
hive collect_list和collect_set區別
Hive中collect相關的函式有collect_list和collect_set。
它們都是將分組中的某列轉為一個數組返回,不同的是collect_list不去重而collect_set去重。
做簡單的實驗加深理解,建立一張實驗用表,存放使用者每天點播視訊的記錄:
| 1 2 3 4 5 |
by (day string)
|
在本地檔案系統建立測試資料檔案:
| 1 2 3 4 5 6 7 8 |
|
將資料載入到Hive表:
| 1 |
t_visit_video partition (day='20180516'); |
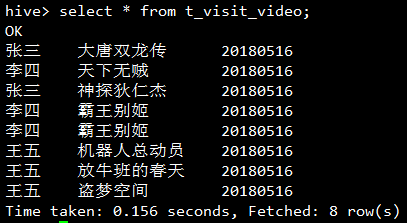
按使用者分組,取出每個使用者每天看過的所有視訊的名字:
| 1 |
|

但是上面的查詢結果有點問題,因為霸王別姬實在太好看了,所以李四這傢伙看了兩遍,這直接就導致得到的觀看過視訊列表有重複的,所以應該增加去重,使用collect_set,其與collect_list的區別就是會去重:
| 1 |
|

李四的觀看記錄中霸王別姬只出現了一次,實現了去重效果。
突破group by限制
還可以利用collect來突破group by的限制,Hive中在group by查詢的時候要求出現在select後面的列都必須是出現在group by後面的,即select列必須是作為分組依據的列,但是有的時候我們想根據A進行分組然後隨便取出每個分組中的一個B,代入到這個實驗中就是按照使用者進行分組,然後隨便拿出一個他看過的視訊名稱即可:
| 1 |
|

video_name不是分組列,依然能夠取出這列中的資料。