X存在的問題:單點故障&節點壓力大不易擴充套件
JobTracker:負責資源管理和作業排程
TaskTracker:定期向JobTracker彙報本節點的健康狀況、資源使用情況以及作業執行情況;
接收來自JobTracker的命令,例如啟動任務或結束任務等。
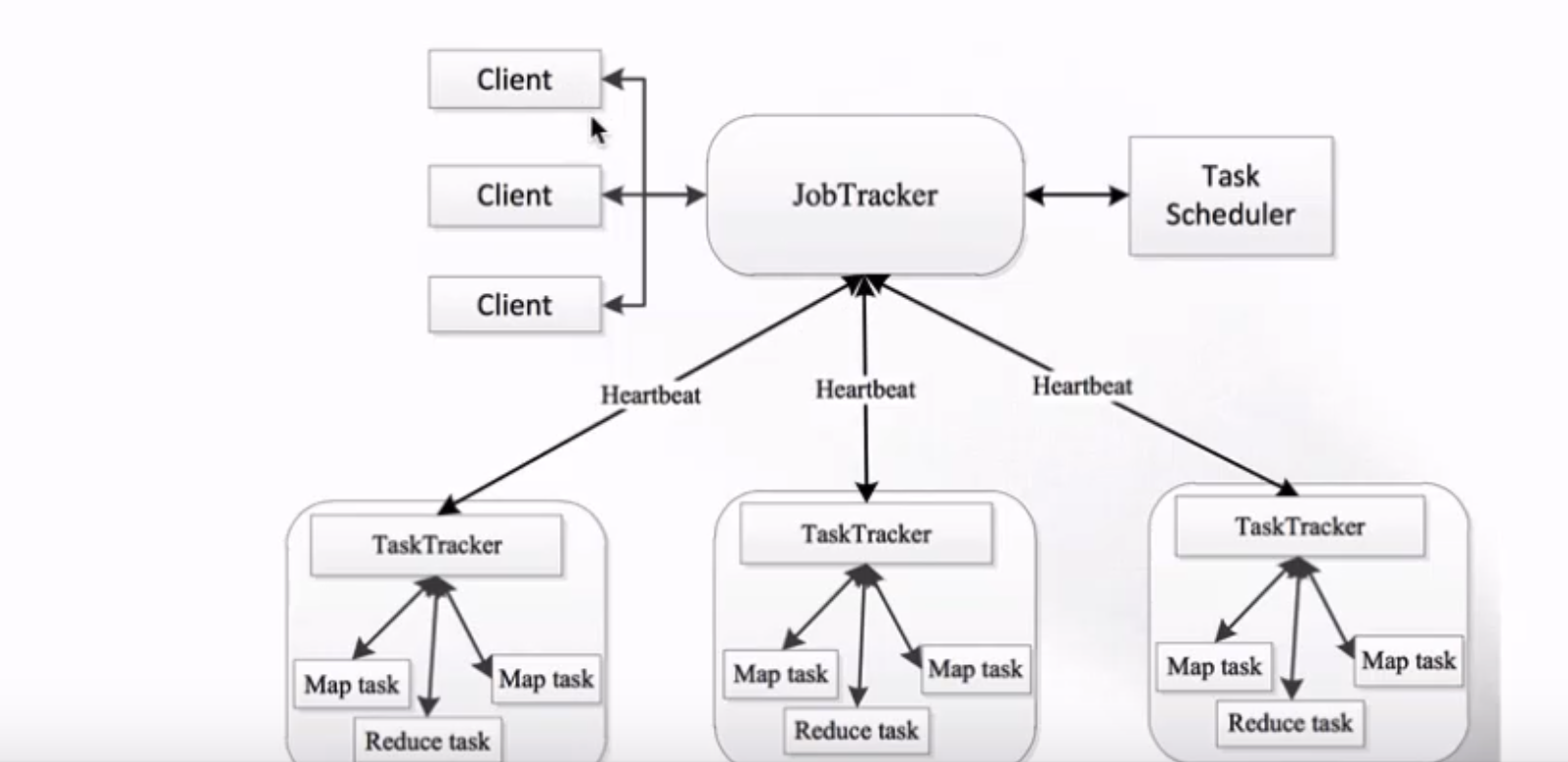
這種架構的缺點也很明顯
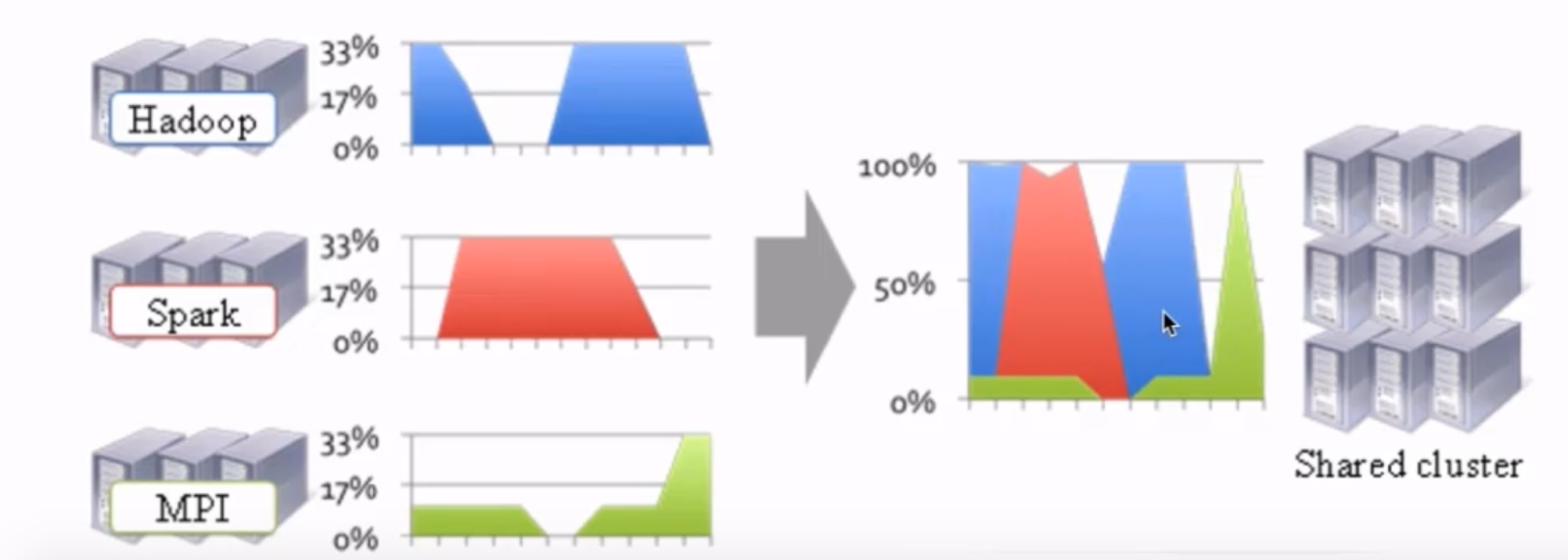
上圖可以看到,Hadoop叢集在忙的時候Spark就比較閒,Spark叢集比較忙的時候Hadoop叢集就比較閒,而MPI叢集則是整體並不是很忙。這樣就無法高效的利用資源,因為這些不同的叢集無法互相使用資源。
而YARN就可以令這些不同的框架執行在同一個叢集上,併為它們排程資源。
XXX on YARN:與其他計算框架共享叢集資源,按資源需要分配,進而提高叢集資源的利用率。
XXX:Spark/MapReduce/Storm/Flink
二.YARN架構
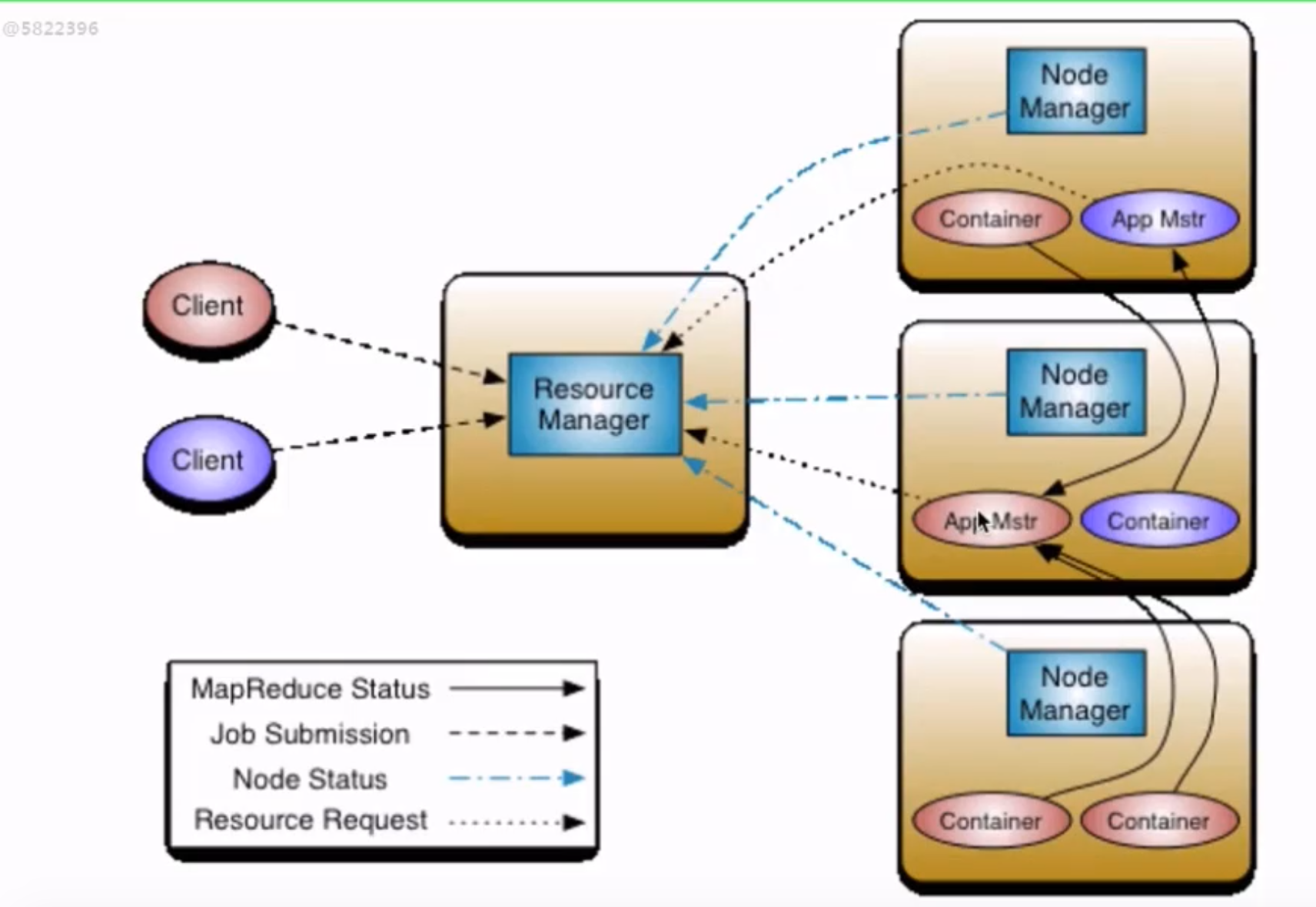
1 ResourceMananger:RM
整個叢集提供服務的RM只有一個(生產中有兩個,一個主,一個備),負責叢集資源的統一管理和排程。
處理客戶端的請求:提交一個作業、殺死一個作業。
監控NM,一旦某個NM掛了,那麼該NM上執行的任務需要告訴AM如何進行處理。
2 NodeManager:NM
整個叢集中有多個,負責自己本身節點資源管理和使用。
定時向RM彙報本節點的資源使用情況。
接收並處理來自RM的各種命令:啟動Container等。
處理來自AM的命令。
單個節點的資源管理。
3 ApplicationMaster:AM
每一個應用程式對應一個:MR、Spark,負責應用程式的管理。
為每個應用程式向RM申請資源(core、memory),分配給內部task。
需要與NM通訊:啟動/停止task,task是執行在Container裡面,AM也是執行在Container裡面。
4 Container
封裝了CPU、Memory等資源的一個容器
是一個任務執行環境的抽象。
5 Client
提交作業。
查詢作業的執行進度。
殺死作業。
三.環境配置
1 yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
2 mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3 啟動YARN相關的程序
sbin/start-yarn.sh
4 驗證
jps
ResourceManager
NodeManager
http://192.168.56.102:8088/
5 停止YARN相關的程序
sbin/stop-yarn.sh